tcp udp相关视频解析:
先看内核是如何组织TCP源端口号数据结构,我依然用一个图示表达,这比代码更加清晰一些:

以上这个结构在内核中叫做bhash,是TCP协议实现中3个核心hash之一,这3个hash结构分别是:
- bhash:维护连接的源端口号,以源端口号计算hash值
- ehash:维护establish连接,以四元组计算hash值
- lhash:维护侦听TCP,以{srcIP,srcPORT}二元组计算hash值
显然,关于如何确定源端口的问题就转化为了上述数据结构的查询,插入的问题,这个问题的解法是明确的,即:
为新的待确定源端口的连接socket查询到一个最优的插入位置并插入。
我们非常明确的一个目标就是: 维持四元组的唯一性!
这无疑是一个搜索结构的操作问题。哈哈,又是一道面试题咯。
接下来要解决的是,在两个不同的场景下,如何操作以上这个数据结构。两个场景分别如下:
- TCP socket在bind的时候
- TCP socket在connect的时候
显然,在TCP进行bind的时候,由于此时并不确定目标是谁,无论是目标IP还是目标端口都不确定,甚至不晓得这个TCP是不是一个Listener,那么四元组的唯一性约束显然强化了不少,即: 必须保证{srcIP,srcPORT}二元组的唯一性! 事实上此时我们要保证的是{srcIP,srcPORT,0,0}元组的唯一性。
与bind场景不同的是,如果一个socket事先没有bind,直接调用了connect,当我们调用connect的时候,此时确定的是{dstIP,dstPORT}元组,那么此时的约束就松了不少,也就是说要想保证四元组唯一性,这种场景下给我们的机会会更多一些。
具体来讲,我给出一个流程:

有了connect的场景分析,bind场景就再简单不过了,省略下面ehash的部分即可:
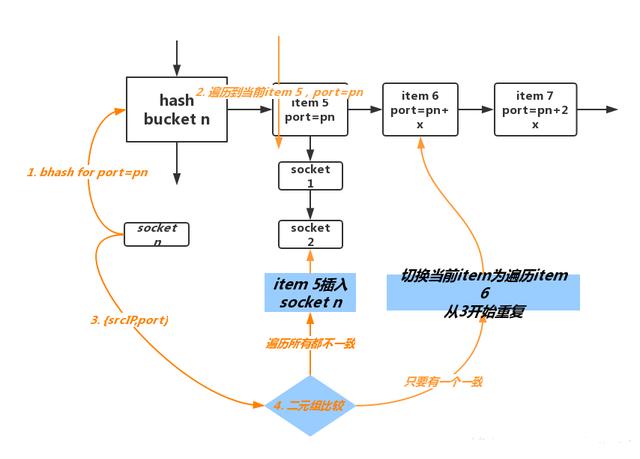
理清了关系之后,很简单是吧。这里讲的是TCP,对于UDP而言也一样适用,只不过UDP有更简单的解法。
【文章福利】需要C/C++ Linux服务器架构师学习资料加群812855908(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等)

以上就是确定源端口的基本原则,然而在具体操作过程中,还有一个原则,即维护数据结构的平衡型,我们不希望单独的hash冲突链表过长,因为遍历一个冲突链表的时间复杂度是O(n),这显然毫无可扩展性,所以在插入过程中需要 尽量插入到短的hash bucket链表中 。
这就涉及到另一个问题,即:
图示中初始的探测端口port=pn如何选择的问题!
这里就是列维模型在起作用了!
物理类聚,这是普世真理。Linux内核在实现这个确定源端口的过程中,经过了几次进化,但万变不离其宗,对于TCP而言,Linux从一个随机确定的hash bucket开始探测,然后环状遍历所有的bhash bucket,对每一个bucket执行上面图示里的算法。
对于UDP而言,我劝大家review一下Linux内核2.6.18,3.10,4.9+的代码,这代表了三个进化阶段,起初在2.6.18版本时,UDP维护了一个全局的 udp_port_rover 变量,指示下一次探测可用源端口时从哪里开始,然而到了3.10,4.x版本,实现方式便起了变化,不再通过链表数据结构进行多次广度优先遍历,而是采用深度优先原则使用位图来实现,但这并没有改变实质。
代码并不难懂,相对于像屎一样的TCP拥塞控制算法的代码,这个要好很多,找 get_port 回调函数就好,然后看看 tcp_v4_connect 函数,大概10分钟应该可以读懂,我这里就不再赘述细节,记住一个原则,如果你要实现自己的算法,优先找最短的冲突链表进行遍历插入,你稍微费点事,带来的是整个系统性能的提升。
如下图,这就是列维模型!TCP和UDP确定源端口的算法绝对符合这个模型



