浅析 正则表达式 的原理和运用
一、Java程序员和前端人员的盲区
谈到正则表达式,很多资深的程序员都会感到棘手。目前网络上有很多正则表达式的基础教程,可是往往都只是皮毛。在实际运用过程中,都会遇到很多问题。比如一个邮箱和网址的校验,可能大多数人想到的还是去 百度 借助搜索引擎找到答案。遇到稍微复杂一点的问题,可能更加倾向于非正则校验,笔者之前做过一个正对某个网站的信息采集程序,笔者当时面对一堆前端网页,想爬取信息,首先考虑的不是用正则,通过字符串截取以及判断位置来处理的,后面回顾一下,其实正则表达式才是最佳的方案。
二、正则表达式的理解
正则表达式就是一门工具,用好了事半功倍。正则表达式是用来进行字符串模式匹配,来实现替换和搜索的功能。正则表达式是来描述规则的表达式,它的底层就是用来进行模式匹配。
几种特殊字符的正则表达式:
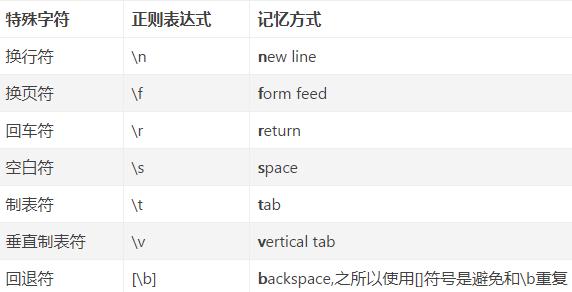
为了解决多个字符的筛选匹配问题,引入了集合区间和通配符。在正则表达式里,集合的使用方式是使用中括号[和]。/[345]/这个正则能同时匹配3,4,5三个字符,但是如果我们希望能匹配所有的字符又该如何处理呢?为了解决这个问题,引入了元字符-来表示区间范围,利用/[0-9]/能匹配所有的数字,/[a-z]/可以匹配所有的英文字符小写。
纵然有了集合和区间的使用方式,可是如果要同时匹配多个字符还是要逐一列举,这是极其低效的。所以在正则表达式里衍生了一批用来同时匹配多个字符的简便正则表达式:
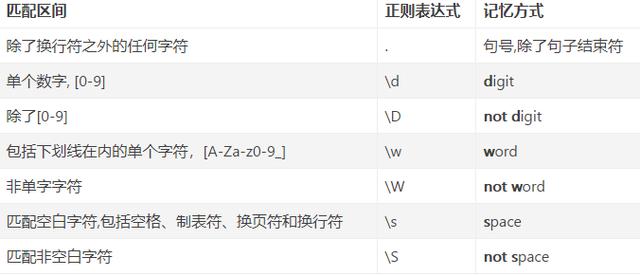
一对一和一对多的字符匹配都说完了。接下来,来介绍如何同时匹配多个字符。要实现多个字符的匹配我们只要多次循环,重复使用我们的之前的正则规则就可以了。根据循环次数的多少,我们可以分为0次,1次,多次,特定次。
我们使用元字符?来匹配一个或零个字符。如果你需要匹配water和watesr两个单词,就需要同时保证s这个字符能否都能匹配到,因此正则表达式应该是/wates?r/。
我们使用元字符*表示匹配0个获无数个字符,同城那个用来过滤掉某些可有可无的字符串。
我们使用元字符+来表示匹配同个字符出现一次或多次的情况。
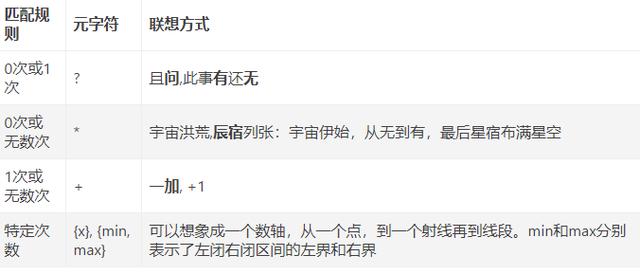
我们用元字符{和}用来给重复匹配设置精确的区间范围。比如‘b’我想匹配3次,那么我就使用/b{3}/这个正则,又比如’b’我想至少匹配2次就是/b{2,}/这个正则。完整的语法:
– {x}: x次
– {min, max}: 介于min次到max次之间
– {min, }: 至少min次
– {0, max}: 至多max次
套用记忆口诀:
2.1单词边界
单词是句子和文章的基本单位,如果要把文章或句子中的特定单词找出来,比如:The cat scattered his food all over the room.
我想找到cat这个单词,可是如果只是用/cat/这个正则,就会同时匹配到cat和scattered两个单词。此时我们就需要使用边界正则表达式b,在正则引擎其实匹配的是能构成单词的字符(w)和不能构成单词的字符(W)中间的那个位置。
我们改写成/bcatb/这样就能匹配到cat这个单词。
2.2字符串边界
匹配完单词,我们来看一下整个字符串的边界如何匹配。元字符^用来匹配字符串的开头,$用来匹配字符串的末尾。并且是在长文本里,如何排除换行符的干扰,我们要使用多行模式,来匹配I am liyue123这个句子:
I am liyue123.
I am liyue123.
I am liyue123.
我们可以使用/^I am liyue123.$/m这样的正则表达式即可完成。正则里面的模式除了m外比较常用的还有i和g。i表示忽略大小写,g表示找到所有符合的匹配。
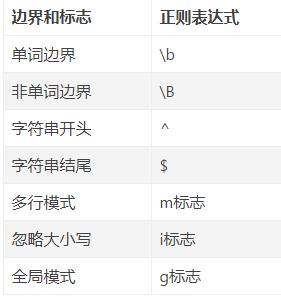
总结一下:
2.3逻辑处理
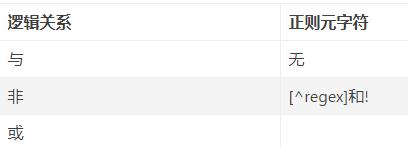
在正则表达式里面,默认的正则规则都是与的关系,而非的关系,分为两种情况:一种是字符匹配,另一种是子表达式匹配。在字符匹配的时候,我们需要使用^这个元字符。在这里需要着重记忆一下:只有在[和]内部使用的^才表示非的关系。子表达式匹配的非关系就要用到前向负查找子表达式以及后向负查找子表达式。
或的关系,通常给子表达式来进行归类说明。例如:我们需要同时匹配a,b两种情况就可以使用(a|b)这样的子表达式。
接下来列举使用场景:
三、分组关系的用法
我们使用(…)把单独的项进行组合,将括号内的项作为一个独立的单元来处理(使用*, +, ?, | , etc),例如:
//?表示匹配前一项0次或1次
//s是指任何Unicode空白字符var reg = /hello(sworld)?/; //如果world是一个可选项,采用这种方式就可以进行选择var str1= "hello";var str2 = "hello world";
reg.test(str1); //truereg.test(str2); //true
另一个作用就是在完整的模式中定义子模式,这样我们可以将每个圆括号中子模式匹配出来的结果提取出来,比如:
var str = "abc123"; //我们匹配的是一个或多个字母后面加一个或多个数字,但是实际上我们只对其中的字母感兴趣
var reg1 = /[a-z]+d+/; //未进行分组
var reg2 = /([a-z]+)d+/;
alert(str.match(reg1)); //abc123;只会输出整个匹配正确的字符
alert(str.match(reg2)); //abc123,abc;子表达式匹配的结果也输出
alert(str.match(reg2)[1]); //abc;通过[]的选取方式将所需内容提取出来,如果用firebug控制台可以看到相应的index
四、选择关系的用法
(…)还允许利用同一表达式的后部引用前面的子表达式,采用n的方式来实现,这里的n指的是带圆括号的子表达式在正则表达式中的位置。因为子表达式是可以嵌套的,因此位置在参与计数的左边括号的位置。 注意:此处的引用并不是对子表达式模式的引用,而是指与那个模式相匹配的文本的引用。 也就是说/([a-z]+)d1/如果对”abc123″进行匹配,实际上可以看做是/([a-z]+)dabc/这样一种形式。 举个简单的例子:
/[‘”][^'”]*[‘”]/; //这个表达式匹配的是位于单引号或双引号内的任意个字符,但是并不要求左侧和右侧的引号相匹配
//如果要左右两边的引号是匹配的,可以这样写:
/([‘”])[^'”]*1/; //如果([‘”])匹配到的是’,那么1就是’,这样能保证两边都是一样的符号
上面为什么说要参与计数的左括号呢?正是因为还有不参与的东西在,也就是(?:),他只用来进行组合。至于匹配什么字符他不记忆,也谈不上分组。比如/(?:hello)s(world)/,这里1引用的就是与(world)相匹配的字符。
五、断言说明
(?!)是零宽负向先行断言,要求接下来的字符不与p模式匹配。 先来讲一下(?=p)模式是怎么工作的,
/Windows (?=95|98|NT|2000)/ 能匹配 ” Windows2000 ” 中的 “Windows”,但不能匹配”Windows3.1” 中的 “Windows”。
也就是说,必须要求Windows后面必须是95|98|NT|2000中的一个,而在匹配正确之后,他的返回值并不包括95|98|NT|2000的部分:var reg = /Windows(?=95|98|NT|2000)/;
var str1 = “Windows2000”;
var str2 = “Windows3.1”;
alert(str1.match(reg)); //Windows
reg.test(str1); //true
reg.test(str2); // false 这个还是很好理解的,但是我想试一下的时候就遇到问题了。
//这里我想匹配类似#userName的结构,也就是/#w+/这样的形式;
//但是呢,我只想提取出userName这一部分,当然这用分组就可以实现了,不过这里还是用这个举下例子
//首先我是这样写的
var reg = /(?=#)w+/;console.log(reg.test(“#cccc”)); //false
为啥会是false呢,这就是零宽的概念了,就是只匹配位置,在匹配过程中,不占用字符,所以被称为“零宽”,这种方式也叫非获取性匹配,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索, 而不是从包含预查的字符之后开始。 在上面的例子中,截止到(?=#)匹配到的是“右边是#的位置”,也就是#的左边,接下来并不是从u开始匹配,而是从#开始,
#当然不是w了所以结果是false,换成/(?=#)#w+/结果就是true了。
关于(?!)
再举个例子: 解释:/(?!#)w+/g,
截止到(?!#)匹配的是“右边不是#”的位置,也就是#的右边,从这里开始匹配后边的表达式。第二个表达式也是按同样的方式理解。
六、总结
以上就是对正则表达式使用过程中的一些举例。


