创建了一个T表,就产生了一个T表的表段,当在T 表的某些列上创建了索引IDX_T,就产生了一个IDX_T 的索引段。
索引是建在表的具体列上的,其存在的目的是让表的查询变得更快,效率更高。表记录丢失关乎生死,而索引丢失只需重建即可。
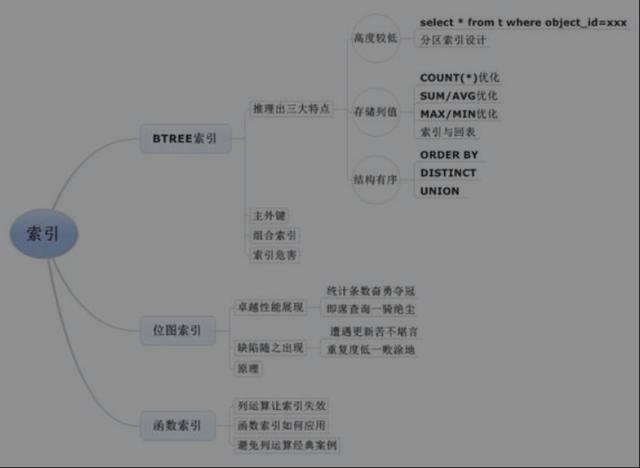
索引结构图
索引是由Root(根块)、Branch(茎块)和Leaf(叶子块)三部分组成的,其中Leaf(叶子块)主要存储了key column value(索引列具体值),以及能具体定位到数据块所在位置的rowid(注意区分索引块和数据块)。
select * from t whereid=12;,该t表的记录有10 050条,而id=12仅返回1条,在t表的id列上创建了一个索引。
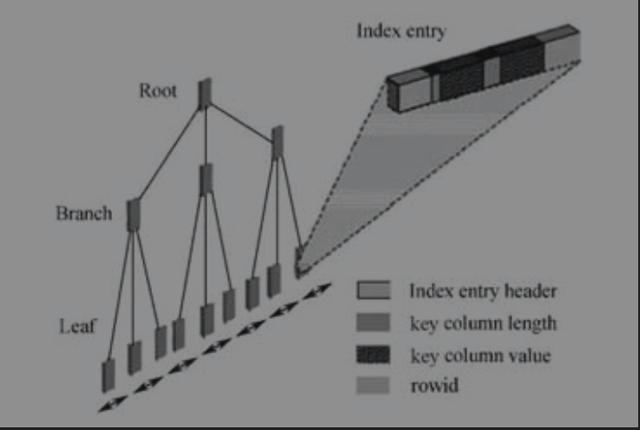
定位到select * from t where id=12;大致需要3个IO(只是举一个例子,1万多条记录实际情况可能只需要2个IO,这个和索引的高度有关)。首先查询定位到索引的根部,这是第1次IO;接下来根据根块的数据分布,定位到索引的茎部(查询到12的值的大致范围,在11..19的部分),这是第2次IO;然后定位到叶子块,找到 id=12的部分,此处为第3次 IO。假设 Oracle 在全表扫描记录,遍历所有的数据块,IO的数量必然将大大超过3次。有了这个索引,Oracle只会去扫描部分索引块,而非全部,少做事,必然能大大提升性能。
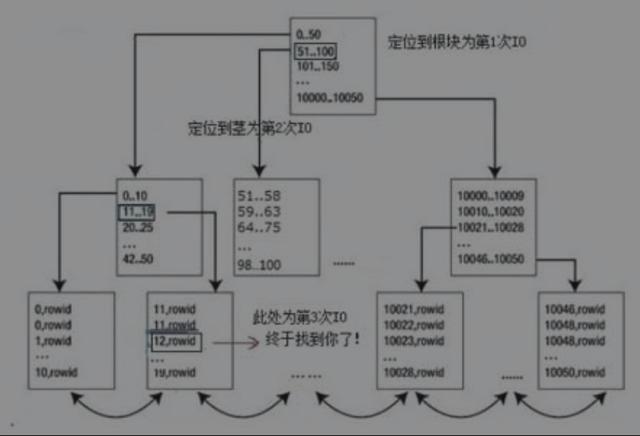
索引查询示例图
select * from t where id=12;,*表示要展现t表的所有字段,只访问索引是不可能包含表的所有字段的,因为该索引只是对id列建索引,只存储了id列的信息而已。因此上述查询访问完索引块后,必然要再访问数据块,比较快捷的方法是用索引块存储的rowid来快速检索数据块,由此证明之前假想的3次IO是错误的,理应增加一次从索引块到数据块获取其他各列信息的检索动作,至少是4次IO才对。
查询可以只访问索引而不访问表
查询只检索索引列信息,就可以不访问表,比如查询改成select id from t where id=12;时就是这种情况
Leaf(叶子块)主要存储key column value(索引列具体值)以及能具体定位到数据块所在位置的rowid(注意区分索引块和数据块)。
到底是物理结构还是逻辑结构
1.要建索引先排序
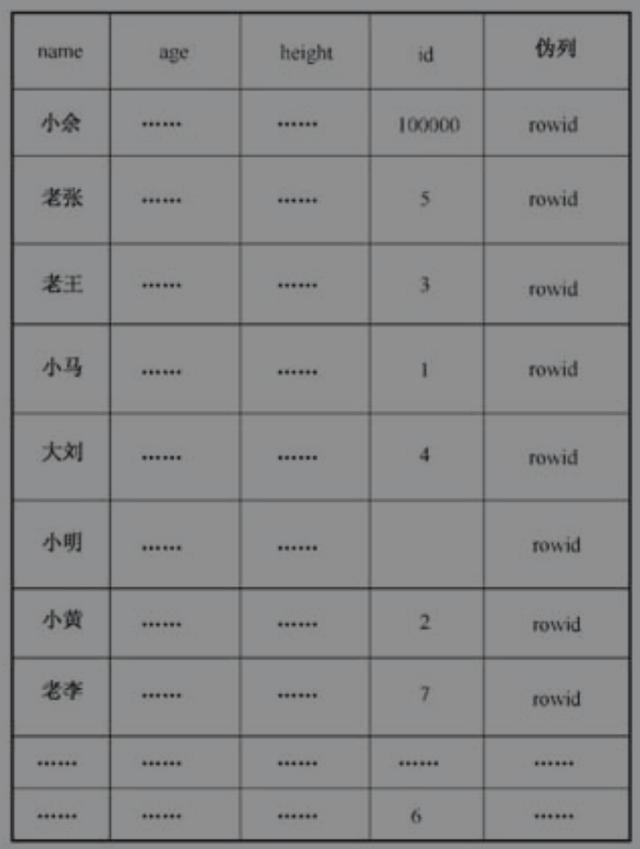
未建索引的test表
建索引后,将test表中id列的值按顺序取出放在内存中(除了id列的值外,还要注意取该列的值的同时,该行的rowid也被一并取出)。
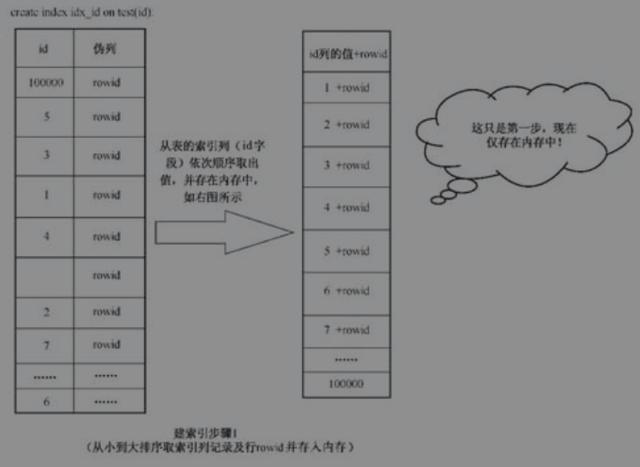
建索引步骤1
2.列值入块成索引
依次将内存中顺序存放的列值和对应的rowid存进Oracle空闲的块中,形成索引块。
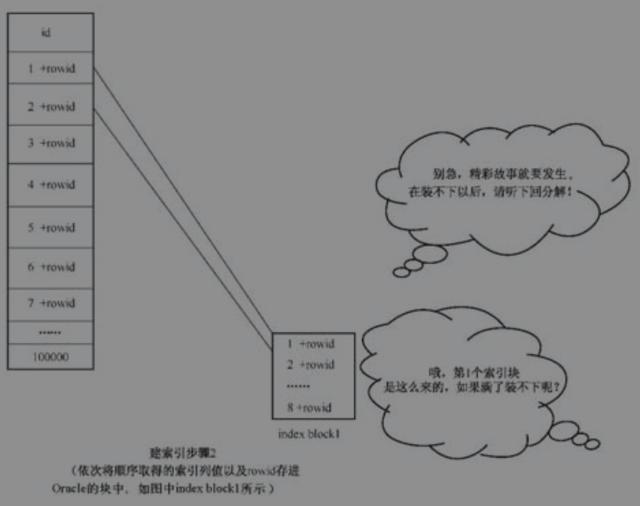
建索引步骤2
3.填满一块接一块
随着索引列的值的不断插入,index block1(L1)很快就被插满了。比如接下来取出的 id=9的记录无法插入index block1(L1)中,就只能插入新的块中,插入index block2(L2)。
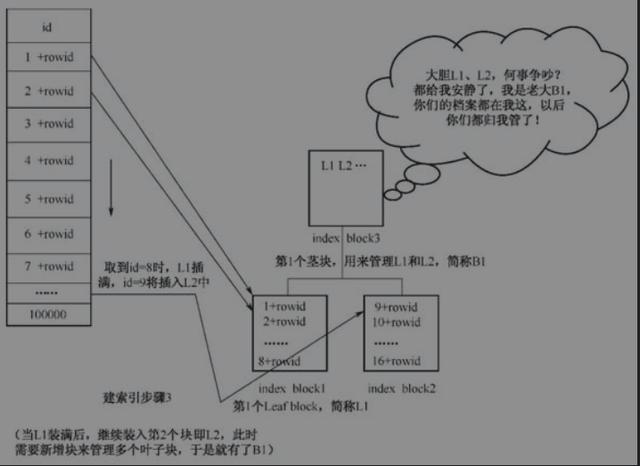
建索引步骤3
4.同级两块需人管

建索引步骤4


