前文《 》介绍过InnoDB引擎的索引是以B+树结构进行组织的,默认根据主键创建的索引是聚集索引,数据都在叶子节点中。根据主键以外的字段创建的索引是非聚集索引,叶子节点中保存的值是主键值。本文通过一个实例详细描述索引的使用方式。
主键索引
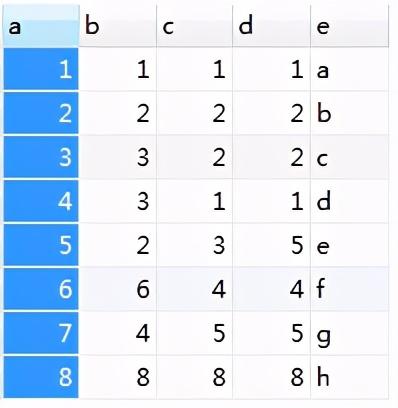
假如数据库中有表 t1 ,共有5个属性,如下表。其中属性 a 是自增的Integer类型,且是唯一的,非常适合作为主键类型。
在没有建立索引的时候,查询数据都要进行全表扫描。比如:
explain SELECT * FROM ‘t1’ WHERE a=2
Mysql数据库 explain 指令输出的 type 字段表示数据库引擎查找表的一种方式, ALL 表示全表扫描。
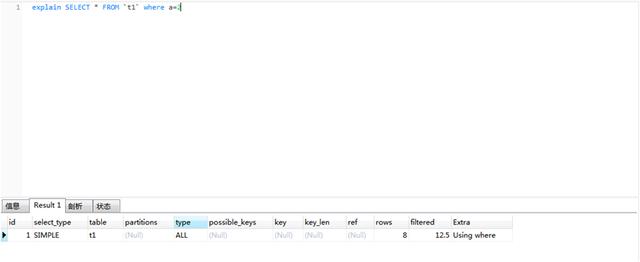
type=all 表示全表扫描
由属性a为数据表t1添加主键,默认会创建一个主键索引。
alter table t1 add primary key (a)
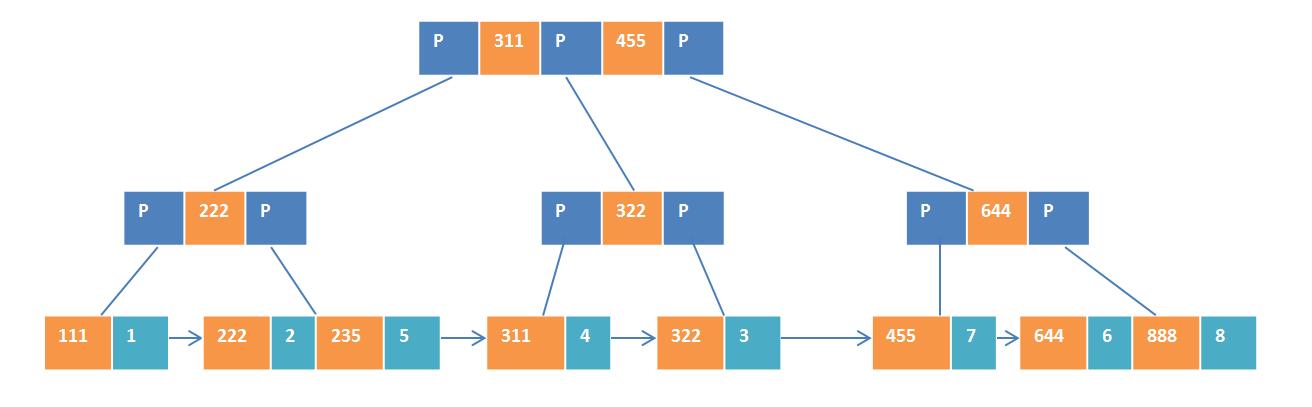
在InnoDB引擎中会建立一个主键索引的B+树,如下图所示。

主键索引的B+树结构
再次运行上面的查询,会发现查询已经经过索引,不再通过全表扫描。将主键索引或者UNIQUE索引放到 where 条件中查询,mysql优化器就能把这次查询优化转化为一个常量。
explain SELECT * FROM ‘t1’ WHERE a=2

type=const 表示主键索引查询
通过索引查询,扫描到的行只有1行,比起全表扫描少了非常多, 扫描的行数越少,意味着访问磁盘数据的次数越少,查询效率更高。
联合索引
上面的索引只是对一个列建立了索引,因此也是一个单列索引。InnoDB引擎还允许对多列建立索引。比如我们可以对 (b, c, d) 三列建立索引。
alter table t1 add index (b,c,d)
这个联合索引是一个非聚集索引,建立的B+树叶子节点中没有实际的数据,只有主键的值。
辅助索引
我们建立的联合索引,相当于建立了三个索引: b列 索引、 (b, c) 索引、 (b, c, d) 索引。如果我们以这三种情况作为查询条件,那么都有可能按照索引进行查找,这就是 最左前缀匹配原则 。
这是由B+树的构造决定的,其他列在B+树索引中都是乱序的,没法通过索引快速查找,还不如全表扫描。
我们以 b列 作为查询条件,可以看到是依据索引进行查询的。type= ref 表示查找条件列使用了不为主键和unique键的索引。
explain SELECT * FROM t1 WHERE b=2

以列b作为查询条件,走了联合索引
我们以 (b, c) 列作为查询条件,由于我们的查询条件中有大于号,因此 type= range ,表示按照有范围的索引扫描。
explain SELECT * FROM t1 WHERE b=1 AND c>2

以列(b, c)作为查询条件,也走了联合索引
要注意联合索引的列的顺序是非常关键的。如果以中间的c列作为查询条件,是无法用到联合索引的,因为在联合索引的B+树中,c列的值的顺序是乱序的。
explain SELECT * FROM t1 WHERE c=2

以c列作为查询条件,无法用到联合索引
何时会使用索引查询
其实并不一定查询条件的列在索引中,就一定会走索引查询。比如下面的这条查询就是按照全表扫描的。
explain SELECT * FROM `t1` WHERE b>1

全表扫描
查询条件稍微换一下:
explain SELECT * FROM `t1` WHERE b>7
这条查询就可以看到联合索引起作用了。

联合索引查找
在数据库里面,扫描行数是影响执行代价的重要因素之一。数据库在执行查询时,优先选择执行代价或者说是成本最低的方式,如果全表扫描的代价小于索引扫描,那么就会选择进行全表扫描。
在上面的两个查询语句中,第一个查询条件b>1的搜索范围非常大,如果用联合索引的话,仍然要把联合索引的叶子节点全部遍历一遍,之后再到聚集索引中找到数据记录,还不如直接在聚集索引中进行全表扫描。
第二个查询条件b>7的搜索范围就很小,如果用联合索引可以快速地定位到一个叶子节点,然后再去聚集索引中找到对应的数据记录。使用联合索引的代价更低,就使用联合索引。所以我们在执行查询时,要尽量将查询条件写得精准,这样才可以利用索引提高搜索效率。
一条SQL语句可能会命中多个索引,InnoDB引擎会交由优化器来选择合适的索引。优化器选择索引的目的,就是要找到一个最优的执行方案,并用最小的代价去执行SQL语句。
我会持续更新关于物联网、云原生以及数字科技方面的文章,用简单的语言描述复杂的技术,也会偶尔发表一下对IT产业的看法, 欢迎大家关注、转发和评论 ,谢谢。


