从事服务端开发,少不了要接触网络编程。 Epoll 作为 Linux 下高性能网络服务器的必备技术至关重要,Nginx、 redis 、 Skynet 和大部分游戏服务器都使用到这一多路复用技术。
select()和poll() IO多路复用模型
select的缺点:
- 单个进程能够监视的 文件描述符 的数量存在最大限制,通常是1024,当然可以更改数量,但由于select采用轮询的方式扫描文件描述符,文件描述符数量越多,性能越差;(在 linux内核 头文件中,有这样的定义:#define __FD_SETSIZE 1024)
- 内核 / 用户空间内存拷贝问题,select需要复制大量的句柄数据结构,产生巨大的开销;
- select返回的是含有整个句柄的数组,应用程序需要遍历整个数组才能发现哪些句柄发生了事件;
- select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO操作,那么之后每次select调用还是会将这些文件描述符通知进程。
相比select模型,poll使用 链表 保存文件描述符,因此没有了监视文件数量的限制,但其他三个缺点依然存在。
拿select模型为例,假设我们的服务器需要支持100万的并发连接,则在__FD_SETSIZE 为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
因此,该epoll上场了。

详细教程资料关注+后台私信;资料;两个字可以免费视频领取+文档+各大厂面试题 资料内容包括:C/C++,Linux,golang,Nginx,ZeroMQ,MySQL, Redis ,fastdfs, MongoDB ,ZK, 流媒体 , CDN ,P2P,K8S, Docker ,TCP/IP,协程,DPDK,嵌入式 等。
epoll IO多路复用模型实现机制
由于epoll的实现机制与select/poll机制完全不同,上面所说的 select的缺点在epoll上不复存在。
设想一下如下场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些 套接字 上是否有事件发生,轮询完后,再将句柄数据复制到用户态,让服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大,因此,select/poll一般只能处理几千的并发连接。
epoll的设计和实现与select完全不同。epoll通过在Linux内核中申请一个简易的文件系统(文件系统一般用什么数据结构实现?B+树)。把原先的select/poll调用分成了3个部分:
1)调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源)
2)调用epoll_ctl向epoll对象中添加这100万个连接的套接字
3)调用epoll_wait收集发生的事件的连接
如此一来,要实现上面说是的场景,只需要在进程启动时建立一个epoll对象,然后在需要的时候向这个epoll对象中添加或者删除连接。同时,epoll_wait的效率也非常高,因为调用epoll_wait时,并没有一股脑的向操作系统复制这100万个连接的句柄数据,内核也不需要去遍历全部的连接。
Epoll 很重要,但是 Epoll 与 Select 的区别是什么呢?Epoll 高效的原因是什么?
从网卡接收数据说起
详细教程资料关注+后台私信;资料;两个字可以免费视频领取+文档+各大厂面试题 资料内容包括:C/C++,Linux,golang,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,嵌入式 等。
下边是一个典型的计算机结构图,计算机由 CPU、存储器(内存)与网络接口等部件组成,了解 Epoll 本质的第一步,要从硬件的角度看计算机怎样接收网络数据。
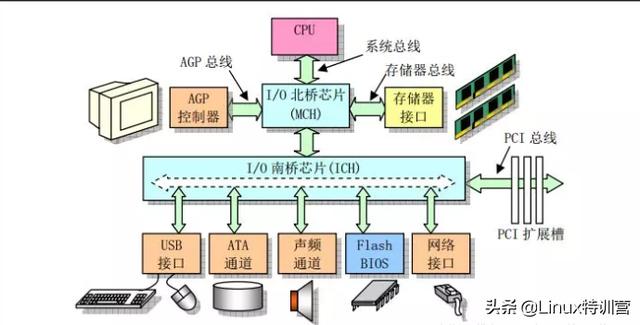
计算机结构图(图片来源:Linux 内核完全注释之微型计算机组成结构)
下图展示了 网卡 接收数据的过程:
- 在 1 阶段,网卡收到网线传来的数据。
- 经过 2 阶段的硬件电路的传输。
- 最终 3 阶段将数据写入到内存中的某个地址上。
这个过程涉及到 DMA 传输、IO 通路选择等硬件有关的知识,但我们只需知道:网卡会把接收到的数据写入内存。
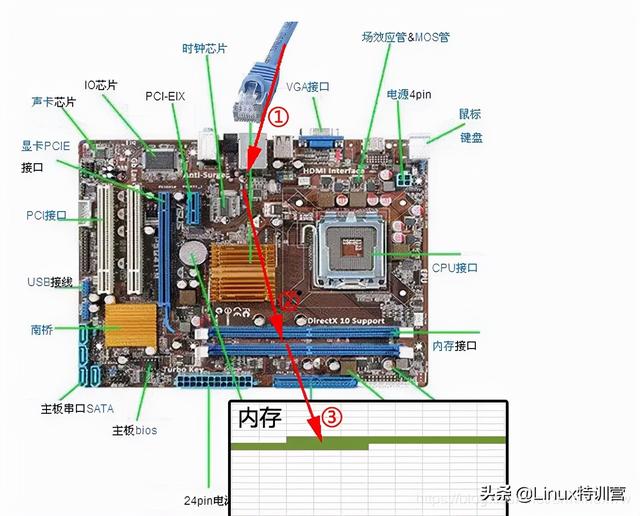
网卡接收数据的过程
通过硬件传输,网卡接收的数据存放到内存中,操作系统就可以去读取它们。
如何知道接收了数据?
了解 Epoll 本质的第二步,要从 CPU 的角度来看数据接收。理解这个问题,要先了解一个概念:中断。
计算机执行程序时,会有优先级的需求。比如,当计算机收到断电信号时,它应立即去保存数据,保存数据的程序具有较高的优先级( 电容 可以保存少许电量,供 CPU 运行很短的一小段时间)。
一般而言,由硬件产生的信号需要 CPU 立马做出回应,不然数据可能就丢失了,所以它的优先级很高。
CPU 理应中断掉正在执行的程序,去做出响应;当 CPU 完成对硬件的响应后,再重新执行用户程序。
中断的过程如下图,它和函数调用差不多,只不过函数调用是事先定好位置,而中断的位置由“信号”决定。

中断程序调用
以键盘为例,当用户按下键盘某个按键时,键盘会给 CPU 的中断引脚发出一个高电平,CPU 能够捕获这个信号,然后执行键盘中断程序。
下图展示了各种硬件通过中断与 CPU 交互的过程:
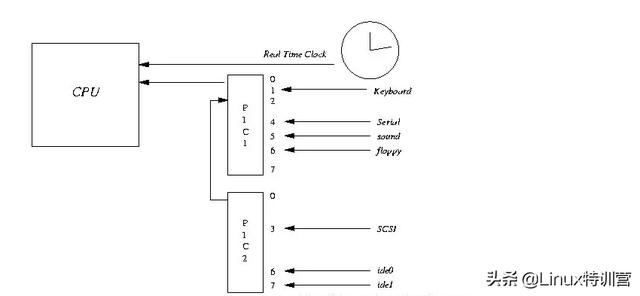
当网卡把数据写入到内存后,网卡向 CPU 发出一个中断信号,操作系统便能得知有新数据到来,再通过网卡中断程序去处理数据。
epoll的线程安全设计
1.对rbtree-->加锁;
2.对queue -->spinlock
3.epoll_wati,cond,mutex 开源项目中的ET和LT的选择
ET模式
因为ET模式只有从unavailable到available才会触发,所以
读事件:需要使用while循环读取完,一般是读到EAGAIN,也可以读到返回值小于缓冲区大小;
如果应用层读缓冲区满:那就需要应用层自行标记,解决OS不再通知可读的问题
写事件:需要使用while循环写到EAGAIN,也可以写到返回值小于缓冲区大小
如果应用层写缓冲区空(无内容可写):那就需要应用层自行标记,解决OS不再通知可写的问题。
LT模式
因为LT模式只要available就会触发,所以:
读事件:因为一般应用层的逻辑是“来了就能读”,所以一般没有问题,无需while循环读取到EAGAIN;
如果应用层读缓冲区满:就会经常触发,解决方式如下;
写事件:如果没有内容要写,就会经常触发,解决方式如下。
LT经常触发读写事件的解决办法:修改fd的注册事件,或者把fd移出epollfd。
总结
目前好像还是LT方式应用较多,包括redis,libuv.
LT模式的优点在于:事件循环处理比较简单,无需关注应用层是否有缓冲或缓冲区是否满,只管上报事件
缺点是:可能经常上报,可能影响性能。
在我目前阅读的开源项目中:
TARS用的是ET,Redis用的是LT,Nginx可配置(开启NGX_HAVE_CLEAR_EVENT--ET,开启NGX_USE_LEVEL_EVENT则为LT).


