高并发是什么?
⾼并发(High Concurrency)是互联⽹分布式系统架构设计中必须考虑的因素之⼀,它通常是指通过设计保证系统能够同时并⾏处理很多请求。
高并发属性和因素
⾼并发相关常⽤的⼀些指标有响应时间(Response Time),吞吐量(Throughput,eg. RPS),每 秒查询率 QPS(Query Per Second),并发⽤户数等。
- 响应时间(RT) : 系统对请求做出响应的时间。例如系统处理⼀个 HTTP 请求需要 200ms,这个200ms是系统的响应时间。
- 吞吐量 : 单位时间内处理的请求数量。
- QPS : 每秒响应请求数。在互联⽹领域,这个指标和吞吐量区分的没有这么明显。
- 并发⽤户数 : 同时承载正常使⽤系统功能的⽤户数量。例如即时通讯系统,同时在线量就****代表了系统的并发⽤户数。
高并发容错技术
高并发容错技术主要是指在高并发场景下的技术实现和解决如何在发生错误的场景下,仍然可以保证系统可以正常运行的技术手段和设计实现方案。
雪崩效应

如何容错
- 超时
- 限流
- 舱壁模式
断路器
断路器转换示意图

断路器
组件名称 | Hystrix | Sentinel | Resilience4J |
超时机制 | 线程池 模式有timeout | 暂时支持得不好 | 通过限时器实现,此外也有线程池模式 |
限流 | 采用线程池和信号量限流 | 采用信号量机制限流 | 采用线程池和信号量限流 |
仓壁模式 | 采用线程池模式实现隔离 | 暂时支持的不好 | 采用线程池模式实现隔离 |
断路器 | 采用了开关进行模式 | 暂时支持的不好 | 采用了开关进行模式 |
异步化
本地调⽤异步化
- 创建⼀个 线程 ,将耗时操作放到独⽴的线程中执⾏【不建议使⽤】
- 使⽤线程池创建线程
- @Async注解(尽量把@Async注解标注的⽅法,独⽴到⼀个类⾥⾯去,防⽌this调⽤导致⽆效)
远程操作异步化
- 采用-AsyncRestTemplate
不阻塞当前的业务线程执行,不会造成阻塞和雪崩。
ListenableFuture<ResponseEntity<String>> future =
asyncRestTemplate.getForEntity("#34;, String .class);
future.addCallback(new ListenableFutureCallback<ResponseEntity<String>>() {
//调⽤失败
@Override
public void onFailure(Throwable ex) {
System.out.println("失败");
}
//调⽤成功
@Override
public void onSuccess(ResponseEntity<String> result) {
System.out.println(result.getBody());
}
});
ResponseEntity<String> entity = future.get();
String body = entity.getBody();
System.out.println(body);
复制代码 - 采用-WebClient
- maven 依赖
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webflux</artifactId>
</dependency>
<dependency>
<groupId> IO .projectreactor.netty</groupId>
<artifactId>reactor-netty</artifactId>
</dependency>
复制代码 - 代码实现
Mono<String> mono = this.webClient.get().uri("#34;).retrieve()
.bodyToMono(String.class);
HashMap <Object, Object> map = new HashMap<>();
map.put("addressId","demoData");
map.put("userId","demoData");
map.put("receiver","demoData");
map.put("mobile","15151816012");
map.put("province","demoData");
map.put("city","demoData");
map.put("district","demoData");
map.put("detail","demoData");
Mono<String> mono = this.webClient.post().uri("#34;)
.contentType(MediaType.APPLICATION_JSON_UTF8)
.body(BodyInserters.fromObject(map))
.retrieve().bodyToMono(String.class);
return mono.block();
复制代码 其他异步实现机制介绍
- 基于 MQ 实现异步化
- ⽆阻塞编程
- Reactive Stream编程模型
- RxJava2/RxJava3编程模型
- 无锁编程Disruptor编程模型
池化技术改善资源
- 对象池:享元模式
- 线程池:生产者/消费者模式
- 连接池:资源复用模式
缓存提升应用性能
- Ehcache :
- Memcached :
- Redis : redis
缓存优化问题-如何提升命中率
- 缓存场景要⽤对——读多写少使⽤缓存才有意义
- 合理的粒度
- key:userId value:user对象
- key:users value:[user1,user2,user3]
- 前者,当且仅当该user发⽣变化缓存更新;后者任意⼀个user发⽣变化缓存都要更新,命中率往往相对较低
- 缓存容量
- ⼀旦缓存存储达到⼀定 阈值 ,就会淘汰数据,缓存算法:LRU/LFU/FIFO等等。
- 为你的缓存集群做好容量规划。
- 故障问题
- 例如:某个缓存实例挂了,此时也会影响命中率
- 故障转移、⾼可⽤很重要
- 迁移/扩容缩
- 不管是⼀致性 hash ,还是hash槽算法,都有⼀定的数据需要搬迁。
缓存错误问题-缓存雪崩
缓存雪崩是当Redis等缓存服务器挂了,客户端直接请求到数据库⾥⾯。数据库负载⾮常⾼。甚⾄数据库拖挂了。
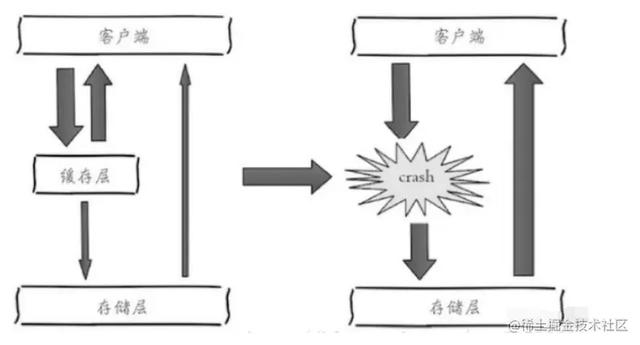
- 优化⽅法:保持缓存层服务器的⾼可⽤。 监控、集群、哨兵。当集群⾥有服务器有问题,让哨兵****踢出去。
- 依赖隔离组件为后端限流并降级。 ⽐如推荐服务中,如果个性化推荐服务不可⽤,可以降级为热****点数据。
提前演练。演练缓存层crash后,应⽤以及后端的负载情况以及可能出现的问题。 对此做⼀些预案设定。
- ⽆底洞问题
2010年, Facebook 有了3000个Memcached节点,他们发现加机器性能没能提升反⽽下降。
例如:要想对Redis执⾏mget操作,或者在 Cluster 上实现mget的效果,在集群上执⾏的性能⽐单机 差,⽽且随着节点的增加,性能会越来越差(如果⽤并⾏IO的⽅案,那么⽹络时间复杂度就会从O(1) 变成O(node)
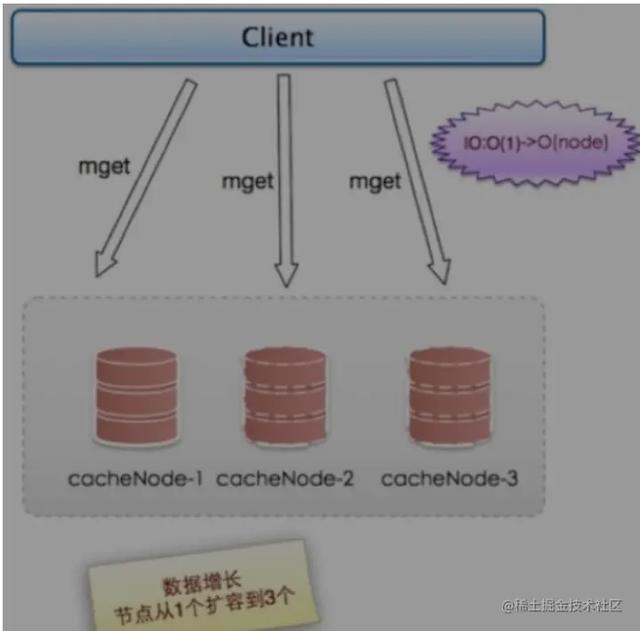
分析总结
- 更多的机器 != 更⾼的性能
- 批量接⼝需求(mget/mset)等,机器越多可能性能越差
- 数据增⻓和⽔平扩展的需求,随着业务量增⼤,就是要⽔平扩容
优化IO的⼏种⽅法:
- 命令本身的优化:例如慢查询keys、hgetall bigkey等等,性能本身就差,要慎⽤
- 减少⽹络通信次数
- 降低接⼊成本:例如客户端⻓连接/连接池、NIO等
- 热点key的重建优化
问题描述:热点key + 较⻓的重建时间
新浪微博 有个⼤V发了⼀条微博,很多⼈去访问,但是可能缓存的设置(或重建)过程是⽐较慢 的,那么就可能导致⼤量的线程都会查询数据源,对数据源压⼒很⼤,⽽且响应⾮常慢

- 减少缓存重建的次数
- 数据尽可能⼀致
- 互斥锁(读写锁)
- 永远不过期
- 分布式锁方案
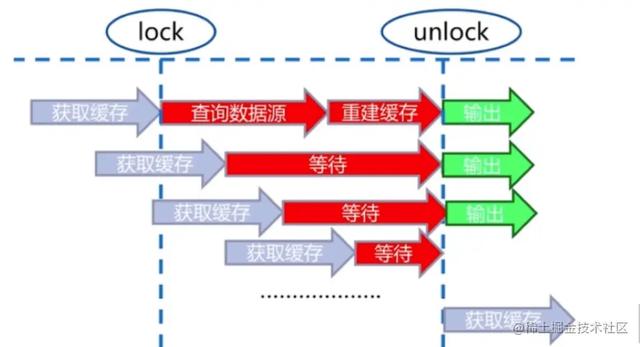
- 可能会有⼤量的线程阻塞住
- 可能存在 死锁 问题
- 永远不过期
- 缓存层⾯:不设置过期时间(不设置expire)
- 功能层⾯:为每个value添加逻辑过期时间,⼀但发现超过逻辑过期时间后,就使⽤单独的线程构建缓存。
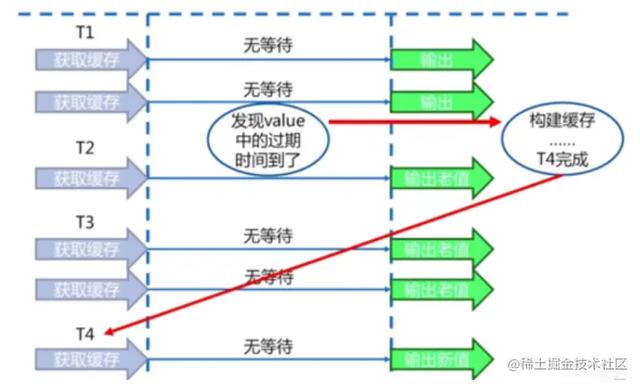
- 可能存在的问题
- 数据可能会不⼀致
- 额外的编码⼯作
方案 | 优点 | 缺点 |
互斥锁 | 思路简单、保证一致性 | 容易死锁、性能较差 |
永不过期 | 基本可以杜绝热点key问题 | 无法保证一致性、需要独立功能维护缓存 |
缓存错误问题-缓存穿透
缓存穿透是指查询⼀个⼀定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写⼊缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿透。
如图,如果⽤户通过某个条件,查询缓存没有查到数据,然后查询数据库也没有查到结果,于是数据库直接返回。下⼀次,⽤户继续通过这个条件再去查询,缓存中依然不会有结果,⼜会查询到数据库。如果有⼤量的请求⽆法命中,就可能打穿数据库。
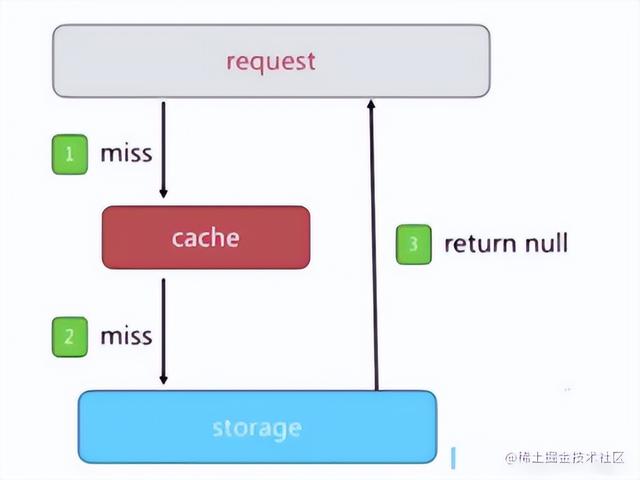
- 业务代码⾃身问题
- 例如调⽤别⼈的接⼝,别⼈的接⼝有问题,那我这边拿到的就是个异常或者null,此时我这边没办法对别⼈接⼝的存储层进⾏缓存恶意hinting、爬⾍等等,例如前端随机⽤⼀个uuid去查询⽂章内容。
- 观察业务响应时间
- 响应时间突然过慢,那么可能出现了穿透问题
- 业务本身出现了问题
相关指标:总调⽤数、缓存层命中数、存储层命中数
- 解决⽅案
- 缓存空对象

- 存在的问题:
- 需要更多的key
- ⼀般会设置过期时间
- 缓存层和存储层数据“短期”不⼀致
例如调⽤的是⼀个接⼝,接⼝开始挂了,返回null,redis将null给缓存起来了。后来接⼝恢复了正常,存储层也是有数据的,但在缓存过期之前,客户端依然只会接收到null,⽽并⾮接⼝返回的数据。 可以在接⼝正常时,刷新⼀下缓存。(可以考虑在更新或者新增操作的时候删除缓存)。
- 布隆过滤器
- 对所有可能查询的参数以hash形式存储,在控制层先进⾏校验,不符合则丢弃。还有最常⻅的则是采⽤布隆过滤器,将所有可能存在的数据哈希到⼀个⾜够⼤的bitmap中,⼀个⼀定不存在的数据会被这个bitmap拦截掉,从⽽避免了对底层存储系统的查询压⼒。
- 存在问题
- 对于频繁更新的数据,很难实时构建布隆过滤器。⼀般都是对不太容易变化的数据集使⽤布隆过滤器。
原文链接:


