前言
最终定位到的结果比较蠢,巨佬可以直接查看结果,本文只为记录寻找该bug时使用的方法而生。
本人平日维护一个公司运营平台的一个配置库,由于降级措施比较好,而且公司容器实例也比较多,所以在爆发错误的时候并未及时跟进。该问题应该从该服务出生开始就已经有了,一直没有爆发的原因应该是因为以前迭代得比较多,一周也差不多会发布四到五次,再加上平台在去年使用人数还是比较少的,后面逐渐成为公司一个中流砥柱的产品,被许多部门所使用,所以问题就爆发了。
第一次猜想
“这服务怎么协程突然暴涨了”
第一次协程暴涨的时候,发现有一台实例突然就跪了,协程数疯狂暴涨,内存也疯狂暴涨,第一反应是db出现了慢查询,但是实际上。而查看监控,并没有特别多接口跪,如图。
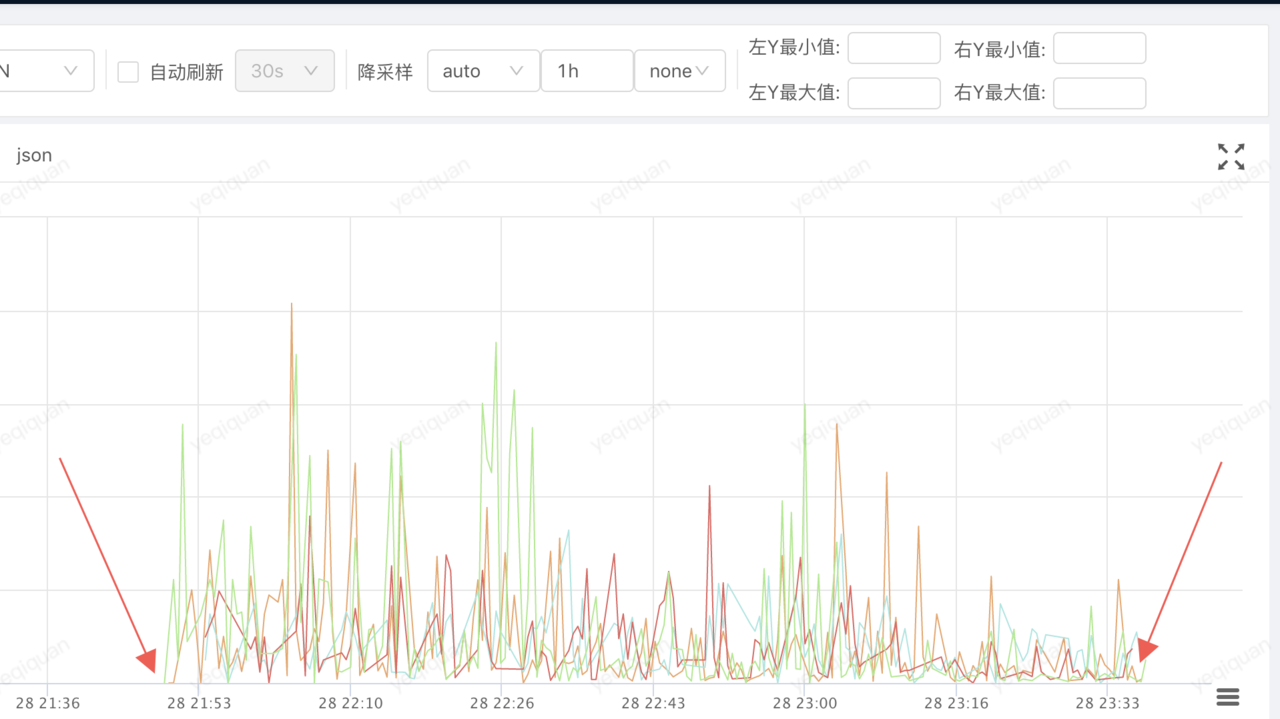
而实际上能很明显看到有几个实例的协程数直线上涨。
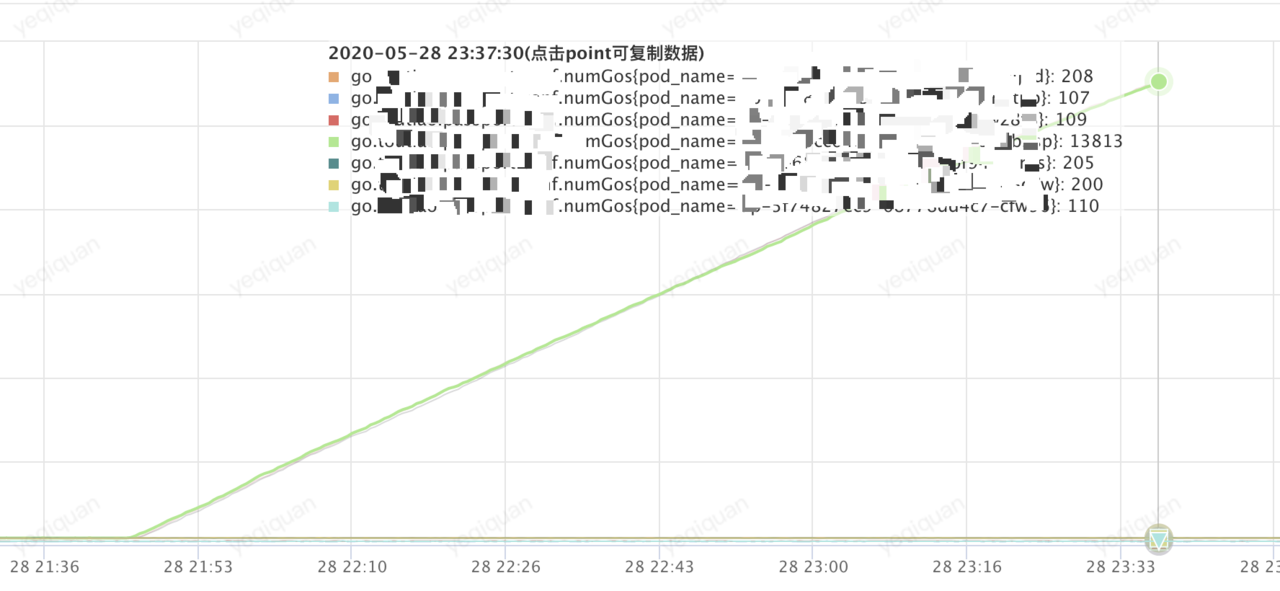
其实因为服务设计原因,没有那么多接口跪是符合预期的,因为其他接口都做了内存全表缓存,至于为什么做内存全表缓存就后面再说吧。通过pprof定位,很容易就发现那几个跪了的接口都有一个共同点,协程泄露。
此时扫了一眼代码,那几个接口除了没有做缓存,其他实现都蛮合理的,因为怀疑是慢查询了,所以尝试去扫了一下表,大概最长耗时接近1s,该表数据也差不多到了3w多数据了,所以认为是因为扫这个表导致线程被占用,而当多台机子都并发读该接口时因为慢查询给堵住,没有超时设置所以获取协程的吞吐量不成比了。
所以就溜下去给这个接口做了内存缓存,暂时缓解了两三个星期,但是几周过后又出现了协程泄露,不得而解。。
第二次猜想
再次出现协程泄露时,没什么其他手段去排查了,只能干读代码,不是因为读库的原因,那是因为什么呢?
产生了这个想法的我,看向了写操作的代码,有没有可能是因为读写没分离,写超时了导致出现这个问题呢。
因为再次出现协程泄露的时间很奇特,在半夜四点,突然给电话打醒。所以突发奇想,跟同事去查了一下当天凌晨4点平台的操作,发现确实,有一个人在晚上4点的时候申请了一个东西,写了库,时间恰好吻合。
所以确实是因为写数据的问题了,于是我又去扫了一眼代码,发现整个库表都是读主库的,从库从来不用,emmmmmm。于是就给服务做了一次读写分离,做起来也不复杂。
不出所望过了两周,问题又爆发了。。
第三次猜想
首先,我在质疑代码里的timeout真的是奏效的吗,为什么明明设置了超时时间还会超时,而且不单只只有代码通过框架设置了超时,db平台也设置了超时,按道理来说应该会kill掉的。不会是某个时刻操作比较多库比较渣所以就跪了,但是实际上操作的qps并不高,秉着质疑,我发现,线程池里只设置了10个线程数,对于这个服务来说10个线程完全不够啊,所以我就跑去扩线程了。
不出所望依然是过了一两周,问题又来了。。
暂时是最后一次猜想
这次是大半夜突然连续出了两三次,而且出的频率还特别高,迁移了实例后过一两个钟又会有实例协程泄露。所以恰好发现,所有会造成突然协程泄露的操作,都是调用了一个写数据的接口导致的。把接口来回看了好几次,硬是没看出问题。但是我意识到一件事,这个接口调用了三次db,而我设置db查询/写的超时时间是3s,而上游却过了10s才熔断,那么按道理来说应该是9s后会超时,感觉到了事情有一点不对。
所以再一次协程泄露时,我暂时没有迁移实例,而是爬上了实例查看实例日志,发现某一行debug日志并未执行。看来问题已经缩小到某几行代码了。
没错,我在开始怀疑gorm框架有问题了,看起了源码。发现我们实现查找最大值的代码很神奇,竟然是拿了rows。代码如下。
func GetMax(ctx context.Context) (int64, error) { var max int64 = 0 db, err := GetConnection(ctx, DatabaseName) if err != nil { return max, err } rows, err := db.Table(TableName).Select("max(xxx) as max").Rows() if err != nil { return max, err } if rows.Next() { err := rows.Scan(&max) if err != nil { return max, err } } return max, nil}复制代码乍一眼看,貌似没啥问题,看一下next的源码,在没有下一行数据时,不会将rows close掉,代码如下,代码来自go 1.13.4源码,只有中文注释是自己加上的:
func (rs *Rows) Next() bool { var doClose, ok bool withLock(rs.closemu.RLocker(), func() { doClose, ok = rs.nextLocked() }) if doClose { // 这里当需要close的时候会将线程释放掉 rs.Close() } return ok // 而返回的true/false是决定能不能拿到数据的}func (rs *Rows) nextLocked() (doClose, ok bool) { if rs.closed { return false, false } // Lock the driver connection before calling the driver interface // rowsi to prevent a Tx from rolling back the connection at the same time. rs.dc.Lock() defer rs.dc.Unlock() if rs.lastcols == nil { rs.lastcols = make([]driver.Value, len(rs.rowsi.Columns())) } rs.lasterr = rs.rowsi.Next(rs.lastcols) if rs.lasterr != nil { // Close the connection if there is a driver error. if rs.lasterr != io.EOF { return true, false } nextResultSet, ok := rs.rowsi.(driver.RowsNextResultSet) if !ok { return true, false } // The driver is at the end of the current result set. // Test to see if there is another result set after the current one. // Only close Rows if there is no further result sets to read. if !nextResultSet.HasNextResultSet() { // 当没有下一行数据时,next是false,close是true doClose = true } return doClose, false } return false, true}复制代码咦这个不close真的不会有问题吗?我们再看看这个rows是从哪里拿出来的,没错线程池,那么不close掉是不是会导致这个线程不会放回去线程池里呢? 我们看看close的代码,代码如下:
func (rs *Rows) close(err error) error { rs.closemu.Lock() defer rs.closemu.Unlock() if rs.closed { return nil } rs.closed = true if rs.lasterr == nil { rs.lasterr = err } withLock(rs.dc, func() { err = rs.rowsi.Close() }) if fn := rowsCloseHook(); fn != nil { fn(rs, &err) } if rs.cancel != nil { rs.cancel() } if rs.closeStmt != nil { rs.closeStmt.Close() } rs.releaseConn(err) // 这里会释放连接 return err}复制代码事实上,应该是的。所以事情到这里应该是已经解决了。解决完的代码如下:
func GetMax(ctx context.Context) (int64, error) { var max int64 = 0 db, err := GetConnection(ctx, DatabaseName) if err != nil { return max, err } rows, err := db.Table(TableName).Select("max(xxx) as max").Rows() if err != nil { return max, err } defer rows.Close() // 只因为少了这一行 if rows.Next() { err := rows.Scan(&max) if err != nil { return max, err } } return max, nil}复制代码但是实际上取max值只会有一个值,为何会使用rows而不使用row呢?不得而知。因为根据go源码来看如果这么写的话是不需要自己去close掉线程的。
for rows.Next() { // 这里改成循环一直走下一个 err := rows.Scan(&max) if err != nil { return max, err }}复制代码还有另一个问题是,为什么会两周一次呢,算一算,实例差不多有15台,而进行这个查max的操作只有在申请某个配置的时候才会触发,而线程池里有10个线程,所以在假设请求是均衡的情况下,要申请100+次才会开始命中这个问题。而且也只有db线程数不够的机器才会出现这种问题,再加上这个服务已经相对比较稳定了,很久没有怎么加过需求了,所以容器不会重启,内存不会重置。至于GC到底能不能把解决这个问题呢,应该是不行的,因为解决了只会让你的线程数减少。
哎,真的是菜,定位问题都那么难。主要还是没啥经验吧,所有接口都报错了,一开始无从下手,直到某天凌晨给报警电话打醒,才突发奇想去定位这个问题。
内存全表存储设计
为什么要设计用内存呢?首先,表不多,其次,数据也不太多平均每张表也就5k,而且,由于并不希望上游每次拿数据都需要请求这个服务,所以需要扫表。基于以上原因,该服务是没有用redis做缓存的,服务设计如下。
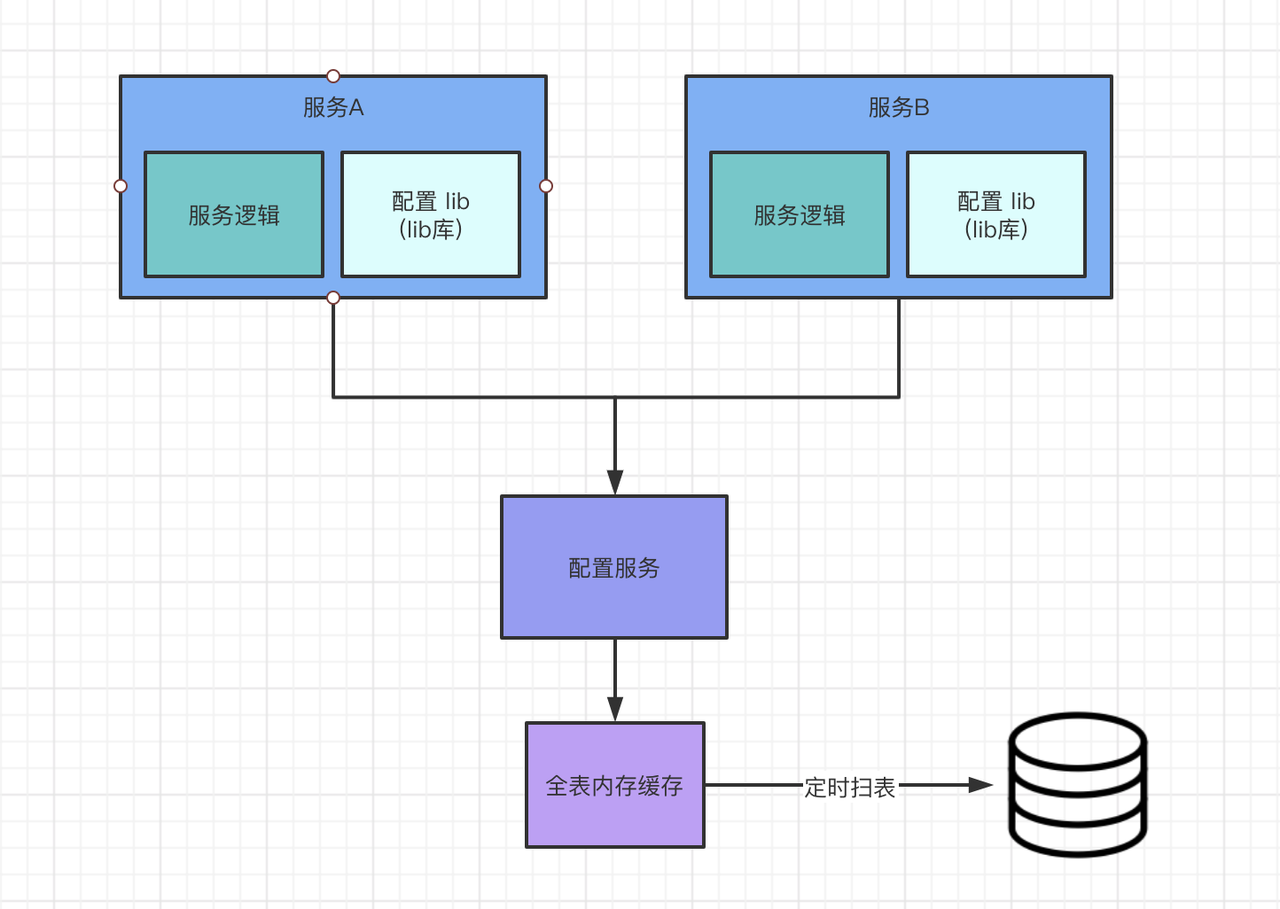
这样设计的优缺点是什么呢
优点:
- db压力小,数据量不多的情况下扫表问题不大。
- 当上游服务多时,实例充当了一个redis,db没有来自上游的请求压力。
- 没有序列化和反序列化的时间复杂度
缺点:
- 开发成本高,go没有泛型,为了减少序列化,代码写的比较暴力
- 更新效率慢,取决于数据轮训的时间,适用于不需要及时更新的数据
结语
这个服务是刚进公司的时候学到的,没想到会有隐藏问题,而且还藏了那么久。
服务设计是挺不错的,就是开发起来特别恶心。
还是自己太菜了,多学点东西吧。
给这篇文章的作者打赏
文章来源:智云一二三科技
文章标题:一行代码引起的协程泄露
文章地址:https://www.zhihuclub.com/1595.shtml


