序言
什么是高并发
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
一、高并发带来的后果
导致站点服务器/DB服务器资源被占满崩溃,数据的存储和更新结果和理想的设计是不一样的,比如:出现重复的数据记录,多次添加了用户积分等。
用户角度:
尼玛,这么卡,老子来参加活动的,刷新了还是这样,垃圾网站,再也不来了。
我的经历:
在做公司产品网站的过程中,经常会有这样的需求,比如什么搞个活动专题,抽奖,签到,搞个积分竞拍等等,如果没有考虑到高并发下的数据处理,那就Game Over了,很容易导致抽奖被多抽走,签到会发现一个用户有多条记录,签到一次获得了获得了多积分,等等,各种超出正常逻辑的现象,这就是做产品网站必须考虑的问题,因为这些都是面向大量用户的,而不是像做ERP管理系统,OA系统那样,只是面向员工。
二、并发下的处理
-
配置 数据库连接池 C3P0
配置连接池的原因是因为我们要做一个高并发的秒杀系统,可能一些连接会被锁住,其他的 线程 就可能会拿不到连接的情况,所以我们要调整一下连接池的属性来更符合我们的场景
<!-- 数据库连接池 -->
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<!-- 配置连接池属性 -->
<property name="driverClass" value="${driver}"/>
<property name="jdbcUrl" value="${url}"/>
<property name="user" value="${username}"/>
<property name="password" value="${password}"/>
<!-- c3p0连接池的私有属性 -->
<property name="maxPoolSize" value="30"/>
<property name="minPoolSize" value="10"/>
<property name="auto commit OnClose" value="false"/>
<!-- 获取连接超时时间 -->
<property name="checkoutTimeOut" value="1000"/>
<!-- 当获取连接失败重试次数 -->
<property name="acquireRetryAttempsts" value="2"/>
</bean>
-
事务+锁来防止并发导致数据错乱
建议所有的数据操作都写在一个 sql 事务里面。下面举三个例子来说明情况。
①签到功能:一天一个用户只能签到一次,签到成功后用户获得一个积分,我们可以把添加签到和添加积分放到一个事务里面,这样在添加失败,或者编辑用户积分失败的时候可以回滚数据。
②在高并发情况下用户进行抽奖,很可能会导致用户参与抽奖的时候积分被扣除,而奖品实际上已经被抽完了。我们可以在事务里面,通过WITH(UPDLOCK)锁住商品表,或者update表的奖品剩余数量和最后编辑时间字段,来把数据行锁住,然后进行用户积分的消耗,都完成后提交事务,失败就回滚,这样就放置数据错乱。
//当我们用UPDLOCK来读取记录时可以对取到的记录加上更新锁 //从而加上锁的记录在其它的线程中是不能更改的只能等本线程的事务结束后才能更改 update commodity with (updlock) set count = count-1 where id=?;
③ 如果要实现这样一个需求:cache里面的数据必须每天9点更新一次,其他时间点 缓存 每小时更新一次。并且到9点的时候,凡是已经打开页面的用户会自动刷新页面。
这里面包含的用户触发缓存更新的逻辑:用户刷新页面,当缓存存在的时候,会获取到最后一次缓存更新的时间。如果当前时间>9点,并且最后缓存时间在9点之前,则会从数据库中重新获取数据保存到cache中。如果大量用户在9点之前已经打开了页面,而且在9点之后还未关闭页面,那么就会导致在9点的时候会有很多并发请求过来,数据库服务器压力暴增。
要解决这个问题,最好就是只有一个请求去数据库获取,其他都是从缓存中获取数据。此时,我们就可以用锁来解决:从数据读取到缓存那段代码前面加上锁,这样在并发的情况下只会有一个请求是从数据库里获取数据,其他都是从缓存中获取。
但是不是所有的方法都需要加事务,比如读操作。
-
事务时间要尽可能短
当在高并发系统进行写入操作的时候就会锁定你写入的那行代码,要是写入时间很长那么锁定的时间也很长,不利于高并发的操作。特别是网络操作运行时间一般都比较长,所以最好不要穿插进来。
-
利用缓存处理高并发
-
把被用户大量访问的静态资源缓存在 CDN 中
在秒杀的时候,如果秒杀没有开始,用户看到喜欢的商品,用户就会不停刷新这个页面。所以类似于秒杀详情页这些被用户大量访问的页面静态资源(如html、css、js)就应该部署到CDN节点上,也就是用户访问的那些html已经不在系统中了,而是在CDN节点上。
用户大量刷新→CDN(detail页静态化,静态资源js、css等)→高并发系统
-
合理使用 nosql 缓存数据库
高并发接口,比如秒杀地址接口是没办法使用CDN缓存的,因为CDN适合我这个请求对应的资源不变的,比如JavaScript,JavaScript拿回来在浏览器执行,它的内容是不变的。但是高并发接口的返回数据是在变化的,比如秒杀接口:一开始没有秒杀,随着时间推移已经开启秒杀,再往后秒杀已经关闭了。所以高并发接口不适合放在CDN缓存,但是适合放在服务器端缓存。
后端缓存可以用应用系统来控制,比如先访问数据库拿到高并发接口的数据,然后放在 redis 缓存里面,下次访问直接在缓存里面找。
使用这种方法的好处就是 一致性维护成本低 :请求地址要求拿到高并发接口的数据的时候,先访问服务器端缓存,若没有再访问数据库。如果高并发接口的数据需要改变的时候,我们可以等待缓存超时再更新数据,或者直接穿透到数据库更新,又或者当数据库数据更新的时候主动更新一下缓存。
-
使用一级缓存,减少nosql服务器压力
一级缓存使用站点服务器缓存去存储数据,注意只存储部分请求量大的数据,并且缓存的数据量要控制,不能过分的使用站点服务器的内存而影响了站点应用程序的正常运行。
-
善用原子计数器
在秒杀系统中,热点商品会有大量用户参与进来,然后就产生了大量减库存竞争。所以当执行秒杀的时候系统会做一个原子计数器(可以通过redis/nosql实现),它记录的是商品的库存。当用户执行秒杀的时候,就会去减库存,也就是减原子计数器,保证原子性。当减库存成功之后就回去记录行为消息(谁去减了库存),减了会后作为一个消息当到一个分布的MQ(消息队列)中,然后后端的服务器会把其落地到MySQL中。
-
善用redis的消息队列
使用redis的list,当用户参与到高并发活动时,将参与用户的信息添加到消息队列中,然后再写个多线程程序去消耗队列(pop数据),这样能避免服务器宕机的危险。
通过消息队列可以做很多的服务,比如定时短信发送服务,使用sorted set(sset),发送时间戳作为排序依据,短信数据队列根据时间升序,然后写个程序定时循环去读取sset队列中的第一条,当前时间是否超过发送时间,如果超过就进行短信发送。
-
事务竞争的优化
在高并发秒杀系统中,第一个用户执行减库存操作,在commit/rollback以前,第二个秒杀用户也要执行减库存,但是因为一个用户得到了锁,其他用户就必须进行等待(因为当事务不去提交/回滚的话行级锁是没办法释放的)。也就是说后面的线程想减库存,必须等到前面的线程释放哈行锁。这就变成了一个串行的操作:同一个商品减库存,大家都要排队等,就产生了大量阻塞操作。而且,sql语句发送给数据库也可能存在网络延迟,这样后面的用户等待时间就更长了。
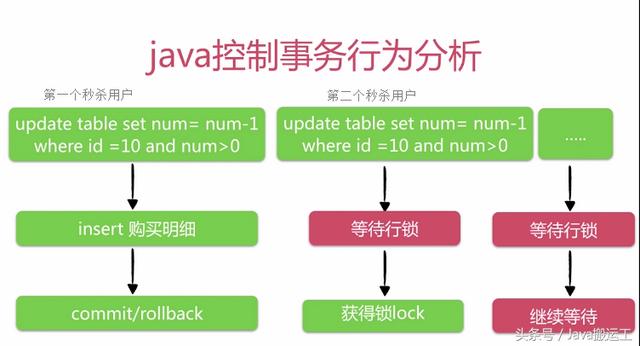
解决方案
①MySQL源码层的修改方案:在update后面加上这样一句话:/+[auto_commit]/,当你执行完这条update的时候它会自动回滚。回滚的条件是:update影响的记录数是1就可以commit,如果为0就会rollback。也就是不给java客户端和MySQL之间网络延迟,然后再由java客户端其控制commit和rollback,而是直接通过语句发过去你就告诉我commit和rollback。这个成本比较高,需要修改MySQL源码
②使用存储过程:存储过程的本质就是让一组sql组成一组事务,然后再MySQL端完成,避免客户端完成事务造成性能的干扰。一般情况下,spring声明事务和手动控制事务都是客户端控制事务。这些事务在行级锁没有那么高的竞争情况下是完全OK的,但是秒杀是一个特殊的应用场景,它会在同一行中产生热点,大家都竞争同一行,这个时候存储过程就能够发挥作用了,他把整个sql执行过程放在MySQL端完成,MySQL执行sql的效率非常高。*简单的逻辑我们可以使用存储过程,太过复杂的就不要依赖了。
-- 秒杀执行存储过程 DELIMITER $$ -- onsole ; 转换为 $$ -- 定义存储过程 -- 参数:in 输入参数; out 输出参数 -- row_count():返回上一条修改类型sql(delete,insert,upodate)的影响行数 -- row_count: 0:未修改数据; >0:表示修改的行数; <0:sql错误/未执行修改sql CREATE PROCEDURE `seckill`.`execute_seckill` (IN v_seckill_id bigint, IN v_phone BIGINT, IN v_kill_time TIMESTAMP, OUT r_result INT) BEGIN DECLARE insert_count INT DEFAULT 0; START TRANSACTION; INSERT ignore INTO success_killed (seckill_id, user_phone, create_time) VALUES(v_seckill_id, v_phone, v_kill_time); SELECT ROW_COUNT() INTO insert_count; IF (insert_count = 0) THEN ROLLBACK; SET r_result = -1; ELSEIF (insert_count < 0) THEN ROLLBACK ; SET r_result = -2; ELSE UPDATE seckill SET number = number - 1 WHERE seckill_id = v_seckill_id AND end_time > v_kill_time AND start_time < v_kill_time AND number > 0; SELECT ROW_COUNT() INTO insert_count; IF (insert_count = 0) THEN ROLLBACK; SET r_result = 0; ELSEIF (insert_count < 0) THEN ROLLBACK; SET r_result = -2; ELSE COMMIT; SET r_result = 1; END IF; END IF; END; $$ -- 代表存储过程定义结束 DELIMITER ; SET @r_result = -3; -- 执行存储过程 call execute_seckill(1001, 13631231234, now(), @r_result); -- 获取结果 SELECT @r_result;
③通常我们的操作是: 减库存(rowLock)→插入购买明细→commit/rollback(freeLock) 。我们可以在这个基础上进行一些简单的优化,调换操作的顺序: 插入购买明细→减库存(rowLock)→commit/rollback(freeLock) ,我这样们的延迟就只会发生在update语句这个点上。
-
脚本合理控制请求
比如用脚本防止用户重复点击导致多余的请求。
-
使用具有高并发能力的编程语言去开发
nodejs就是一个具有高并发能力的编程语言,它使用单线程异步时间机制,不会因为数据逻辑处理问题导致服务器资源被占用而导致服务器宕机,我们可以使用NodeJs写web接口。
apache模式,以下简称A模式。一共有三个点餐窗口,三位服务人员,三位厨师(请自行脑补画面,但是别乱想)。顾客在任一窗口点餐[所谓多线程],点完后服务员传达厨师,等待厨师出餐,服务员返给顾客[同步返回响应结果]。顾客本次购物结束。服务员进行下一位顾客的点餐[接收下一个请求]。
nodejs模式,以下简称N模式。一共只有一个点餐窗口一位服务员[单线程],一位厨师[CPU]。顾客在窗口点餐,点完后服务员传达厨师,厨师进行出餐,而服务员不必等待[不必等待当前请求返回结果],直接进行下一位顾客的点餐,然后继续传达下一个顾客的订单给厨师。厨师挨个完成后抛出给出餐窗口[异步返回响应结果],顾客到出餐窗口取餐,本次购物结束。
比如要统计用户通过各种方式(如点击图片/链接)进入到商品详情的行为次数,如果同时有1w个用户同时在线访问页面,一次拉动滚动条屏幕页面展示10件商品,这样就会有10w个请求过来,服务端需要把请求的次数数据入库,这样服务器分分钟给跪了。
要解决这些访问量大的数据统计接口的问题,我们可以通过nodejs写一个数据处理接口,把统计数据先存到redis的list中,然后再使用nodejs写一个脚本,脚本的功能就是从redis里取出数据保存到mysql数据库中。这个脚本会一直运行,当redis没有数据需求要同步到数据库中的时候,sleep,然后再进行数据同步操作。
总结
以上是对 浅析高并发秒杀系统 总结,分享给大家,希望大家可以了解什么是浅析高并发秒杀系统。觉得收获的话可以点个关注收藏转发一波喔,谢谢大佬们支持。(吹一波,233~~)



