
试想,8岁的小明是你刚上小学的儿子,长得可爱,古灵精怪,对世界充满好奇。
这天饭后,刚写完家庭作业的小明看到你在书桌前对着电脑眉头紧锁,便跑了过来问你:“爸爸(妈妈),你在做什么呀?”。
身为算法工程师的你正为公司的一个分类项目忙得焦头烂额,听到小明的问话,你随口而出:“分类!”
“分类是什么?”
听到儿子的追问,你的视线终于离开屏幕,但想说的话还没出口又咽了回去……
分类是什么?
简单来说,分类就是对事物进行区分的过程和方法,就是根据文本的特征或属性,划分到已有的类别中。
常用的分类算法包括: 决策树 分类法,朴素的贝叶斯分类算法(native Bayesian classifier)、基于 支持向量机 (SVM)的分类器,神经网络法,k-最近邻法(k-nearest neighbor,kNN),模糊分类法等等
在你眼里乖巧的小明是一个好孩子,同时你也想确保他会在学校做一名“好学生”而不是“坏学生”。这里的区分“好学生”和“坏学生”就是一个分类任务,关于这点,下面的分析可以帮你回答小明的疑问。
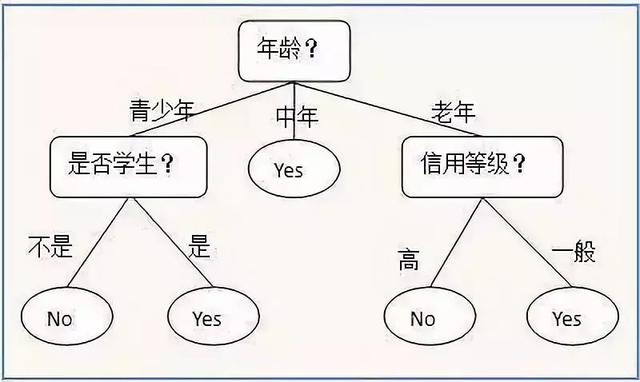
1、决策树
决策树是一种用于对实例进行分类的树形结构。一种依托于策略抉择而建立起来的树。决策树由节点(node)和有向边(directed edge)组成。节点的类型有两种:内部节点和叶子节点。其中,内部节点表示一个特征或属性的测试条件(用于分开具有不同特性的记录),叶子节点表示一个分类。

一旦我们构造了一个决策树模型,以它为基础来进行分类将是非常容易的。具体做法是,从根节点开始,地实例的某一特征进行测试,根据测试结构将实例分配到其子节点(也就是选择适当的分支);沿着该分支可能达到叶子节点或者到达另一个内部节点时,那么就使用新的测试条件递归执行下去,直到抵达一个叶子节点。当到达叶子节点时,我们便得到了最终的分类结果。
从数据产生决策树的机器学习技术叫做决策树学习, 通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来。
分类
理论的太过抽象,下面举两个浅显易懂的例子:
决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么最终满足这些条件的才会选择去见。
2、 贝叶斯
贝叶斯(Bayes)分类算法是一类利用概率统计知识进行分类的算法,如朴素贝叶斯(Naive Bayes)算法。这些算法主要利用Bayes定理来预测一个未知类别的样本属于各个类别的可能性,选择其中可能性最大的一个类别作为该样本的最终类别。由于 贝叶斯定理 的成立本身需要一个很强的条件独立性假设前提,而此假设在实际情况中经常是不成立的,因而其分类准确性就会下降。为此就出现了许多降低独立性假设的贝叶斯分类算法,如TAN(Tree Augmented Na?ve Bayes)算法,它是在贝叶斯网络结构的基础上增加属性对之间的关联来实现的。

通常,事件A在事件B的条件下的概率,与事件B在事件A的条件下的概率是不一样的;然而,这两者是有确定的关系,贝叶斯定理就是这种关系的陈述。
贝叶斯定理是指概率统计中的应用所观察到的现象对有关 概率分布 的主观判断(即先验概率)进行修正的标准方法。当分析样本大到接近总体数时,样本中事件发生的概率将接近于总体中事件发生的概率。
作为一个规范的原理,贝叶斯法则对于所有概率的解释是有效的;然而,频率主义者和贝叶斯主义者对于在应用中概率如何被赋值有着不同的看法:频率主义者根据随机事件发生的频率,或者总体样本里面的个数来赋值概率;贝叶斯主义者要根据未知的命题来赋值概率。
贝叶斯统计中的两个基本概念是先验分布和后验分布:
先验分布。总体分布参数θ的一个概率分布。贝叶斯学派的根本观点,是认为在关于总体分布参数θ的任何统计推断问题中,除了使用样本所提供的信息外,还必须规定一个先验分布,它是在进行统计推断时不可缺少的一个要素。他们认为先验分布不必有客观的依据,可以部分地或完全地基于主观信念。
后验分布。根据样本分布和未知参数的先验分布,用概率论中求 条件概率 分布的方法,求出的在样本已知下,未知参数的条件分布。因为这个分布是在抽样以后才得到的,故称为后验分布。贝叶斯推断方法的关键是任何推断都必须且只须根据后验分布,而不能再涉及样本分布。

贝叶斯公式 为
P(A∩B)=P(A)*P(B|A)=P(B)*P(A|B)
P(A|B)=P(B|A)*P(A)/P(B)
其中:
1、P(A)是A的先验概率或边缘概率,称作”先验”是因为它不考虑B因素。
2、P(A|B)是已知B发生后A的条件概率,也称作A的后验概率。
3、P(B|A)是已知A发生后B的条件概率,也称作B的后验概率,这里称作似然度。
4、P(B)是B的先验概率或边缘概率,这里称作标准化常量。
5、P(B|A)/P(B)称作标准似然度。
贝叶斯法则又可表述为:
后验概率=(似然度*先验概率)/标准化常量=标准似然度*先验概率
P(A|B)随着P(A)和P(B|A)的增长而增长,随着P(B)的增长而减少,即如果B独立于A时被观察到的可能性越大,那么B对A的支持度越小。

贝叶斯公式为利用搜集到的信息对原有判断进行修正提供了有效手段。在采样之前,经济主体对各种假设有一个判断(先验概率),关于先验概率的分布,通常可根据经济主体的经验判断确定(当无任何信息时,一般假设各先验概率相同),较复杂精确的可利用包括最大熵技术或边际分布密度以及相互信息原理等方法来确定先验概率分布。
3、人工神经网络
人工神经网络(Artificial Neural Networks,ANN)是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。在这种模型中,大量的节点(或称”神经元”,或”单元”)之间相互联接构成网络,即”神经网络”,以达到处理信息的目的。神经网络通常需要进行训练,训练的过程就是网络进行学习的过程。训练改变了网络节点的连接权的值使其具有分类的功能,经过训练的网络就可用于对象的识别。
目前,神经网络已有上百种不同的模型,常见的有BP网络、径向基RBF网络、Hopfield网络、随机神经网络(Boltzmann机)、竞争神经网络(Hamming网络,自组织映射网络)等。但是当前的神经网络仍普遍存在收敛速度慢、计算量大、训练时间长和不可解释等缺点。
分类算法
4、k-近邻
k-近邻(kNN,k-Nearest Neighbors)算法是一种基于实例的分类方法。该方法就是找出与未知样本x距离最近的k个训练样本,看这k个样本中多数属于哪一类,就把x归为那一类。k-近邻方法是一种懒惰学习方法,它存放样本,直到需要分类时才进行分类,如果样本集比较复杂,可能会导致很大的计算开销,因此无法应用到实时性很强的场合。
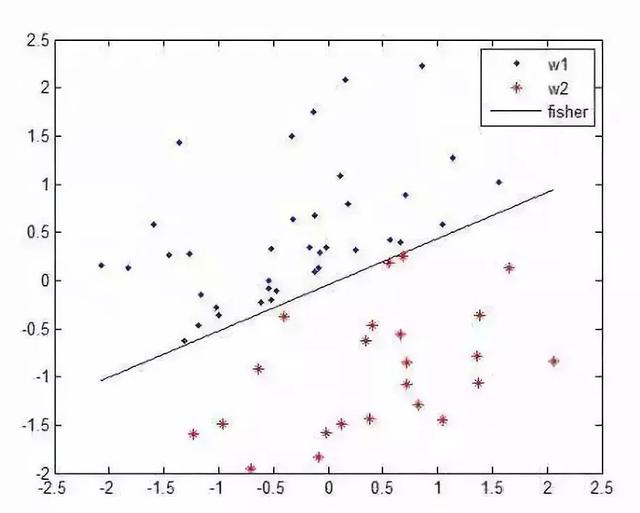
5、支持向量机
支持向量机(Support Vector Machine ,SVM)的主要思想是:建立一个最优决策超平面,使得该平面两侧距离该平面最近的两类样本之间的距离最大化,从而对分类问题提供良好的泛化能力。对于一个多维的样本集,系统随机产生一个超平面并不断移动,对样本进行分类,直到训练样本中属于不同类别的样本点正好位于该超平面的两侧,满足该条件的超平面可能有很多个,SVM正式在保证分类精度的同时,寻找到这样一个超平面,使得超平面两侧的空白区域最大化,从而实现对线性可分样本的最优分类。

支持向量机中的支持向量(Support Vector)是指训练样本集中的某些训练点,这些点最靠近分类决策面,是最难分类的数据点。SVM中最优分类标准就是这些点距离分类超平面的距离达到最大值;“机”(Machine)是机器学习领域对一些算法的统称,常把算法看做一个机器,或者学习函数。SVM是一种有监督的学习方法,主要针对小样本数据进行学习、分类和预测,类似的根据样本进行学习的方法还有决策树归纳算法等。
SVM的优点:
1、不需要很多样本,不需要有很多样本并不意味着训练样本的绝对量很少,而是说相对于其他训练分类算法比起来,同样的问题复杂度下,SVM需求的样本相对是较少的。并且由于SVM引入了 核函数 ,所以对于高维的样本,SVM也能轻松应对。
2、结构风险最小。这种风险是指分类器对问题真实模型的逼近与问题真实解之间的累积误差。
3、非线性,是指SVM擅长应付样本数据线性不可分的情况,主要通过松弛变量(也叫惩罚变量)和核函数技术来实现,这一部分也正是SVM的精髓所在。
分类算法
6、 基于关联规则的分类
关联规则挖掘是数据挖掘中一个重要的研究领域。近年来,对于如何将关联规则挖掘用于分类问题,学者们进行了广泛的研究。关联分类方法挖掘形如condset→C的规则,其中condset是项(或属性-值对)的集合,而C是类标号,这种形式的规则称为类关联规则(class association rules,CARS)。关联分类方法一般由两步组成:第一步用关联规则挖掘算法从训练数据集中挖掘出所有满足指定支持度和置信度的类关联规则;第二步使用启发式方法从挖掘出的类关联规则中挑选出一组高质量的规则用于分类。
最后,如果你跟我一样都喜欢 python ,想成为一名优秀的程序员,也在学习python的道路上奔跑,欢迎你加入java学习群:839383765 群内每天都会分享最新业内资料,分享python免费课程,共同交流学习,让学习变(编)成(程)一种习惯!


