本文主要介绍 Java 中常见容器间的关系和主要区别。 java 中的容器种类很多,且各有特点。为此特意进行学习研究,写下此文,作为一点总结。若有错误,欢迎拍砖。
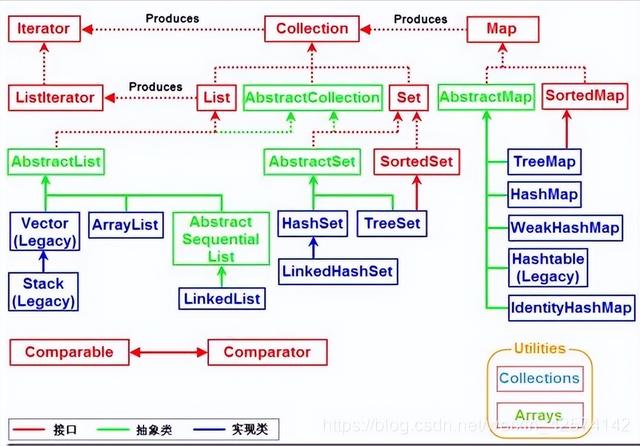
上图是JAVA常见的各个容器的继承关系,我们就顺着继承关系说一下各个接口或者类的特点吧。
Iterable 接口
Iterable是一个超级接口,被Collection所继承。它只有一个方法: Iterator <T> iterator() //即返回一个 迭代器
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为**“轻量级”**对象,因为创建它的代价小。
Java中的Iterator功能比较简单,并且只能单向移动:
(1) 使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是 java.lang .Iterable接口,被Collection继承。
(2) 使用next()获得序列中的下一个元素。
(3) 使用hasNext()检查序列中是否还有元素。
(4) 使用remove()将迭代器新返回的元素删除。
Iterator是Java迭代器最简单的实现,为List设计的 ListIterator 具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
举一个例子来说明迭代器的用法:
public static void main(String args[]) {
List<String> l = new ArrayList<String>();
l.add(“aa”);
l.add(“bb”);
l.add(“cc”);
Iterator iter = l.iterator();
while(iter.hasNext()){
System.out.println((String)iter.next());
}
// for循环的版本
// for(Iterator<String> iter=l.iterator();iter.hasNext();){
// String str = (String)iter.next();
// System.out.println(str);
// }
}
运行结果:
很明显,iterator用于 while 循环更方便简洁一些。
Collection 接口
我们直接打开API文档进行查看

文档中写道, JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set 和 List)实现。也就是一般不会直接使用Collection,而是会使用它的子类,如List或Set。
在图中我标注了4点,不同的Collection子类对于有序性、重复性、null、线程同步都有不同的策略。基于此,Collection的介绍就这样,下面就其具体的子类来进行介绍。
List 接口
List是有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
用户插入的顺序或者指定的位置就是元素插入的位置。它与Set不同,List允许插入重复的值。
List 接口提供了特殊的 迭代 器,称为 ListIterator,除了允许 Iterator 接口提供的正常操作外,该迭代器还允许元素插入和替换,以及双向访问。还提供了一个方法(如下)来获取从列表中指定位置开始的列表迭代器。
ListIterator <E> listIterator(int index)
返回列表中元素的列表迭代器(按适当顺序),从列表的指定位置开始
List 接口提供了两种搜索指定对象的方法。从性能的观点来看,应该小心使用这些方法。在很多实现中,它们将执行高开销的线性搜索。
List 接口提供了两种在列表的任意位置高效插入和移除多个元素的方法。
List的子类
List最流行的实现类有 Vector 、ArrayList、LinkedList。三者的区别将在下文提及。
1.1) ArrayList (类)
ArrayLis是基于数组实现的List类,它封装了一个动态的、增长的、允许再分配的Object[ ]数组.它允许对元素进行快速随机访问
当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
1.2)Vector (类)
Vector与ArrayList一样,也是通过数组实现的,不同的是它支持 线程 的同步,即某一时刻只有一个线程能够写Vector,避免 多线程 同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。所以现在已经不太常用了
1.2.1)Stack (类)
Stack是Vector提供的一个子类,用于模拟”栈”这种数据结构(LIFO后进先出)
1.3)LinkedList (类)
LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。
另外,它还实现了Deque接口,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
关于ArrayList和Vector的区别,再次回顾一下:
名称 扩容方式(默认) 线程安全 速度 有效个数的属性
ArrayList 增长50% 线程不安全 快 size
Vector 增长一倍 线程安全 慢 elementCount
共同点 如果新增的有效元素个数超过数组本身的长度,都会导致数组进行扩容 – remove,add(index,obj)方法都会导致内部数组进行数据拷贝的操作,这样在大数据量时,可能会影响效率 –
写在后面:List接口的排序可以通过Collections.sort()来进行定制排序。
只需要继承Comparable接口后,重写compareTo()**方法。
代码如下:
public class Student extends Thread implements Comparable {
private int age;
private String name;
private String tel;
private int height;
public Student( String name,int age, String tel, int height) {
this.age = age;
this.name = name;
this.tel = tel;
this.height = height;
}
public static void main(String args[]) throws Interrupted Exception {
Student stu1 = new Student(“张三”,21,”156482″,172);
Student stu2 = new Student(“李四”,18,”561618″,168);
Student stu3 = new Student(“王五”,19,”841681″,170);
Student stu4 = new Student(“赵七”,20,”562595″,180);
List<Student> list = new ArrayList<Student>();
//乱序插入
list.add(stu3);
list.add(stu1);
list.add(stu4);
list.add(stu2);
System.out.println(“———–排序前———-“);
Iterator<Student> it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
/*
* 使用Collections的sort方法让集合排序,使用其方法必须要重写
* Comparable接口的compareTo()方法
* */
Collections.sort(list);
System.out.println(“———–按照年龄排序后———-“);
for(int i=0;i<list.size();i++){
System.out.println(list.get(i).toString());
}
}
//重写compareTo方法,用age来比较。也可以用别的来比较
@Override
public int compareTo(Object o) {
//使用当前对象的年龄和其他对象的年龄比较,如果<0返回负数,>0返回正数,=0返回0
int z = this.age – ((Student)o).getAge();
if(z<0)
return -1; // 返回其他负数也行
else if(z == 0)
return 0;
else
return 1; //返回其他正数也行
}
//重写 toString ,便于输出
@Override
public String toString(){
return name+”,”+age+”,”+tel+”,”+height;
}
输出结果如下:
Set接口
Set,顾名思义,集合的意思。java的集合和数学的集合一样,满足集合的无序性,确定性,单一性。所以可以很好的理解,Set是无序、不可重复的。同时,如果有多个null,则不满足单一性了,所以Set只能有一个null。
Set类似于一个罐子,丢进Set的元素没有先后的差别。
Set判断两个对象相同不是使用”==”运算符,而是根据equals方法。也就是说,我们在加入一个新元素的时候,如果这个新元素对象和Set中已有对象进行注意equals比较都返回false,则Set就会接受这个新元素对象,否则拒绝。
——因为Set的这个制约,在使用Set集合的时候,应该注意两点:
为Set集合里的元素的实现类实现一个有效的equals(Object)方法;
对Set的构造函数,传入的Collection参数不能包含重复的元素。
Set的子类
Set最流行的实现类有 HASH Set、TreeSet、LinkedHashSet(从HashSet继承而来)。
1.1) HashSet (类)
HashSet是Set接口的典型实现,HashSet使用HASH算法来存储集合中的元素,因此具有良好的存取和查找性能。当向HashSet集合中存入一个元素时,HashSet会调用该对象的 HashCode ()方法来得到该对象的hashCode值,然后根据该HashCode值决定该对象在HashSet中的存储位置。
值得主要的是,HashSet集合判断两个元素相等的标准是两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法的返回值相等
。
1.1.1)LinkedHashSet(类)
LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但和HashSet不同的是,它同时使用 链表 维护元素的次序,这样使得元素看起来是以插入的顺序保存的。
当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时(遍历)将有很好的性能(链表很适合进行遍历)LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时(遍历)将有很好的性能(链表很适合进行遍历)
1.2) SortedSet (接口):
此接口主要用于排序操作,实现了此接口的子类都属于排序的子类
1.2.1)TreeSet(类)
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态
1.3) EnumSet (类)
EnumSet是一个专门为枚举类设计的集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式、或隐式地指定。EnumSet的集合元素也是有序的,
Queue 接口
此接口用于模拟“队列”数据结构(FIFO)。新插入的元素放在队尾,队头存放着保存时间最长的元素。
Queue的子类、子接口
1.1) PriorityQueue—— 优先队列(类)
其实它并没有按照插入的顺序来存放元素,而是按照队列中某个属性的大小来排列的。故而叫优先队列。
1.2) Deque——双端队列(接口)
1.2.1)ArrayDeque(类)
基于数组的双端队列,类似于ArrayList有一个Object[] 数组。
1.2.2)LinkedList (类)(上文已有,略)
简单回顾一下上述三个接口的区别
容器名 是否有序 是否可重复 null的个数
List 有序 可重复 允许多个null
Set 无序 不可重复 只允许一个null
Queue 有序(FIFO) 可重复 通常不允许插入null
Map 接口
Map不是collection的子接口或者实现类。Map是一个接口。
Map用于保存具有“映射关系”的数据。每个Entry都持有键-值两个对象。其中,Value可能重复,但是Key不允许重复(和Set类似)。
Map可以有多个Value为null,但是只能有一个Key为null。
Map的子类、子接口
1) HashMap (类)
和HashSet集合不能保证元素的顺序一样,HashMap也不能保证key-value对的顺序。并且类似于HashSet判断两个key是否相等的标准一样: 两个key通过equals()方法比较返回true、 同时两个key的hashCode值也必须相等
1.1) LinkedHashMap (类)
LinkedHashMap也使用双向链表来维护key-value对的次序,该链表负责维护Map的迭代顺序,与 key-value 对的插入顺序一致(注意和TreeMap对所有的key-value进行排序区分)。
2) HashTable (类)
是一个古老的Map实现类。
2.1) Properties(类)
Properties对象在处理属性文件时特别方便(windows平台的. ini文件 )。Properties类可以把Map对象和属性文件关联,从而把Map对象的key – value对写入到属性文件中,也可把属性文件中的“属性名-属性值”加载进Map对象中。
3) SortedMap(接口)
如同Set->SortedSet->TreeSet一样,Map也有Map->SortedMap->TreeMap的继承关系。
3.1) TreeMap(类)
TreeMap是一个 红黑树 结构,每个键值对都作为红黑树的一个节点。TreeMap存储键值对时,需要根据key对节点进行排序,TreeMap可以保证所有的key-value对处于有序状态。 同时,TreeMap也有两种排序方式:自然排序、定制排序(类似于上面List的重写CompareTo()方法)。
4) WeakHashMap(类)
看名字就能发现,这是Weak后的HashMap。但是二者大体差别不大。
区别在于,HashMap的key保留了对实际对象的强引用,这意味着只要该HashMap对象不被销毁,该HashMap所引用的对象就不会被垃圾回收。
但WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,当垃圾回收了该key所对应的实际对象之后,WeakHashMap也可能自动删除这些key所对应的key-value对。
5) IdentityHashMap(类)
这个类也和HashMap类似(怎么那么多类似的hhhh),区别在于,在IdentityHashMap中,当且仅当两个key严格相等(key1==key2)时,IdentityHashMap才认为两个key相等
6) EnumMap(类)
EnumMap是一个与枚举类一起使用的Map实现,EnumMap中的所有key都必须是单个枚举类的枚举值。创建EnumMap时必须显式或隐式指定它对应的枚举类。EnumMap根据key的自然顺序存储。


