不要再把Java内存区域和Java内存模型混淆,再问就自闭啦。

上次我们讲了 JVM 的类加载机制,主要涉及了双亲委派机制,如何破坏双亲委派机制,不明白的小伙伴可以移步上篇不要再死记硬背Java的类加载啦。
网上有很多关于 Java 区域和内存模型的文章,但是很多人读完之后还是搞不清楚,主要是因为大家把这两个混为一谈,也不关心 JDK 版本。所以概念一多,非常容易混淆。
所以下面将重点说明Java内存区域,主要涉及运行时的几大区域划分,每个区域的职责。而 Java内存模型 的文章可以参考我之前写的[并发基础篇]MESI协议,JMM, 线程 常见方法等。
一、简介
我们都知道作为计算机界的老大哥C语言,其是面向内存进行开发的。对于每个对象,我们都需要手动的创建,开辟内存,销毁,如果不销毁,他可能永远删除不了啦。
但是Java并不是这样的,其有一整套虚拟机自动内存管理机制,我们不需要手动的创建对象,开辟内存,乃至销毁,不易发生内存溢出和泄露。这样看上去是不是爽歪歪。
但是这也是头疼的,对于其内部,我们是完全懵逼的状态。一旦出现问题,完全不知道咋整。
所以我们接下来,就要学习Java内存到底是如何工作的,各部分如何划分。

二、整体框架
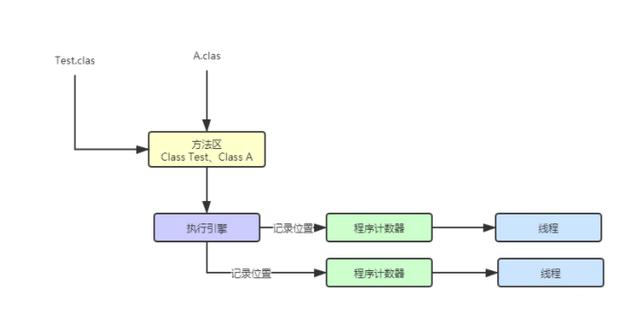
首先我们JVM会加载类到内存中,所以 JVM 中必然会有一块内存区域来存放我们写的那些类。Java中有类对象、普通对象、本地变量、方法信息等等各种对象信息,所以JVM会对内存区域进行划分:

三、方法区
方法区域堆一样,也是线程共享的内存区域,主要用来存放类的信息。
方法区只存在于JDK1.8以前的版本,主要是存储从”.class“文件里加载进来的类,包括类的名称、方法信息、字段信息、静态变量、常量以及编译器编译后的代码等。其也被称为“永久代”,但是这两者并不等价,只是垃圾收集器的分代收集理论扩展到了方法区,使得垃圾收集器能够像管理Java堆一样管理内存,省去了专门为方法区编写代码的工作。
注意:这只是对于HotSpot的虚拟机有用,对于其他的 虚拟机 ,如IBM J9,是不存在永久代的概念的。
而且其有大小限制,我们可以设置-XX:MaxPermSize的大小来控制方法区的上限。但是其有利有弊。有利的是我们更容易把控程序启动后所占据的内存,有弊的是一旦超出了限制,就会出现java.lang.OutOfMemoryError: PermGen报错。(此处可考面试题,线上调优经验,注意注意。)
从JDK1.8开始,这块区域的名字改成了元数据区(Metaspace),元数据区直接使用本地内存。比1.8之前的版本对比,其直接向内存申请,不会再出现之前内存不够的情况啦。如果不够,那就要加服务器配置的事情啦。但也不能无限扩展,因此可以使用 -XX:MaxMetaspaceSize来控制最大内存。
举个例子:
public class Test
{
public static void main(String[] args)
{
}
}
复制代码
我们新建了一个Test类,里面有个空的main方法,当通过类加载,其类相关的信息就会被加载到方法区中,如下图。

四、程序计数器
其实很小的一块内存空间,可以看作是当前线程所执行的 字节码 的行号。因为 Java虚拟机 的多线程是通过线程轮流切换,轮流得到处理器的资源来进行的,所以就需要在线程中有一个 计数器 来记录执行到哪一行,方便切换回来,所以每个线程都需要一个独立的 程序计数器 ,他们相互独立,互不影响。
白话解释:
这个大冬天的,正躺着愉快刷剧,突然饿了,要去泡个泡面吃吃,这时候是不是要暂停,先泡个面?等泡面好了,再回来继续看。那么这边的暂停就相等于程序计数器。

在上面例子的基础,我们多加两行代码:
public class Test
{
public static void main(String[] args)
{
A a=new A();
a.load();
}
}
复制代码
当JVM加载类信息到内存之后,实际就会使用自己的字节码执行引擎,去执行这些字节码指令, 程序计数器是线程私有的,也就是说每个线程都有个自己的程序计数器,记录当前线程执行到了哪一条字节码指令。
五、Java虚拟机栈
Java虚拟机栈,其实是一种描述Java方法执行的数据结构。每个方法被执行的时候,都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动作链接、方法出口等信息。
每个方法从被调用到执行完成的过程,其实就是一个栈帧在虚拟机栈中从入栈到出栈的过程。
比如main线程执行了main()方法,那么就会创建一个栈帧(里面存放a局部变量),并将其压入main线程自己的Java虚拟机栈中,如下图:

然后main线程继续执行load方法,再执行A类中的方法,其如果有局部变量,就会再创建一个栈帧,压入自己的虚拟机栈中,如下图。

六、本地方法栈
本地方法栈,其作用和Java虚拟机栈类似,区别在于本地方法栈是为虚拟机所使用到的Native方法服务,而Java虚拟机栈为虚拟机执行Java方法(也就是字节码)服务。本地方法栈也是线程私有的。
JDK中的很多底层API,比如IO、NIO、网络等,如果大家去看它的源码,会发现很多地方是调用的native修饰的方法,如CAS,这块先暂且搁下,后面并发说。
比如下面这样:
public native int hashCode();
复制代码
在调用native方法时,也会有线程对应的栈来保存native方法底层用到的局部变量表之类的信息,这就是本地方法栈的作用。
七、Java堆
是数据管理中最大的一块。所有线程共享的一块内存内容,在虚拟机启动时就已经自动创建的。这一块主要存放对象,也就是平时经常说的垃圾回收区域。
Java堆内存,这是JVM内存区域中最重要的一块区域,存放着各种Java对象,是线程共享区域。
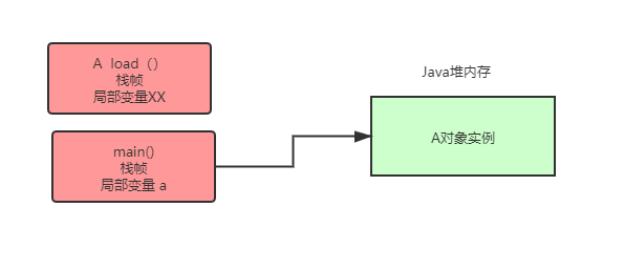
下面代码中,new A()创建了一个对象实例,这个对象实例的相关信息就存放在Java堆内存中:
public class Test{
public static void main(String[] args) {
A a = new A();
a.load();
}
}
复制代码
main线程在执行main()方法时,会为其创建一个栈帧并入栈,栈帧中的局部变量a存放着A对象实例在Java堆内存中的地址:
八、总结
该篇主要讲了JVM的运行时内存区域,主要包括他们各自的划分,每个部分具体存储的是什么,中间结合代码详细说明了过程,希望能给大家一点帮助,不要再以为里面是个黑匣子,一脸懵逼的状态。(主要为了面试不懵逼,哈哈哈)
如果觉得写得还行,麻烦给个赞,您的认可才是我写作的动力!
如果觉得有说的不对的地方,欢迎评论指出。
也可以关注我的公众号《程序员黑哥》,我们一起讨论下。 好了,拜拜咯。


