
学不动了
瞎写瞎看

在 Go 中使用接口(interface{})好像有性能问题,但是真的如此吗,或者我们有哪些可以提升的空间,来看一下 go lang 的一个 issue。例子中跑了三个 benchmark,一个是接口调用,一个是直接调用,后面我又加了一个接口断言后调用。
import ( "testing")type D interface { Append(D)}type Strings []stringfunc (s Strings) Append(d D) {}func BenchmarkInterface(b *testing.B) { s := D(Strings{}) for i := 0 ; i < b.N ; i += 1 { s.Append(Strings{""}) }}func BenchmarkConcrete(b *testing.B) { s := Strings{} // only difference is that I'm not casting it to the generic interface for i := 0 ; i < b.N ; i += 1 { s.Append(Strings{""}) }}func BenchmarkInterfaceTypeAssert(b *testing.B) { s := D(Strings{}) for i := 0 ; i < b.N ; i += 1 { s.(Strings).Append(Strings{""}) }}
我用的版本是 go version1.13,执行结果如下,

执行了多遍结果没啥大的偏差,可以看到直接使用接口调用确实效率比直接调用低了非 常多。但是,当我们将类型断言之后,可以发现这个效率基本没有差别的。这是为什么呢?答案是内联和内存逃逸,注意红框内的内存分配。
内联 inline
什么是内联
内联是一个基本的编译器优化,它用被调用函数的主体替换 函数调用 。以消除调用开销,但更重要的是启用了其他编译器优化。这是在编译过程中自动执行的一类基本优化之一。它对于我们程序性能的提升主要有两方面
- 消除了函数调用本身的开销
- 允许编译器更有效地应用其他优化策略(例如常量折叠,公共子表达式消除,循环不变代码移动和更好的寄存器分配)
可以通过一个例子直观看一下内联的作用
package mainimport "testing"//go:noinlinefunc max(a, b int) int { if a > b { return a } return b}var Result intfunc BenchmarkMax(b *testing.B) { var r int for i := 0; i < b.N; i++ { r = max(-1, i) } Result = r}
执行一下
go test -bench=. -benchmem -run=none
可以看到结果

然后我们允许 max 函数内联,也就是把 //go:noinline 这行代码删除,再执行一遍。可以看到

对比使用内联的前后,我们可以看到性能有极大的提升,从 2.31ns/op->0.519ns/op。
内联做了什么
首先,减少了相关函数的调用,将 max 的内容嵌入调用方减少了处理器执行指令的数量,消除了调用分支。
由于 r=max(-1,i) , i是从 0 开始的,所以 i>-1 ,那么 max 函数的 a>b 分支永远不会发生。编译器可以把这部分代码直接内联至调用方,优化后的代码如下。
func BenchmarkMax(b *testing.B) { var r int for i := 0; i < b.N; i++ { if -1 > i { r = -1 } else { r = i } } Result = r}
替换成上述的代码,在执行一下可以看到性能是差不多的

上面讨论的这种情况是叶子内联,将调用栈底部的函数内联到直接调用方的行为。内联是一个递归的过程,一旦函数被内联到其调用方,编译器就可以将结果代码嵌入至调用方,以此类推。
内联的限制
并不是任何函数都是可以内联的,从 golang 的 wiki 可以看到下面这句话
也就是说,仅能内联简短和简单的函数。要内联,函数必须包含少于〜40个表达式,并且不包含复杂的语句,例如 loop,label,closure,panic,recover,select,switch 等。
当然这种是有提示的,比如 for 语句,可以从提示里看到不支持内联。

堆栈中间内联 mid-stack
Go 1.8 开始,编译器默认不内联堆栈中间(mid-stack)函数(即调用了其他不可内联的函数)。堆栈中间内联(mid-stack)由 David Lazar 在 GO1.9 中引入 proposal,经过压测表明这种栈中内联可以将性能提高 9%,带来的副作用是编译的二进制文件大小会增加 15%。继续看一个例子
package mainimport ( "fmt" "strconv")type Rectangle struct {}//go:noinlinefunc (r *Rectangle) Height() int { h, _ := strconv.ParseInt("7", 10, 0) return int(h)}func (r *Rectangle) Width() int { return 6}func (r *Rectangle) Area() int { return r.Height() * r.Width() }func main() { var r Rectangle fmt.Println(r.Area())}
在这个例子中, r.Area() 调用了 r.Width() 和 r.Height(),前者可以内联,后者由于添加了 //go:noinline 不能内联。我们执行下面的命令来看一下内联的情况。
go build -gcflags='-m=2' square.go
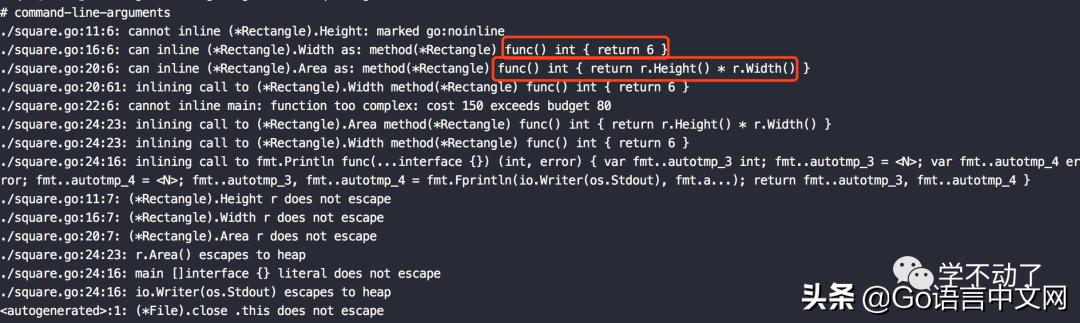
在输出的第 3、4 行可以看到, width 和 Area 函数都是可以被内联的,并且红框内是内联后的语句。
在第 6 行输出了以下内容,说明是不符合内联的条件的,有一个 budget 限制,这一块可以参考文章 《Go语言inline内联的策略与限制》(。
./square.go:22:6: cannot inline main: function too complex: cost 150 exceeds budget 80
因为与调用 r.Area() 的开销相比, r.Area() 执行的乘法是比较简单的,所以内联 r.Area() 的单个表达式,即使它调用的 r.Height() 不符合内联条件。
快速路径内联
由于 mid-stack 的优化,导致可以内联其他调用了不可内联的函数,快速路径内联就采用的这个思想,也就是说将复杂函数的复杂部分拆分成分支函数,这样快速路径就可以被内联了。例子来源于golang code-review,作者使用快速路径内联的手段将 RUnlock 能够被内联,从而实现了性能提升。
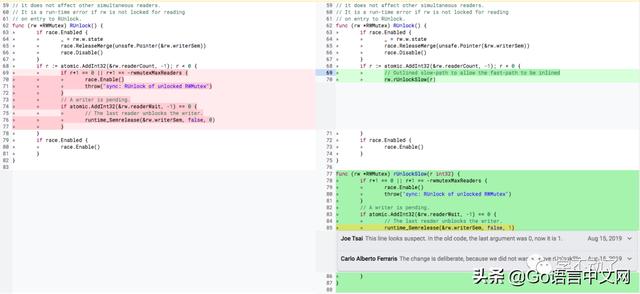
由于左侧的老代码包含了很多条件,导致 RUnlock 函数不能被内联。这里作者把条件复杂的逻辑拆分出去一个函数,称为慢路径函数。这里我们可以拿一个例子试试,这是个没有意义的例子,只为证明内联优化的存在。
package mainimport ( "sync")var rw sync.RWMutexfunc test(num int) int { rw.RLock() num += 1 rw.RUnlock() return num}
使用 go 1.9 版本的输出,

使用 go 1.13 版本的输出,

从上面的输出,可以看到快路径优化后,内联生效了,据作者的压测表明,性能节省了 9%,当然我们可以自己压一下试试,经过多次测试,能有 18ns/op->15ns/op 的提升。
// go version 1.9BenchmarkRlock-4 100000000 18.9 ns/op 0 B/op 0 allocs/op// go version 1.13BenchmarkRlock-4 76204650 15.3 ns/op 0 B/op 0 allocs/op
逃逸分析 escape-analysis
什么是内存逃逸
首先我们知道,内存分为堆内存(heap)和栈内存(stack)。对于堆内存来说,是需要清理的。比如 c 语言中的 malloc 就是用来分配堆内存的,申请了堆内存之后一定要手动释放,不然就造成内存泄露。但是 Go 语言是有 GC 的,所以不需要手动释放。所以对于这一点而言,使用堆的成本比栈高,会给 GC 带来压力,因为堆上没有被指针引用的值都需要删除。随着检查和删除的值越多,GC 每次执行的工作就越多。
如果一个函数返回对一个变量的引用,那么它就会发生逃逸。因为在别的地方会引用这个变量,如果放在栈里,函数退出后,内存就被回收了,所以需要逃逸到堆上。
简而言之,逃逸分析决定了内存被分配到栈上还是堆上
如何监测内存逃逸
可以通过查看编译器的报告来了解是否发生了内存逃逸。使用 go build-gcflags=’-m=2′ 即可。总共有 4 个级别的 -m,但是超过 2 个 -m 级别的返回的信息比较多。通常使用 2 个 -m 级别。
接口类型的方法调用
go 中的接口类型的方法调用是动态调度,因此不能够在编译阶段确定,所有类型结构转换成接口的过程会涉及到内存逃逸的情况发生。
package maintype S struct { s1 int}func (s *S) M1(i int) { s.s1 = i }type I interface { M1(int)}func g() { var s1 S // 逃逸 var s2 S // 不逃逸 var s3 S // 不逃逸 f1(&s1) f2(&s2) f3(&s3)}func f1(s I) { s.M1(42) }func f2(s *S) { s.M1(42) }func f3(s I) { s.(*S).M1(42) }
查看一下编译器报告,
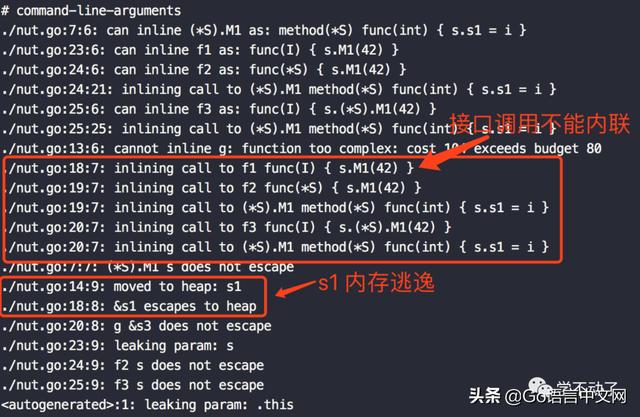
- 直接使用接口方法调用,不能内联。我们可以看第一个红框内,通过接口调用 I.M1(42) 不能内联,而断言和具体类型调用可以继续内联。
- 直接使用接口方法调用,会发生内存逃逸。而具体类型调用或者断言后调用,不会发生内存逃逸。这也验证了文章开头部分的压测,接口调用发生了内存分配,这些内存分配即是逃逸到堆上的内存。
回顾
我们在看一下文章开始的例子,
package maintype D interface { Append(D)}type Strings []stringfunc (s Strings) Append(d D) {}func concreteTest() { s := Strings{} // only difference is that I'm not casting it to the generic interface for i := 0 ; i < 10 ; i += 1 { s.Append(Strings{""}) }}func interfaceTest() { s := D(Strings{}) for i := 0 ; i < 10 ; i += 1 { s.Append(Strings{""}) }}func assertTest() { s := D(Strings{}) for i := 0 ; i < 10 ; i += 1 { s.(Strings).Append(Strings{""}) }}
执行
go build -gcflags='-m=2' iterface.go
可以看到输出,
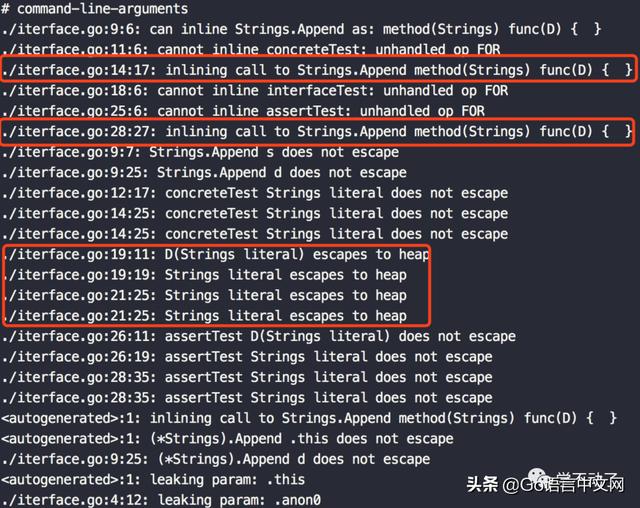
也就是接口直接调用,没有内联,并且发生了内存逃逸。当我们通过断言后再调用方法,发生了内联,并且没有内存逃逸。所以,接口直接调用的性能是有问题的。
总结
通过以上分析,我们在使用接口的时候一定要注意,最好将接口断言出来再使用,这样会提高性能。同时日常开发中,可以多加分析,避免内存逃逸带来的内存消耗和 GC 的压力,提高性能。
参考资料
[1]
go issue 20116:
[2]
go 性能调优:
[3]
Go 编译优化 wiki:
[4]
inlining opt by dave:
[5]
mid-stack inline proposal:
[6]
golang mid-stack issue:
[7]
golang 内存逃逸:
[8]
golang: Escape analysis and interfaces:
[9]
Go语言inline内联的策略与限制:


