动手实现并行版AlphaZero五子棋
前言
AlphaZero算法已经发布了一年多了,GitHub也有各种各样的实现,有一千行 Python 代码单线程低性能版,也有数万行C++代码的分布式版本。但是这些实现都不能满足一般的算法爱好者的需求,即一个简单的并且单机的可运行的高性能AlphaZero算法。
一图解密AlphaZero
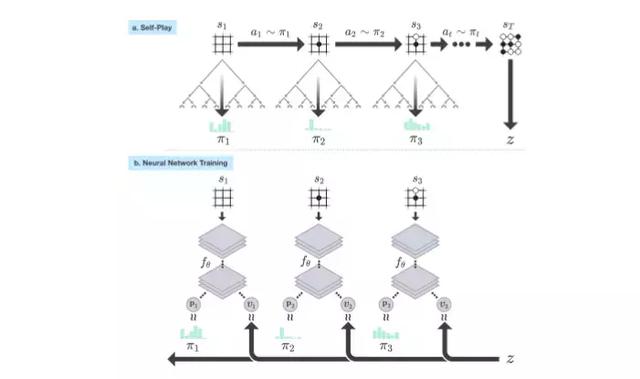
首先我们通过一张图了解一下AlphaZero算法的原理

可以看到AlaphaGo Zero的算法流程分为:
- 自对弈(利用蒙特卡洛树搜索)N局生成棋谱
- 利用生成的棋谱训练网络
- 评估新训练的网络
分析
对于Python版本的AlphaZero算法,通常受限制于GIL,过程中最耗时间的自对弈阶段(见下图)无法并行化,所以最直接的优化方式是使用C++这种高性能语言实现底层运算细节。
解决方法
线程池
github.com/hijkzzz/alp…
为了并行化自对弈过程,首先我们需要实现一个C++的线程池。关于线程池网上有很多的资料可以参考,这里就不多做叙述。
Root Parallelization
从算法流程图中可以看到,自对弈过程使用蒙特卡洛树搜索实现,所以有两个维度可以并行化自对弈:Root Parallelization和Tree Parallelization。其中Root Parallelization指的是同时开启N局对弈,每个线程负责一局游戏。Tree Parallelization指的是把单局游戏中的蒙特卡洛树搜索(MCTS)并行化。于是用N个线程就很容易实现Root Parallelization,下面我们讨论Tree Parallelization。
Tree Parallelization
首先分析一下蒙特卡洛树搜索(MCTS)的运行过程:
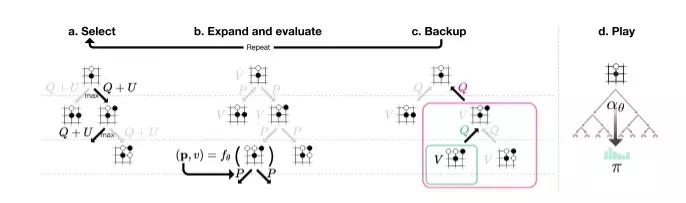
每执行一步棋子,MCTS要执行M次落子模拟,每次模拟就是一次递归过程,如下:
- Select,如果当前节点不是叶子节点则通过特定的UCT算法(探索-利用算法,通过神经网络预测的胜率值(q值)以及先验概率计算选择概率,胜率/先验概率越高选择几率越大)找出最优的下一个落子位置,搜索进入下一层,直到当前节点是叶子节点。
- Expand and evaluate,如果当前节点是叶子节点,这里分为两种情况:
- 当前节点游戏结束,某一方获胜,则进行Backup向上回溯更新父节点的胜率值
- 如果游戏没有结束,则用神经网络预测当前节点的胜率和下一层的先验概率,用这个先验概率展开此节点,然后进行Backup向上回溯更新父节点的胜率值(q值)
- Backup,每个节点保存一个胜率值(q值),q值等于赢的次数/访问次数,backup从结束状态向上更新这个值以及访问次数。
- Play,实际游戏中落子的时候选择根节点下访问次数最多的子节点即可(因为q值越大的节点select的概率越大,访问次数也越多)。
所以我们可以同时进行M’(小于M)次模拟,所以对一些关键数据就要加锁,比如蒙特卡洛树的父子节点关系,访问次数,q值等。也有人研发出了一些无锁的算法[5],但是因为预先分配树节点的关系,对内存的占用量极大,一般的机器跑不起来,所以这里用的是加锁版的并行蒙特卡洛树搜索。
Virtual Loss
对于Tree Parallelization,如果我们简单的把蒙特卡洛搜索(MCTS)并行化,那么会遇到一个问题:M’个线程经常会搜索同一个节点,这样我们的并行化就失去了意义,因为搜索同一个节点意味着重复工作。所以在UCT算法中,当一个节点被一个线程访问时,我们加入一个Virtual Loss的惩罚,这样其它线程就不太可能会选择这个节点进行搜索。
LibTorch
因为MCTS的过程中需要用到神经网络预测胜率和先验概率,所以C++需要调用Python实现的神经网络预测方法,但是这样又会回到原点。即Pyhton的GIL限制会导致并行化的自对弈被强制串行化执行。所以我们使用PyTorch的C++前端LibTorch实现神经网络。
CUDA Stream
工作后对于运行在 GPU 上的神经网络来说,实际上我们的程序还是没有真正的并行化。这是因为LibTorch的预测执行受限制于Default CUDA Steam,即默认是串行的,会导致多线程调用预测被阻塞。有两个方法来避免这个问题:1. 用多个CUDA Stream 2.合并预测请求。这里我们使用的方法是用缓冲队列合并多个预测,一次性推送到GPU,这样就防止了GPU工作流的争用导致线程阻塞。
SWIG
www.swig.org/tutorial.ht…
最后我们把上述相关的C++代码用SWIG封装成Python接口,以供主程序调用。虽然这会导致一部分性能开销,但是大大提高了开发的效率。
测试
经过测试,并行化后的训练效率至少提升了10倍。简单的计算一下,假设每个MCTS用4个线程,同时玩4局游戏,即4×4=16倍,考虑锁和缓冲队列以及Python接口的开销,提升数量级是合理的。此外只要GPU足够强悍,提升线程数还能继续提高性能。最后我用了一天时间在一块GTX1070上训练了一个标准的15×15的五子棋算法,已经可以完败普通玩家。
参考文献
- Mastering the Game of Go without Human Knowledge
- Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
- Parallel Monte-Carlo Tree Search
- An Analysis of Virtual Loss in Parallel MCTS
- A Lock-free Multithreaded Monte-Carlo Tree Search Algorithm
参考文献:K码农-


