用户态协议栈的意义
在内核实现协议栈往往存在两次拷贝过程,一是网卡中的数据通过sk_buff拷贝到内核,之后再从内核拷贝到进程用户空间。
于是我们考虑如何加快这个过程,减少拷贝次数。一种思路:通过DMA直接将数据从网卡拷贝到内存中,于是应用程序可以直接通过mmap从内存中取得数据。由于DMA的工作是不需要CPU干预的,所以对于CPU来说相当于没有做任何的拷贝操作,即所谓零拷贝。
那么应用进程如何通过这种方式从网卡直接取得数据?常用几种方法:
- 使用raw socket
- netmap框架
- dpdk框架
推荐视频:
学习地址:
netmap
netmap是一个可用于用户层应用程序收发原始网络数据的高性能框架,包含了内核驱动模块及API库函数。
Userspace clients can dynamically switch NICs into netmap mode and send and receive raw packets through memory mapped buffers.
常用接口说明
主要头文件:netmap.h 和 netmap_user.h,位于源码包的./netmap/sys/net/目录下。
netmap.h 被 netmap_user.h调用,里面定义了一些宏和几个主要的结构体。一般来说,如果仅仅只是想要收发数据,在上手时我们知道下面几个接口就可以了。
- nm_open
struct nm_desc *nm_open(const char *ifname, const struct nmreq *req,uint64_t new_flags, const struct nm_desc *arg) nm_open针对ifname指示的网卡接口启用netmap并返回针对该接口的描述符结构体。一般直接这样调用既可:
struct nm_desc *nmr = nm_open("netmap:eth1", NULL, 0, NULL); struct nm_desc中包含一个fd指向/dev/netmap,可用于poll、epoll等系统调用。
- nm_nextpkt
nm_nextpkt()用于接收网卡上收到的数据包。它会将内部所有接收环检查一遍,如果有需要接收的数据包,则返回这个数据包。一次只能返回一个以太网数据包。因为接收到的数据包没有经过协议栈处理,因此需要在用户程序中自己解析。
读一个数据包时一般这样调用,stream即为数据在缓冲区中的首地址,struct nm_pkthdr为返回的数据包头部信息,不需要管头部的话直接从stream去取数据就行了。
struct nm_pkthdr nmhead = {0};char* stream = nm_nextpkt(nmr, &nmhead); - nm_inject
nm_inject()是用于往共享内存中写入待发送的数据包,数据再被从共享内存拷贝到网卡,进而发送出去。它检查所有的发送环,找到一个可以发送的槽后将数据写入。一次只能发送一个包,包的长度由参数指定。一般的调用方式:
nm_inject(nmr, &datapack, packlen); - nm_close
简单的理解就是nm_open的逆过程,回收动态内存,回收共享内存,关闭文件描述符等等。
安装netmap
下载netmap的github地址。按照说明安装完成之后,可以调用下面的指令进行测试:
sudo pkt-gen -i eth0 -f rx # eth0 是网卡名称 在这之前还需要先执行一下:sudo insmod netmap.ko。该驱动模块挂载之后,/dev/目录下会多一个字符型设备:
crw-rw---- 1 root root 10, 56 Nov 7 10:53 /dev/netmap 之后,一旦调用接口nm_open,网卡的数据就不从内核协议栈走了,这时候最好在虚拟机中建两个网卡,一个用于netmap,一个用于ssh等应用程序的正常工作。
协议栈的数据结构定义
下图是实现一个UDP协议时的网络协议栈结构及其数据封装的简化形式,我们的用户态协议栈需要实现链路层、网络层以及传输层。按照图中数据包结构,我们需要依次提取链路层、网络层、传输的首部,并最终得到用户数据。

链路层首部

typedef unsigned char _u8;typedef unsigned short _u16;typedef unsigned int _u32;#pragma pack(1) // 告诉编译器以一个字节对齐
#define ETH_LEN 6#define IP_LEN 4#define PROTO_IP0x0800// 参考上图#define PROTO_ARP0x0806#define PROTO_RARP0x0835struct eth_header{ _u8 dst_mac[ETH_LEN]; _u8 src_mac[ETH_LEN]; _u16 type;}; 链路层使用的地址为MAC地址。
网络层首部
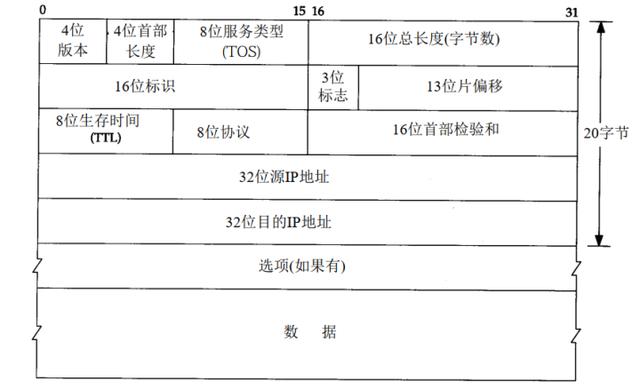
// IP协议类型的字段定义在头文件: <arpa/inet.h>struct ip_header{ _u8 header_len : 4, // 首部长度是低4位,版本是高4位 version : 4; _u8 tos; _u16 total_len; _u16 id; _u16 flag_off; _u8 ttl; _u8 proto; _u16 header_check; _u32 src_ip; _u32 dst_ip;};
struct ip_packet{ struct eth_header eth; struct ip_header ip;}; 网络层使用的地址为IP地址。IP首部中8位协议类型的定义见内核源码include/uapi/linux/in.h。
注意:
字节序问题,结构体定义时一定要注意网络字节序为大端字节序。大端模式下当我们看一个字节时,其bit位从左到右为高位到低位,这与我们正常描述一个字节的二进制形式时是一致的;但当一个数据为多个字节时,字节内的bit顺序还是这样,但多个字节之间高低位需要逆序排列。所以从首部数据中看,4位首部长度和4位版本组成1个字节,4位版本是在高4位,4位首部长度是在低4位;但当我们看16位总长度字段时,如大端系统数据存储为 0x12(低8位) 0x34(高8位),实际这个值是0x1234,在小端系统实际应存储为0x34(低8位) 0x12(高8位),因此需要做转换。总的来说,大小端只影响我们习惯上看多个字节之间的顺序,不影响我们习惯上看1个字节内bit位的顺序。
首部长度字段是指首部占多少个32 bit(即多少个unsigned int),而不是多少字节!!小心这个坑。
IP包的总长度与MTU:MTU是网卡的限制,数据超出限制后会分片发出;与IP包头部中指定的总长度之间并不冲突。
【文章福利】需要C/C++ Linux服务器架构师学习资料加群812855908(资料包括C/C++,Linux,golang技术,内核,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg,大厂面试题 等)
传输层首部
UDP首部:
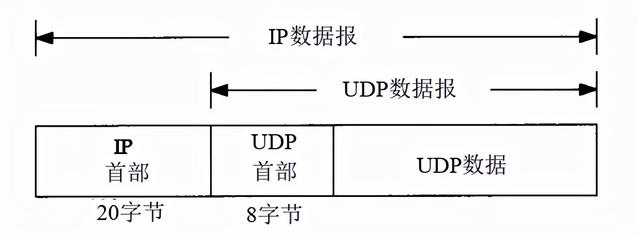

struct udp_header{ _u16 src_port; _u16 dst_port; _u16 length; _u16 check;}; TCP首部:

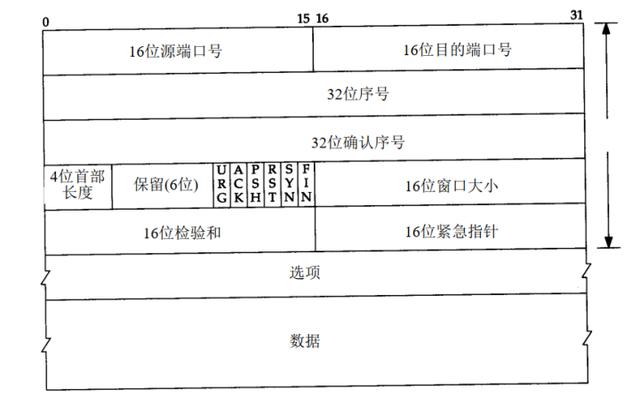
struct tcp_header{ _u16 src_port; _u16 dst_port; _u32 seq_num; _u32 ack_num; _u16 res1 : 4, header_len : 4, fin : 1, syn : 1, rst : 1, psh : 1, ack : 1, urg : 1, res2 : 2; _u16 win_size; _u16 check; _u16 urg_ptr;}; 传输层使用的地址标识为端口。
基于netmap的用户态协议栈实现(一)
这篇文章是协议栈实现的第一部分,我们先简单地实现UDP接收、ARP响应和ICMP响应。
1 上手:实现一个简单的UDP协议数据接收
简单起见,我们先以UDP为例来入手用户栈协议。
测试环境
由于很多因素的影响,一般无法在常见的云服务器上测试netmap。我在虚拟机上的 Ubuntu 运行所编写的用户态协议栈实现程序,然后在Windows 10 上通过网络调试助手发送数据进行测试。我在虚拟机中添加了两个网卡,其中用于测试的网卡配置成了NAT模式(非必须)。一般来说在虚拟机中调用ifconfig会看到虚拟网卡ens33等等,我们需要先将其修改为类似eth0的物理网卡的形式。文中使用的是grub2,而我们的系统可能用的是grub,需要根据实际情况修改,实际只需做前两步就可以了。
UDP数据包封装
首先定义UDP的整个数据包。这里涉及到了柔性数组(零长度数组)用以定义用户数据包的起始地址而不占用实际的结构体空间。
struct udp_packet{ struct eth_header eth; struct ip_header ip; struct udp_header udp; _u8 payload[0]; // 柔性数组}; 代码编写
使用netmap库需包含头文件#include <net/netmap_user.h>,并在这之前添加宏定义NETMAP_WITH_LIBS。
netmap内部接收数据时维护了一个环形缓冲区(ringbuffer)。读数据使用函数nm_nextpkt(),每次读一个数据包。返回的是当前数据在缓冲区中的首地址。
此外,由于网络协议栈中采用的是网络字节序(大端),因此应对数据做适当的字节序转换。
具体的代码如下所示,该程序接收完整的UDP数据包并将具体数据打印出来。关于数据结构的定义前面已给出,下面的代码中就不包含了。
#include <stdio.h>#include <string.h>#include <stdlib.h>#include <sys/poll.h>#include <arpa/inet.h>
#define NETMAP_WITH_LIBS // 使用netmap必须加上#include <net/netmap_user.h>
static int udp_process(_u8* stream){ struct udp_packet* udp = (struct udp_packet*)stream; // 直接取出整个UDP协议下三层的所有首部 int length = ntohs(udp->udp.length); // 整个UDP包的长度,包含了UDP首部 udp->payload[length - sizeof(struct udp_header)] = '\0'; // 首部之后就是数据,此处在数据末尾加一个'\0'以便于调试时通过printf打印 printf("udp recv payload: %s\n", udp->payload);
return 0;}
static int ip_process(_u8* stream){ struct ip_packet* ip = (struct ip_packet*)stream; // 取 eth+ip 首部 if(ip->ip.proto == IPPROTO_UDP) { udp_process(stream); }
return 0;}
int main(){ struct nm_desc *nmr = nm_open("netmap:eth1", NULL, 0, NULL); if(nmr == NULL) return -1;
struct pollfd pfd = {0}; pfd.fd = nmr->fd; // 这个fd实际指向/dev/netmap pfd.events = POLLIN;
while (1) { int ret = poll(&pfd, 1, -1); if(ret < 0) continue;
if(pfd.revents & POLLIN) { struct nm_pkthdr nmhead = {0}; _u8* stream = nm_nextpkt(nmr, &nmhead); // 取一个数据包
struct eth_header* eh = (struct eth_header*)stream; // 先取出链路层首部
if(ntohs(eh->proto) == PROTO_IP) // 验证链路层的协议字段 { ip_process(stream); // IP协议处理 } } } nm_close(nmr);
return 0;} 编译并开始运行该测试程序前,确保/dev/netmap设备已被挂载,如果提示权限问题则需要加sudo运行。
本地使用网络调试助手进行测试,可能你会发现程序没有任何打印,或者一开始正常但过一会儿就接收不到数据了。此时你可能需要先简单了解一下ARP协议。
手动解决ARP失效问题
怎么确定是ARP表出问题了呢?在测试程序运行前,做如下处理。(如果觉得麻烦,可以直接跳过本节,等接下来我们自己实现了ARP协议再进行测试)
我的虚拟机用于测试的网卡是:
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.131.129 netmask 255.255.255.0 broadcast 192.168.131.255 inet6 fe80::5898:dd17:b81e:34dc prefixlen 64 scopeid 0x20<link> ether 00:0c:29:ef:e2:3b txqueuelen 1000 (Ethernet) ...... 在没有运行测试程序前,我们在Windows的cmd(管理员模式)命令行下执行arp -a指令查看ARP表:
......接口: 192.168.131.1 --- 0xc Internet 地址 物理地址 类型 192.168.131.129 00-0c-29-ef-e2-3b 动态 192.168.131.254 00-50-56-e4-2a-ac 动态 192.168.131.255 ff-ff-ff-ff-ff-ff 静态 224.0.0.22 01-00-5e-00-00-16 静态...... 我的Windows用于与虚拟机地址192.168.131.129通信的虚拟网卡 VMnet8 的IP地址为192.168.131.1,如上所示此时是有动态ARP记录的,也能互相ping通。
但测试代码一运行起来后,过一小会儿再次查看ARP表会发现如下所示的结果,动态ARP记录失效了,此时虚拟机上的程序当然无法收到数据了。
......接口: 192.168.131.1 --- 0xc Internet 地址 物理地址 类型 192.168.131.254 00-50-56-e4-2a-ac 动态 192.168.131.255 ff-ff-ff-ff-ff-ff 静态 224.0.0.22 01-00-5e-00-00-16 静态...... 这时,为了测试这个程序,我们可以手动给这个接口增加静态ARP记录。从ifconfig的结果已知目标ip为192.168.131.129,MAC地址为00:0c:29:ef:e2:3b,在cmd下执行下面命令:
> netsh i i show in
Idx Met MTU 状态 名称--- ---------- ---------- ------------ --------------------------- 1 75 4294967295 connected Loopback Pseudo-Interface 1 11 35 1500 connected 以太网 10 35 1500 connected VMware Network Adapter VMnet1 12 35 1500 connected VMware Network Adapter VMnet8 看到VMnet8 对应的 Idx 是12,然后在cmd上执行:
netsh -c "i i" add neighbors 12 “192.168.131.129” “00-0c-29-ef-e2-3b“# 命令格式为 netsh -c "i i" add neighbors <Idx> "IP" "MAC" 这样就可以将记录添加到这个接口的ARP表中,此时类型是静态的。注意Idx要对应上。
接口: 192.168.131.1 --- 0xc Internet 地址 物理地址 类型 192.168.131.129 00-0c-29-ef-e2-3b 静态 <-------------------------- 192.168.131.254 00-50-56-e4-2a-ac 动态 192.168.131.255 ff-ff-ff-ff-ff-ff 静态...... 此时再用网络调试助手去测试就可以正常接收数据了。测试完之后,最好把静态记录删掉改由动态获取:
netsh -c "i i" delete neighbors 12 "192.168.131.129" 当然,如果觉得麻烦,可以等接下来我们自己实现了ARP协议再进行测试!
2 实现ARP协议
ARP全称“地址解析协议”,它为IP地址到对应的MAC地址之间提供动态映射。因为一台主机将以太网数据帧发送到同一局域网内的另一台主机时,是根据6字节的MAC地址来确定目的接口的。对应的还有RARP(逆地址解析协议),即从MAC地址找到IP地址。
设备驱动程序从不检查IP数据包中的目的IP地址。
当一台主机要向另一个IP地址发送数据时,发现自己的ARP表中并没有记录该IP对应的MAC地址,于是就广播这个ARP请求,然后后等待对方的响应。请求的大致意思就是:“如果你是这个IP地址的持有者,请告诉我你的MAC地址”。
ARP协议的报文格式

- 硬件类型:为1表示以太网
- 协议类型:要映射的协议地址类型,0x0800表示IP地址
- 硬件地址长度和协议地址长度,对应MAC地址和IP地址的长度,分别为6和4
- op操作字段:指出4种操作类型:ARP请求(为1)、ARP应答(为2)、RARP请求(为3)、RARP应答(为4)
- 地址:剩下的就是指示发送端和目的端的地址,对于一个ARP请求来说,整个报文中只有目的以太网地址可能是全0的,因为它就是要查询的结果
如此一来,一个ARP请求的工作流程就是:
- 请求端发送一个ARP请求报文,op为1,发送端以太网地址和IP地址就是它自己的地址,目的IP地址为接收端的地址,目的以太网地址为空;
- 接收端收到ARP请求后,将两个发送端地址分别填到目的地址中,然后自己的以太网地址和IP地址填入两个发送端地址字段,记得将op改为2;同时别忘了把以太网首部的地址也做对应修改;最后将报文发送出去。
数据结构定义
struct arp_header{ _u16 hw_type; _u16 proto_type; _u8 hw_addr_len; _u8 proto_addr_len; _u16 op; _u8 src_mac[ETH_LEN]; _u32 src_ip; _u8 dst_mac[ETH_LEN]; _u32 dst_ip;};
struct arp_packet{ struct eth_header eth; struct arp_header arp;}; 代码编写
在正式编写ARP协议的实现代码前,先实现几个辅助函数:
void print_mac(_u8* mac){ int i; for(i = 0; i < ETH_LEN - 1; i++) { printf("%02x:", mac[i]); }
printf("%02x", mac[i]);}
void print_ip(_u32 ip){ _u8* p = (_u8*)&ip int i; for(i = 0; i < IP_LEN - 1; i++) { printf("%d.", p[i]); }
printf("%d", p[i]);}
/* 将字符串表示形式的MAC地址转换成二进制格式 */static int str2mac(_u8* mac, char* macstr){ if(macstr == NULL || mac == NULL) return -1;
char* p = macstr; int idx = 0; _u8 val = 0;
while(*p != '\0' && idx < ETH_LEN) { if(*p != ':') { char c = *p; if(c >= 'a' && c <= 'f') val = (val << 4) + (c - 'a' + 10); else if(c >= 'A' && c <= 'F') val = (val << 4) + (c - 'A' + 10); else if(c >= '0' && c <= '9') // 数字0~9 val = (val << 4) + (c - '0'); else return -1; // 非法字符 } else // 读到一个字节 { mac[idx++] = val; val = 0; }
p++; } if(idx < ETH_LEN) mac[idx] = val; // 最后一个字节 else return -1; // 字节数不对
return 0;} 实现ARP协议,其中发送数据包使用netmap提供的函数nm_inject:
static int arp_process(struct nm_desc *nmr, _u8* stream){ struct arp_packet* arp = (struct arp_packet*)stream; _u16 op = ntohs(arp->arp.op);
// 调试打印 printf("recv arp(op:%d) from ", op);print_mac(arp->arp.src_mac); printf(" (");print_ip(arp->arp.src_ip);printf(") to (");print_ip(arp->arp.dst_ip);printf(")\n");
_u32 localip = inet_addr(SELF_IP); // ip地址由字符串转为二进制 _u8 localmac[ETH_LEN]; // ARP包中的目的PI地址与本机的IP地址是否一致 if(arp->arp.dst_ip != localip) { return -1; } str2mac(localmac, SELF_MAC); // mac地址由字符串转为二进制 printf("confirmed arp to me: ");// 调试打印 print_mac(localmac);printf(" (");print_ip(localip);printf(")\n");
struct arp_packet arp_ack = {0}; if(op == arp_op_request) // ARP请求 { memcpy(&arp_ack, arp, sizeof(struct arp_packet));
memcpy(arp_ack.arp.dst_mac, arp->arp.src_mac, ETH_LEN); // arp报文填入目的 mac arp_ack.arp.dst_ip = arp->arp.src_ip; // arp报文填入目的 ip memcpy(arp_ack.eth.dst_mac, arp->arp.src_mac, ETH_LEN); // 以太网首部填入目的 mac
memcpy(arp_ack.arp.src_mac, localmac, ETH_LEN); // arp报文填入发送端 mac arp_ack.arp.src_ip = localip; // arp报文填入发送端 ip memcpy(arp_ack.eth.src_mac, localmac, ETH_LEN); // 以太网首部填入源 mac
arp_ack.arp.op = htons(arp_op_reply); // ARP响应 } else { // 其他op暂时未实现 printf("op not implemented.\n"); return -1; }
nm_inject(nmr, &arp_ack, sizeof(struct arp_packet)); // 发送一个数据包
return 0;}
int main(){ struct nm_desc *nmr = nm_open("netmap:eth1", NULL, 0, NULL); if(nmr == NULL) return -1;
struct pollfd pfd = {0}; pfd.fd = nmr->fd; // 这个fd实际指向/dev/netmap pfd.events = POLLIN;
while (1) { int ret = poll(&pfd, 1, -1); if(ret < 0) continue;
if(pfd.revents & POLLIN) { struct nm_pkthdr nmhead = {0}; _u8* stream = nm_nextpkt(nmr, &nmhead); // 取一个数据包
struct eth_header* eh = (struct eth_header*)stream; // 先取出链路层首部 _u16 proto = ntohs(eh->proto); if(proto == PROTO_IP) // 验证链路层的协议字段 ip_process(stream); // IP协议处理 else if(proto == PROTO_ARP) arp_process(nmr, stream); // ARP协议处理 else printf("error: unknown protocal.\n"); } } nm_close(nmr);
return 0;} 运行程序,使用网络调试助手发送字符串“hello, 192.168.131.129”,控制台输出:
recv arp(op:1) from 00:50:56:c0:00:08 (192.168.131.1) to (192.168.131.2)recv arp(op:1) from 00:50:56:c0:00:08 (192.168.131.1) to (192.168.131.129)confirmed arp to me: 00:0c:29:ef:e2:3b (192.168.131.129)udp recv payload: hello, 192.168.131.129 3 简单实现ICMP协议
测试程序运行起来后会发现对应的IP地址ping不通,这是因为我们还没实现ICMP协议。
ICMP协议全称Internet控制报文协议,经常被认为属于网络层的一部分,它用于传递差错报文以及查询其他控制信息,供IP层或更高的层次如传输层和应用层使用。我们经常使用的ping指令就是基于ICMP实现的。
ICMP协议的报文格式
ICMP报文在IP数据报中的位置:

ICMP的报文格式:

- ICMP报文类型:8位数据指示的报文类型非常多,此处不一一列举,具体可以参数ICMP类型。我们现在只关心ping的实现,其类型值请求时是8,回显应答时是0;
- 代码:代码字段与类型字段有关,不同的类型下面有不同的代码代表不同的操作,此处我们只关心ping的代码为0;
- 校验和:ICMP报文必须处理校验和,它的计算方法与IP数据报中的首部校验和计算方式是一样,我们之前在处理IP数据报时没有进行处理,此处我们需要实现。
关于ping
ping程序发送的ICMP回显请求和回显应答报文格式如下:
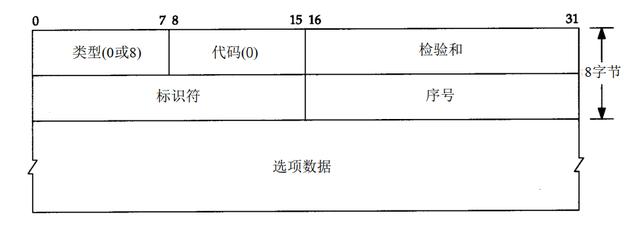
其中增加的标识符和序号字段按照请求端的数据返回就可以了,同时对选项数据也必须进行回显,客户端可以会验证这些数据。序号字段会从0开始,没发送一次请求就会加1.
这里我们发现ping报文的首部是8字节,当我们在ping指令上通过-s指定发送数据大小时,可以看到实际发送数据大小总是比我们指定的多8字节,就是由于这个原因:
$ ping 192.168.131.1 -s 128PING 192.168.131.1 (192.168.131.1) 128(156) bytes of data.136 bytes from 192.168.131.1: icmp_seq=1 ttl=128 time=0.266 ms136 bytes from 192.168.131.1: icmp_seq=2 ttl=128 time=0.901 ms 此外,《TCP/IP详解卷1》中还提到,Unix系统把标识符字段设置成发送进程的PID,以便于区分多个同时发ping包的程序。
数据结构定义
由于只实现ping,我们定义了一个ping的首部。
struct icmp_header{ _u8 type; _u8 code; _u16 checkSum;};
struct icmp_packet{ struct eth_header eth; struct ip_header ip; struct icmp_header icmp_ping;};
struct icmp_ping_header{ struct icmp_header icmp; _u16 identifier; _u16 seq; _u8 data[0];};
struct icmp_ping_packet{ struct eth_header eth; struct ip_header ip; struct icmp_ping_header icmp_ping;}; 代码编写
先实现一个计算16位校验和的辅助函数:
_u8 in_cksum(_u8 *addr, int len){register int nleft = len;register _u8 *w = addr;register int sum = 0;_u8 answer = 0;
while (nleft > 1) {sum += *w++;nleft -= 2;}if (nleft == 1) {*(_u8*)(&answer) = *(_u8*)w ;sum += answer;}
sum = (sum >> 16) + (sum & 0xffff);sum += (sum >> 16);answer = ~sum;return answer;} 实现 ICMP 回显ping报文,调用位置在ip_process,因为它属于网络层:
static int icmp_process(struct nm_desc *nmr, _u8* stream){ struct icmp_packet* icmp = (struct icmp_packet*)stream; _u16 icmp_len = ntohs(icmp->ip.total_len) - icmp->ip.header_len*4; // ip数据报总长度减去ip首部长度得到ICMP报文长度 _u16 icmp_datalen = icmp_len - sizeof(struct icmp_ping_header); // 减掉ICMP首部就是紧跟其后的其他数据长度
if(icmp->icmp.type == 8) // 目前只处理ping请求 { // 加个调试打印 printf("recv ping(icmp_len=%d,datalen=%d) from ", icmp_len, icmp_datalen);print_mac(icmp->eth.src_mac); printf("(");print_ip(icmp->ip.src_ip);printf(")\n");
struct icmp_ping_packet* icmp_ping = (struct icmp_ping_packet*)stream;
// 由于ICMP报文最后带的数据长度是动态变化的,因此此处动态申请内存 _u8* icmp_buf = (_u8*)malloc(sizeof(struct icmp_ping_packet) + icmp_datalen); if(icmp_buf == NULL) return -1; struct icmp_ping_packet* icmp_ping_ack = (struct icmp_ping_packet*)icmp_buf; memcpy(icmp_ping_ack, icmp_ping, sizeof(struct icmp_ping_packet) + icmp_datalen); // 整个请求包拷贝过来再修改
icmp_ping_ack->icmp_ping.icmp.code = 0; // 回显代码是0 icmp_ping_ack->icmp_ping.icmp.type = 0; // 回显类型是0 icmp_ping_ack->icmp_ping.icmp.checkSum = 0; // 检验和先置位0
// 源和目的端IP地址互换,调用数据位置并不影响校验和,因此不需要重新计算IP首部校验 icmp_ping_ack->ip.dst_ip = icmp_ping->ip.src_ip; icmp_ping_ack->ip.src_ip = icmp_ping->ip.dst_ip;
// 源和目的端MAC地址互换 memcpy(icmp_ping_ack->eth.dst_mac, icmp_ping->eth.src_mac, ETH_LEN); memcpy(icmp_ping_ack->eth.src_mac, icmp_ping->eth.dst_mac, ETH_LEN);
icmp_ping_ack->icmp_ping.icmp.checkSum = in_cksum((_u16*)&icmp_ping_ack->icmp_ping, \ sizeof(struct icmp_ping_header) + icmp_datalen); nm_inject(nmr, icmp_buf, sizeof(struct icmp_ping_packet) + icmp_datalen);
free(icmp_buf); }
return 0;}
static int ip_process(struct nm_desc *nmr, _u8* stream){ struct ip_packet* ip = (struct ip_packet*)stream; // 取 eth+ip 首部
switch (ip->ip.proto) { case IPPROTO_UDP: udp_process(stream); break;
case IPPROTO_ICMP: icmp_process(nmr, stream);// 增加 ICMP 处理 break; default: break; }
return 0;} 对上面的代码做几点说明:
- 因为我们响应报文的IP首部中,仅将源和目的端IP地址互换,调换数据位置并不影响校验和结果,因此程序中不需要重新计算IP首部校验;
- 由于ICMP报文最后可带的数据长度是变化的,因此程序中使用动态申请内存的方式接收数据,完了之后记得释放。
测试:
在Windows上发ping包并指定数据包长度(默认32字节):
ping 192.168.131.129 -l 128
正在 Ping 192.168.131.129 具有 128 字节的数据:来自 192.168.131.129 的回复: 字节=128 时间<1ms TTL=128来自 192.168.131.129 的回复: 字节=128 时间=1ms TTL=128来自 192.168.131.129 的回复: 字节=128 时间=2ms TTL=128来自 192.168.131.129 的回复: 字节=128 时间=1ms TTL=128
192.168.131.129 的 Ping 统计信息: 数据包: 已发送 = 4,已接收 = 4,丢失 = 0 (0% 丢失),往返行程的估计时间(以毫秒为单位): 最短 = 0ms,最长 = 2ms,平均 = 1ms 虚拟机上的测试程序打印:
recv ping(icmp_len=136,datalen=128) from 00:50:56:c0:00:08(192.168.131.1)recv ping(icmp_len=136,datalen=128) from 00:50:56:c0:00:08(192.168.131.1)recv ping(icmp_len=136,datalen=128) from 00:50:56:c0:00:08(192.168.131.1)recv ping(icmp_len=136,datalen=128) from 00:50:56:c0:00:08(192.168.131.1) 

