go 协程如何实现;
使用的m:n调度模型,即任意数量的用户态协程可以运行在任意数量的线程上
M:os线程(即操作系统内核提供的线程),
G:goroutine,其包含了调度一个协程所需要的堆栈以及instruction pointer(IP指令指针),以及其他一些重要的调度信息。
P:M与P的中介,实现m:n 调度模型的关键,M必须拿到P才能对G进行调度,P其实限定了golang调度其的最大并发度
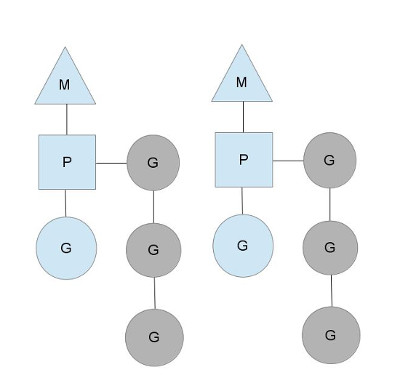
2个M分别拿到context P在运行G,M只有拿到context P才能执行goroutine。被执行的goroutine在运行过程中调用 go func() ,会创建一个新的对应func() 的goroutine,并将这个goruotine加入到runqueue(就绪待调度的goroutine队列,如上图灰色部分所示),当前运行的goroutine在达到调度点(系统调用、网络IO、等待channel等)的时候,P会挂起当前运行的goroutine,从runqueue中pop一个goroutine,重新设置当前M的执行上下文继续执行(即设置为pop出来的goroutine对应的运行堆栈以及IP(instruction Point))。
Go 语言运行时会在底层通过调度器将用户级线程交给操作系统的系统级线程去处理,如果在运行过程中遇到某个 IO 操作而暂停运行,调度器会将用户级线程和系统级线程分离,以便让系统级线程去处理其他用户级线程,而当 IO 操作完成,需要恢复运行。调度器又会调度空闲的系统级线程来处理这个用户级线程,从而达到并发处理多个协程的目的。
此外,调度器还会在系统级线程不够用时向操作系统申请创建新的系统级线程,而在系统级线程过多的情况下销毁一些空闲的线程,这个过程和 PHP-FPM 的工作机制有点类似,实际上这也是很多进程/线程池管理器的工作机制
进程线程的区别;
看了一遍排在前面的答案,类似”进程是资源分配的最小单位,线程是CPU调度的最小单位“这样的回答感觉太抽象,都不太容易让人理解。
做个简单的比喻:进程=火车,线程=车厢
线程在进程下行进(单纯的车厢无法运行)
一个进程可以包含多个线程(一辆火车可以有多个车厢)
不同进程间数据很难共享,同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
但是一个线程挂掉不一定会导致进程挂掉(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
进程可以拓展到多机,进线程最多扩展到多核CPU。不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-"互斥锁"
线程是共享了进程的上下文环境,的更为细小的CPU时间段。
进程之间怎么通讯的?
1、管道(它只能用于具有亲缘关系的进程之间的通信)
2、消息队列(消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除)
3、信号量(用于进程间同步,若要在进程间传递数据需要结合共享内存)
4、共享内存(两个或多个进程共享一个给定的存储区)
给这篇文章的作者打赏
文章来源:智云一二三科技
文章标题:Go
文章地址:https://www.zhihuclub.com/5193.shtml


