遇到了一个 glibc 导致的内存回收问题,查找原因和实验的的过程是比较有意思的,主要会涉及到下面这些:
- Linux 中典型的大量 64M 内存区域问题
- glibc 的内存分配器 ptmalloc2 的底层原理
- 如何写一个自定义的 malloc hook 动态链接库 so
- glibc 的内存分配原理(Arena、Chunk 结构、bins 等)
- malloc_trim 对内存真正回收的影响
- gdb 的 heap 调试工具使用
- jemalloc 库的介绍与应用
背景
前段时间有同学反馈一个 java RPC 项目在容器中启动完没多久就因为容器内存超过配额 1500M 被杀,我帮忙一起看了一下。
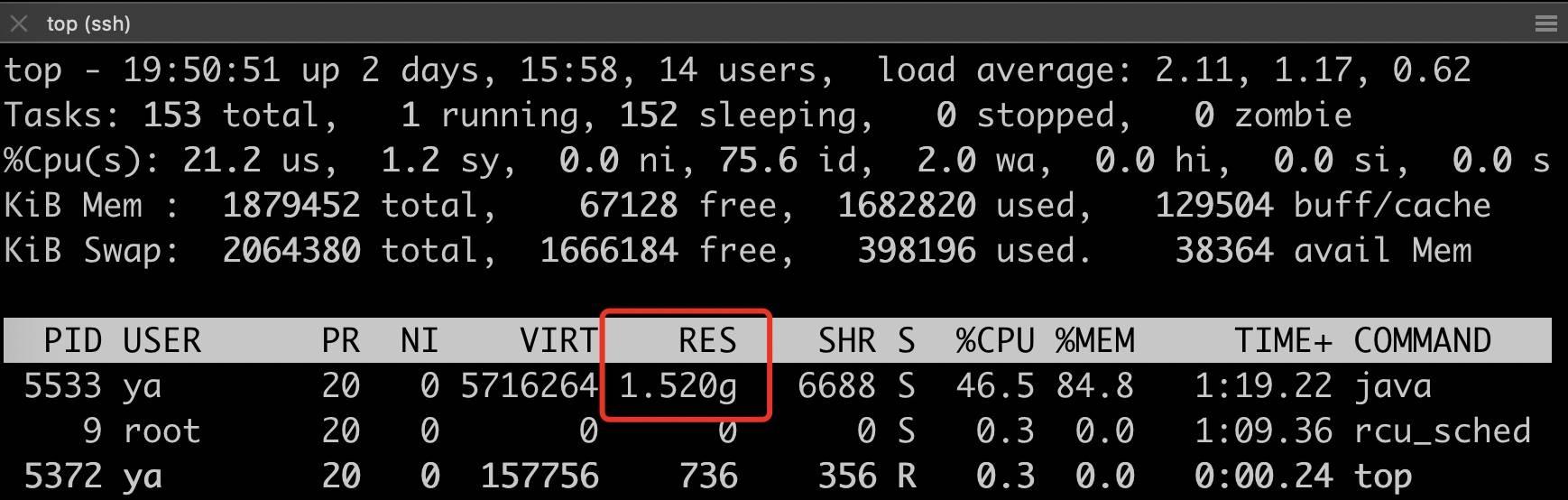
在本地 Linux 环境中跑了一下,JVM 启动完通过 top 看到的 RES 内存就已经超过了 1.5G,如下图所示。
首先想到查看内存的分布情况,使用 arthas 是一个不错的选择,输入 dashboard 查看当前的内存使用情况,如下所示。
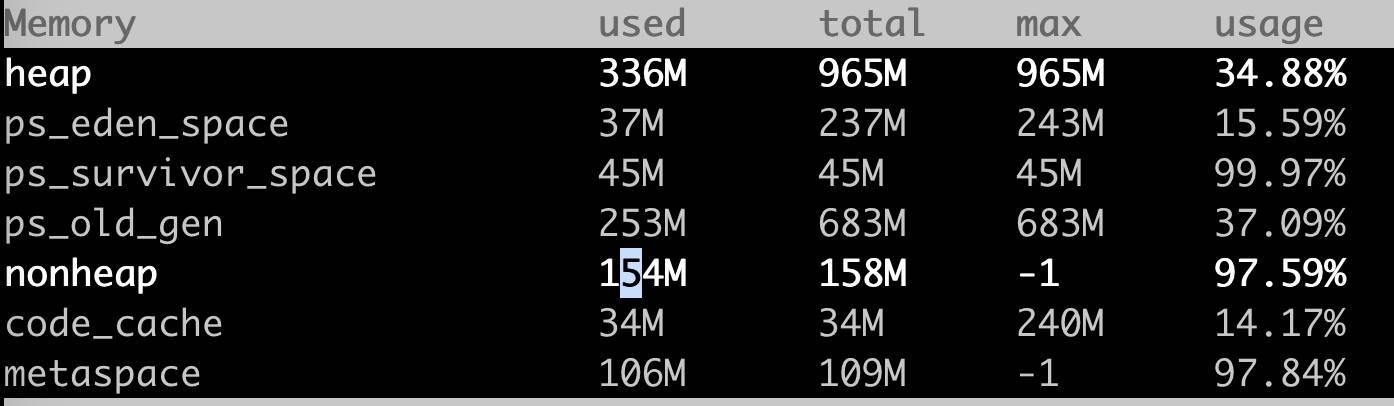
可以看到发现进程占用的堆内存只有 300M 左右,非堆(non-heap)也很小,加起来才 500 M 左右,那内存被谁消耗了。这就要看看 JVM 内存的几个组成部分了。
JVM 的内存都耗在哪里
JVM 的内存大概分为下面这几个部分
- 堆(Heap):eden、metaspace、old 区域等
- 线程 栈(Thread Stack):每个线程栈预留 1M 的线程栈大小
- 非堆(Non-heap):包括 code_cache、metaspace 等
- 堆外内存:unsafe.allocateMemory 和 DirectByteBuffer 申请的堆外内存
- native (C/C++ 代码)申请的内存
- 还有 JVM 运行本身需要的内存,比如 GC 等。
接下来怀疑堆外内存和 native 内存可能存在泄露问题。堆外内存可以通过 开启 NMT(NativeMemoryTracking) 来跟踪,加上 -XX:NativeMemoryTracking=detail 再次启动程序,也发现内存占用值远小于 RES 内存占用值。
因为 NMT 不会追踪 native (C/C++ 代码)申请的内存,到这里基本已经怀疑是 native 代码导致的。我们项目中除了 rocksdb 用到了 native 的代码就只剩下 JVM 自己了。接下来继续排查。
Linux 熟悉的 64M 内存问题
使用 pmap -x 查看内存的分布,发现有大量的 64M 左右的内存区域,如下图所示。
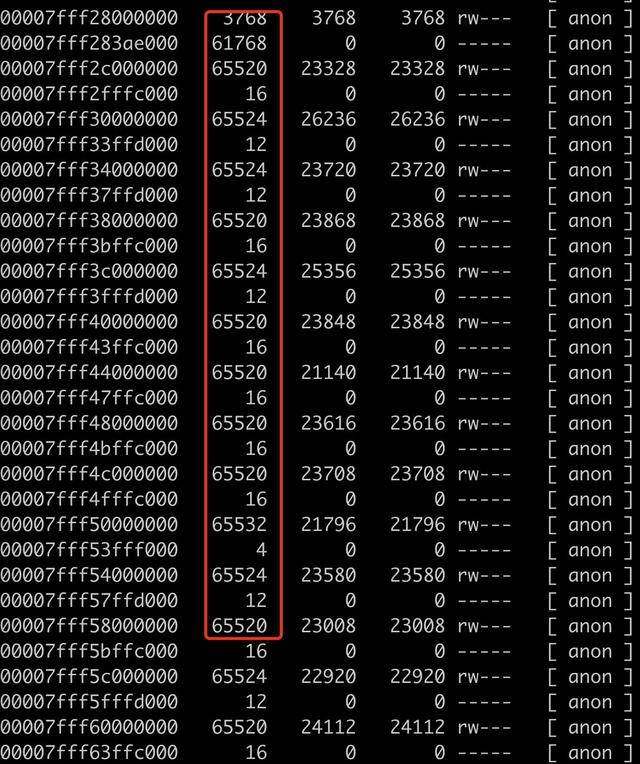
这个现象太熟悉了,这不是 linux glibc 中经典的 64M 内存问题吗?
pt malloc 2 与 arena
Linux 中 malloc 的早期版本是由 Doug Lea 实现的,它有一个严重问题是内存分配只有一个分配区(arena),每次分配内存都要对分配区加锁,分配完释放锁,导致多线程下并发申请释放内存锁的竞争激烈。arena 单词的字面意思是「舞台;竞技场」,可能就是内存分配库表演的主战场的意思吧。
于是修修补补又一个版本,你不是多线程锁竞争厉害吗,那我多开几个 arena,锁竞争的情况自然会好转。
Wolfram Gloger 在 Doug Lea 的基础上改进使得 Glibc 的 malloc 可以支持多线程,这就是 ptmalloc2。在只有一个分配区的基础上,增加了非主分配区(non main arena),主分配区只有一个,非主分配可以有很多个,具体个数后面会说。
当调用 malloc 分配内存的时候,会先查看当前线程私有变量中是否已经存在一个分配区 arena。如果存在,则尝试会对这个 arena 加锁
- 如果加锁成功,则会使用这个分配区分配内存
- 如果加锁失败,说明有其它线程正在使用,则遍历 arena 列表寻找没有加锁的 arena 区域,如果找到则用这个 arena 区域分配内存。
主分配区可以使用 brk 和 mmap 两种方式申请虚拟内存,非主分配区只能 mmap。glibc 每次申请的虚拟内存区块大小是 64MB,glibc 再根据应用需要切割为小块零售。
这就是 linux 进程内存分布中典型的 64M 问题,那有多少个这样的区域呢?在 64 位系统下,这个值等于 8 * number of cores,如果是 4 核,则最多有 32 个 64M 大小的内存区域。
难道是因为 arena 数量太多了导致的?
设置 MALLOC_ARENA_MAX=1 有用吗?
加上这个环境变量启动 java 进程,确实 64M 的内存区域就不见了,但是集中到了一个大的接近 700M 的内存区域中,如下图所示。
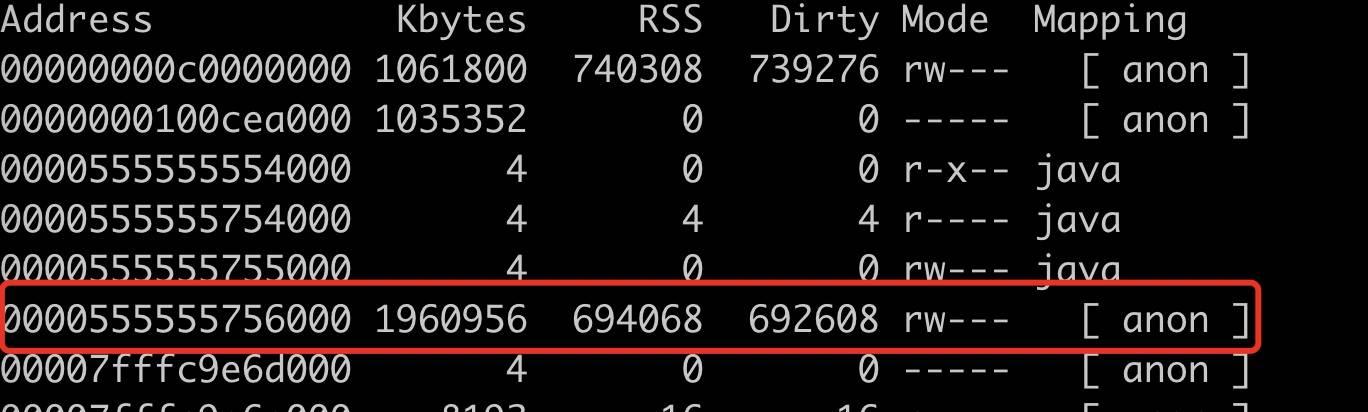
到这里,内存占用高的问题并没有解决,接下来继续折腾。
是谁在分配释放内存
接下来,写一个自定义的 malloc 函数 hook 。hook 实际上就是利用 LD_PRELOAD 环境变量替换 glibc 中的函数实现,在 malloc、free、realloc、calloc 这几个函数调用前先打印日志然后再调用实际的方法。 以 malloc 函数的 hook 为例,部分代码如下所示。
// 获取线程 id 而不是 pid
static pid_t gettid() {
return syscall(__NR_gettid);
}
static void *(*real_realloc)(void *ptr, size_t size) = 0;
void *malloc(size_t size) {
void *p;
if (!real_malloc) {
real_malloc = dlsym(RTLD_NEXT, "malloc");
if (!real_malloc) return NULL;
}
p = real_malloc(size);
printLog("[0x%08x] malloc(%u)t= 0x%08x ", GETRET(), size, p);
return p;
}
复制代码
设置 LD_PRELOAD 启动 JVM
LD_PRELOAD=/app/my_malloc.so java -Xms -Xmx -jar ....
复制代码
在 JVM 启动的过程中同时开启 jstack 打印线程堆栈,当 jvm 进程完全启动以后,查看 malloc 的输出日志和 jstack 的日志。
这里输出了一个几十 M 的 malloc 日志,内容如下所示。日志的第一列是线程 id。
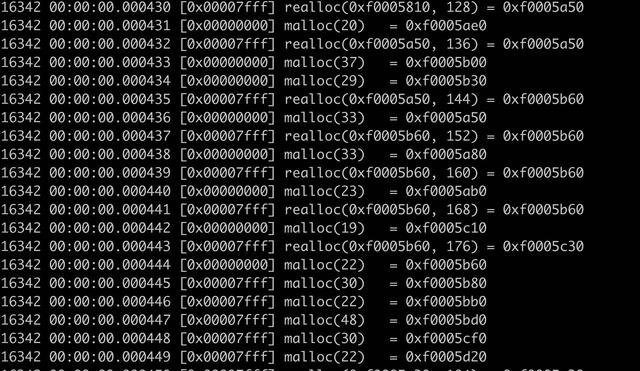
使用 awk 处理上的日志,统计线程处理的次数。
cat malloc.log | awk '{print $1}' | less| sort | uniq -c | sort -rn | less
284881 16342
135 16341
57 16349
16 16346
10 16345
9 16351
9 16350
6 16343
5 16348
4 16347
1 16352
1 16344
复制代码
可以看到线程 16342 分配释放内存最为凶残,那这个线程在做什么呢?在 jstack 的输出日志中搜索 16342(0x3fd6)线程,可以看到很多次都在处理 jar 包的解压。
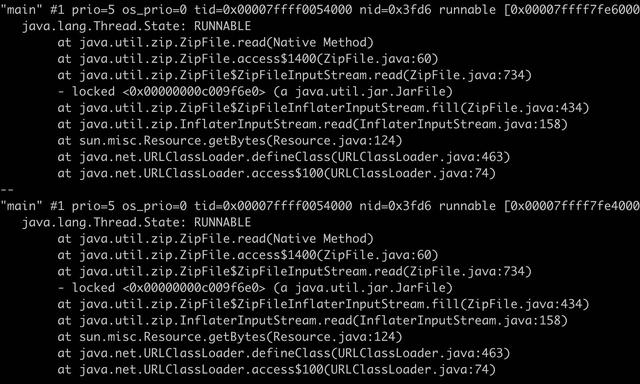
java 处理 zip 使用的是 java.util.zip.Inflater 类,调用它的 end 方法会释放 native 的内存。看到这里我以为是 end 方法没有调用导致的,这种的确是有可能的,java.util.zip.InflaterInputStream 类的 close 方法在一些场景下是不会调用 Inflater.end 方法,如下所示。
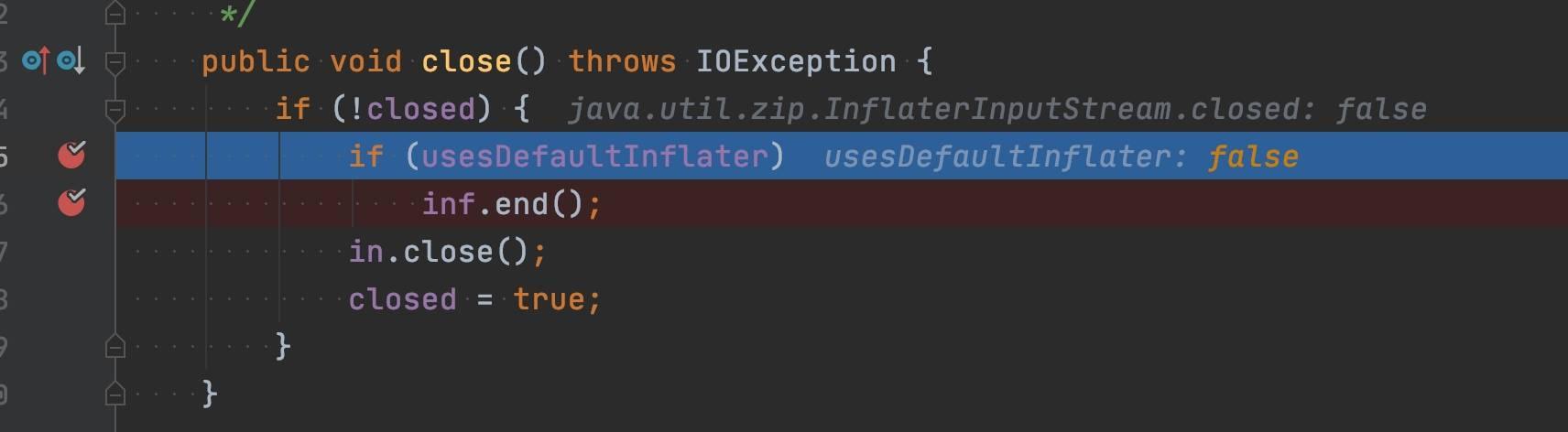
高兴的有点早了。实际上并非如此,就算上层调用没有调用 Inflater.end,Inflater 类的 finalize 方法也调用了 end 方法,我强行 GC 试一下。
jcmd `pidof java` GC.run
复制代码
通过 GC 日志确认确实触发了 FullGC,但内存并没有降下来。通过 valgrind 等工具查看 内存泄露 ,也没有什么发现。
如果说 JVM 本身的实现没有内存泄露,那就是 glibc 自己的问题了,调用 free 把内存还给了 glibc,glibc 并没有最终释放,这个内存二道贩子自己把内存截胡了。
glibc 的内存分配原理
这是一个很复杂的话题,如果这一块完全不熟悉,建议你先看看下面这几个资料。
- Understanding glibc malloc sploitfun.wordpress.com/2015/02/10/…
- 淘宝华庭大师的《Glibc 内存管理 – Ptmalloc2 源代码分析》 paper.seebug.org/papers/Arch…
总体来看,需要理解下面这几个概念:
- 内存分配区 Arena
- 内存 chunk
- 空闲 chunk 的回收站(bins)
内存分配区 Arena
内存分配区 Arena 的概念在前面介绍过,也比较简单。为了更直观的了解 heap 的内部结构,可以使用 gdb 的 heap 扩展包,比较常见的有
- libheap: github.com/cloudburst/…
- Pwngdb: github.com/scwuaptx/Pw…
- pwndbg: github.com/pwndbg/pwnd…
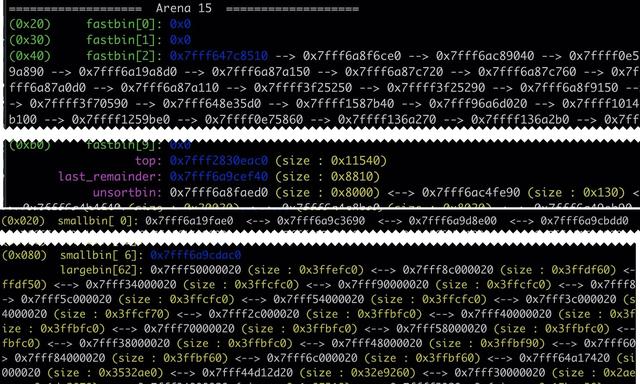
这些也是打 CTF 堆相关的题目可以使用的工具,接下来使用的是 Pwngdb 工具来介绍。输入 arenainfo 可以查看 Arena 的列表,如下所示。
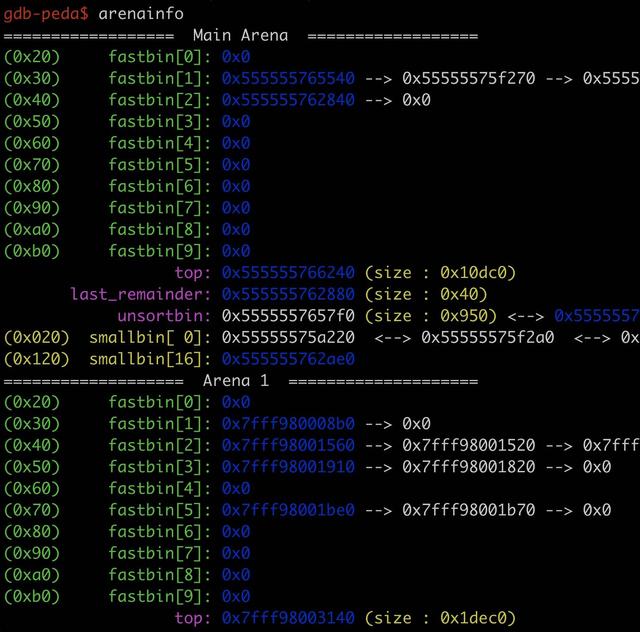
在这个例子中,有 1 个主分配区 Arena 和 15 个非主分配区 Arena。
内存 chunk 的结构
chunk 的概念也比较好理解,chunk 的字面意思是「大块」,是面向用户而言的,用户申请分配的内存用 chunk 表示。
可能这样说还是不好理解,下面一个实际的例子来说明。
# include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void) {
void *p;
p = malloc(1024);
printf("%pn", p);
p = malloc(1024);
printf("%pn", p);
p = malloc(1024);
printf("%pn", p);
getchar ();
return (EXIT_SUCCESS);
}
复制代码
这段代码分配了三次 1k 大小的内存,内存地址是:
./malloc_test
0x602010
0x602420
0x602830
复制代码
pmap 输出的结果如下所示。
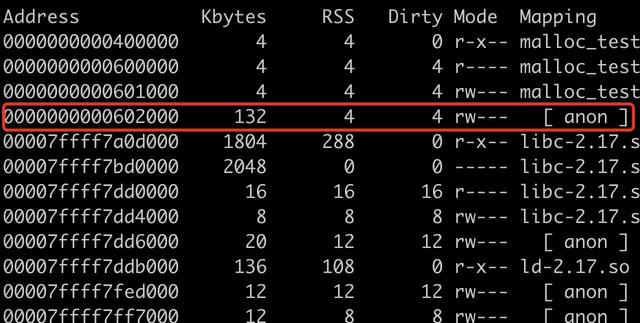
可以看到第一次分配的内存区域地址 0x602010 在这块内存区域的基址(0x602000)偏移量 16(0x10) 的地方。
再来看第二次分配的内存区域地址 0x602420 与 0x602010 的差值是 1,040 = 1024 + 16(0x10)
第三次分配的内存以此类推是一样的,每次都空了 0x10 个字节。这中间空出来的 0x10 是什么呢?
使用 gdb 查看一下就很清楚了,查看这三个内存地址往前 0x10 字节开始的 32 字节区域。
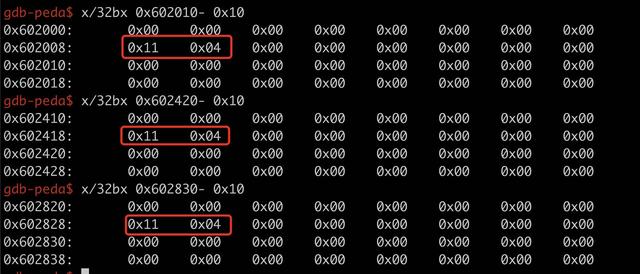
可以看到实际上存储的是 0x0411,
0x0411 = 1024(0x0400) + 0x10(block size) + 0x01
复制代码
其中 1024 很明显,是用户申请的内存区域大小,0x11 是什么?因为内存分配都会对齐,实际上最低 3 位对内存大小没有什么意义,最低 3 位被借用来表示特殊含义。一个使用中的 chunk 结构如下图所示。
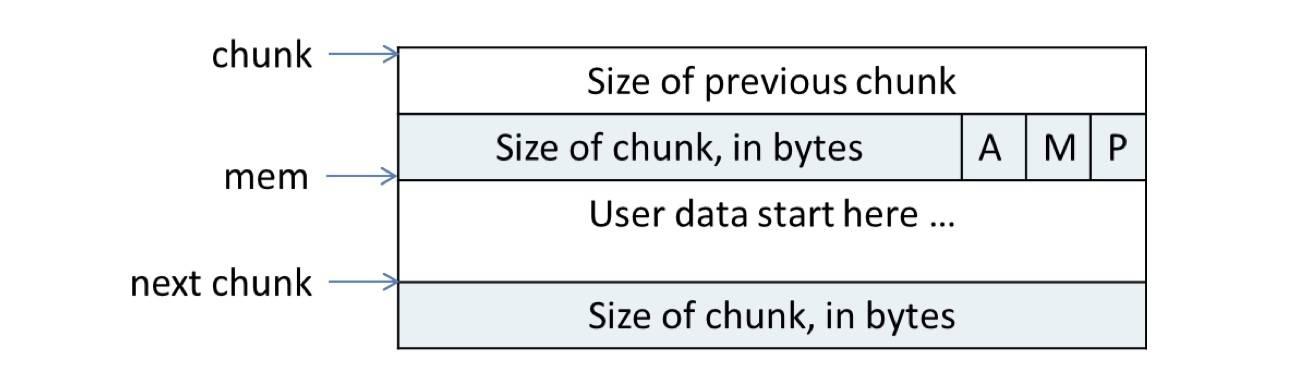
最低三位的含义如下:
- A:表示该 chunk 属于主分配区或者非主分配区,如果属于非主分配区,将该位置为 1,否则置为 0
- M:表示当前 chunk 是从哪个内存区域获得的内存。M 为 1 表示该 chunk 是从 mmap 映射区域分配的,否则是从 heap 区域分配的
- P:表示前一个块是否在使用中,P 为 0 则表示前一个 chunk 为空闲,这时 chunk 的第一个域 prev_size 才有效
这个例子中最低三位是 b001,A = 0 表示这个 chunk 不属于主分配区,M = 0,表示是从 heap 区域分配的,P = 1 表示前一个 chunk 在使用中。
从 glibc 源码中可以看的更清楚一些。
#define PREV_INUSE 0x1
/* extract inuse bit of previous chunk */
#define prev_inuse(p) ((p)->size & PREV_INUSE)
#define IS_MMAPPED 0x2
/* check for mmap()'ed chunk */
#define chunk_is_mmapped(p) ((p)->size & IS_MMAPPED)
#define NON_MAIN_ARENA 0x4
/* check for chunk from non-main arena */
#define chunk_non_main_arena(p) ((p)->size & NON_MAIN_ARENA)
#define SIZE_BITS (PREV_INUSE|IS_MMAPPED|NON_MAIN_ARENA)
/* Get size, ignoring use bits */
#define chunksize(p) ((p)->size & ~(SIZE_BITS))
复制代码
前面介绍的是 allocatd chunk 的结构,被 free 以后的空闲 chunk 的结构不太一样,还有一个称为 top chunk 的结构,这里不再展开。
chunk 的回收站 bins
bin 的字面意思是「垃圾箱」。内存在应用调用 free 释放以后 chunk 不一定会立刻归还给系统,而是就被 glibc 这个二道贩子截胡。这也是为了效率的考量,当用户下次请求分配内存时,ptmalloc2 会先尝试从空闲 chunk 内存池中找到一个合适的内存区域返回给应用,这样就避免了频繁的 brk、mmap 系统调用。
为了更高效的管理内存分配和回收,ptmalloc2 中使用了一个数组,维护了 128 个 bins。
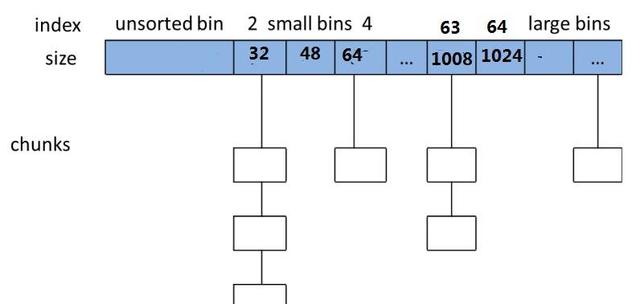
这些 bin 的介绍如下。
- bin0 目前没有使用
- bin1 是 unsorted bin,主要用于存放刚刚释放的 chunk 堆块以及大堆块分配后剩余的堆块,大小没有限制
- bin2~bin63 是 small bins,用于维护 < 1024B 的 chunk 内存块,同一条 small bin 链中的 chunk 具有相同的大小,都为 index * 16,比如 bin2 对应的链表的 chunk 大小都是 32(0x20),bin3 对应的链表的 chunk 大小为 48(0x30)。备注:淘宝的 pdf 图中有点问题,pdf 中的 size * 8,看源码,应该是 *16 才对
- bin64~bin126 是 large bins,用于维护 > 1024B 的堆块,同一条链表中的堆块大小不一定相同,具体的规则不是本篇介绍的重点,不再展开。
具体到本例中,在 Pwngdb 中可以查看每个 arena 的 bins 信息。如下图所示。
fastbin
一般情况下,程序在运行过程中会频繁和分配一些小的内存,如果这些小内存被频繁的合并和切割,效率会比较低下,因此 ptmalloc 在除了上面的 bin 组成部分,还有一个非常重要的结构 fastbin,专门用来管理小的内存堆块。
64 位系统中,不大于 128 字节的内存堆块被释放以后,首先会被放到 fastbin 中,fastbin 中的 chunk 的 P 标记始终为 1,fastbin 的堆块会被当做使用中,因此不会被合并。
在分配小于 128 字节的内存时,ptmalloc 会首先在 fastbin 中查找对应的空闲块,如果没有才去其它 bins 中查找。
换个角度来看,fastbin 可以看做是 smallbin 的一道缓存。
内存碎片与回收
接下来我们来做一个实验,看看内存碎片如何影响 glibc 的内存回收,代码如下所示。
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define K (1024)
#define MAXNUM 500000
int main() {
char *ptrs[MAXNUM];
int i;
// malloc large block memory
for (i = 0; i < MAXNUM; ++i) {
ptrs[i] = (char *)malloc(1 * K);
memset(ptrs[i], 0, 1 * K);
}
//never free,only 1B memory leak, what it will impact to the system?
char *tmp1 = (char *)malloc(1);
memset(tmp1, 0, 1);
printf("%sn", "malloc done");
getchar();
printf("%sn", "start free memory");
for(i = 0; i < MAXNUM; ++i) {
free(ptrs[i]);
}
printf("%sn", "free done");
getchar();
return 0;
}
复制代码
程序中先 malloc 了一块 500M 的内存,然后再 malloc 了 1B 的内存(实际上比 1B 要大一点,不过不影响说明),接下来 free 掉那 500M 的内存。
在 free 之前的内存占用如下所示。

在调用 free 以后,使用 top 查看 RES 的结果如下。
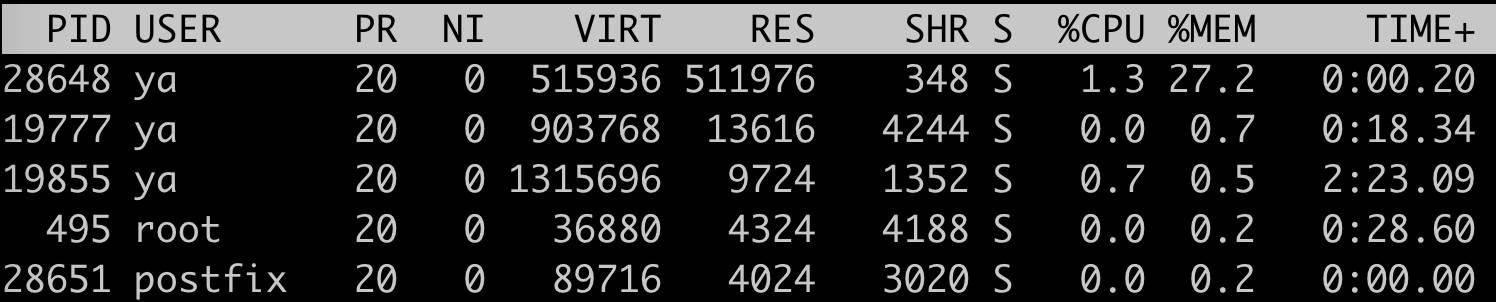
可以看到实际上 glibc 并没有把内存归还给系统。而是放到了它自己的 unsorted bin 中,使用 gdb 的 arenainfo 工具可以看得很清楚。
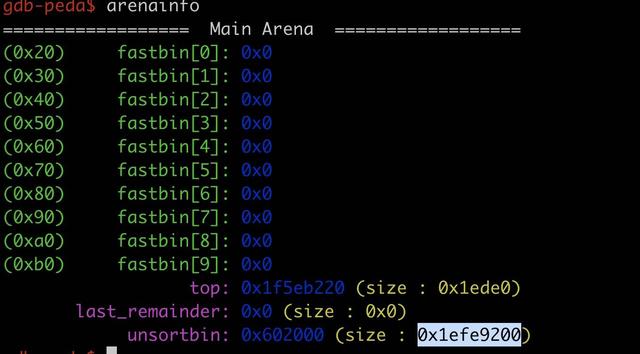
0x1efe9200 用十进制表示是 520,000,000,正是我们刚刚释放的 500M 左右的内存。
如果我把代码中的第二次 malloc 注释掉,glibc 是可以立刻释放内存的。

这个实验已经比较能证明内存碎片对 glibc 内存消耗的影响了。
glibc 与 malloc_trim
glibc 中提供了 malloc_trim 函数,文档内容在这里:
man7.org/linux/man-p…
从文档来看,应该只是归还堆顶上全部的空余内存给系统,没有办法归还堆顶内存中的空洞。但是实际上并非如此,在本例中,调用 malloc_trim 真正归还了 500M 以上的内存给系统。
gdb --batch --pid `pidof java` --ex 'call malloc_trim()'
复制代码
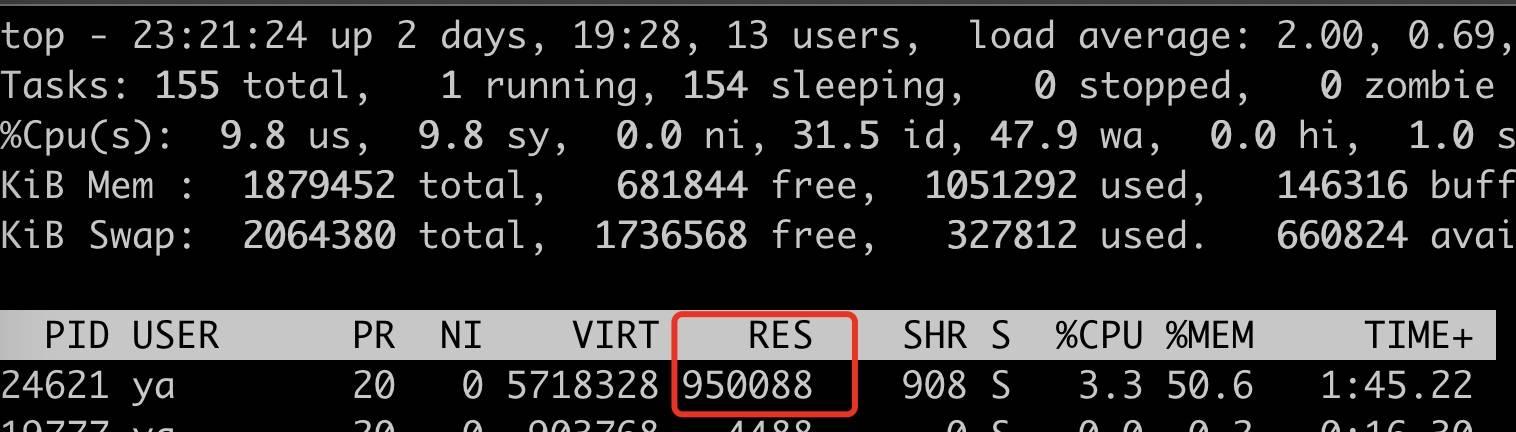
看 glibc 的源码,malloc_trim 的底层实现已经做了修改,是遍历所有的 arena,然后对每个 arena 遍历所有的 bin,执行 madvise 系统调用告知 MADV_DONTNEED,通知内核这块可以回收了。
通过 Systemtap 脚本可以同步确认这一点。
probe begin {
log("begin to proben")
}
probe kernel.function("SYSC_madvise") {
if (ppid() == target()) {
printf("nin %s: %sn", probefunc(), $$vars)
print_backtrace();
}
}
复制代码
执行 malloc_trim 时,有大量的 madvise 系统调用,如下图所示。
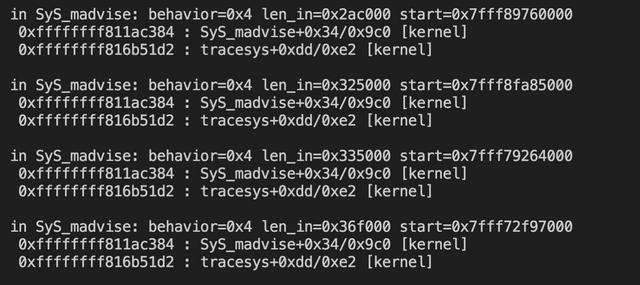
这里的 behavior=0x4 表示是 MADV_DONTNEED,len_in 表示长度,start 表示内存开始地址。
malloc_trim 对前一个小节中的内存碎片实验同样是生效的。
jemalloc 登场
既然是因为 glibc 的内存分配策略导致的碎片化内存回收问题,导致看起来像是内存泄露,那有没有更好一点的对碎片化内存的 malloc 库呢?业界常见的有 google 家的 tcmalloc 和 facebook 家的 jemalloc。
这两个我都试过,jemalloc 的效果比较明显,使用 LD_PRELOAD 挂载 jemalloc 库。
LD_PRELOAD=/usr/local/lib/libjemalloc.so
复制代码
重新启动 Java 程序,可以看到内存 RES 消耗降低到了 1G 左右
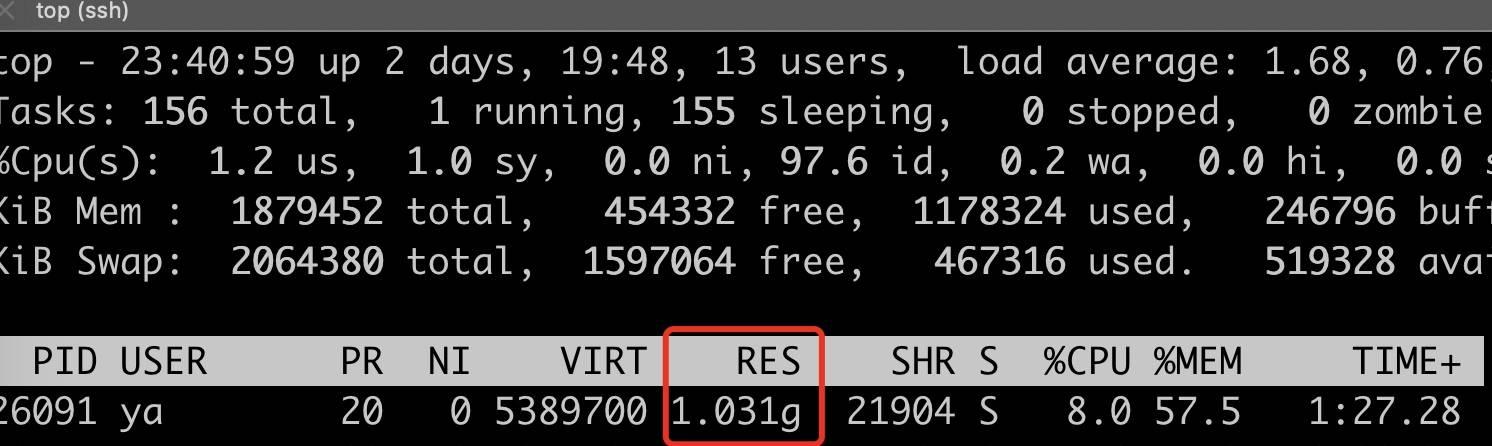
使用 jemalloc 比 glibc 小了 500M 左右,只比 malloc_trim 的 900 多 M 多了一点点。
至于为什么 jemalloc 在这个场景这么厉害,又是一个复杂的话题,这里先不展开,有时间可以详细介绍一下 jemalloc 的实现原理。
经多次实验,malloc_trim 有概率会导致 JVM Crash,使用的时候需要小心。
经过替换 ptmalloc2 为 jemalloc,进程的内存 RES 占用显著下降,至于性能、稳定性还需进一步观察。


