“不会 正则表达式 ,就算写遍代码也嘛不是”。说到正则表达式,可能动态语言的码农Perl,Python,JS甚至是Golang的开发人员可能都熟悉。对 Java 码农来说,可能CURD手到擒来,Spring Stuts Hibernat耳闻能详,但是说到Regex RE模式,可能熟练的少。
那么,今天虫虫就来给广大Java码农来补补正则的课。

正则基础
正则表达式(Regex,简称RE)是一种根据字符串集中的每个字符串的共同特征来描述字符串集的方法。可用于搜索,编辑或处理文本和数据。简单来说,正则表达式是帮助我们根据特定格式验证或匹配字符串的方式。可以类比数据库的SQL语言,sql是搜索数据,RE是搜索字符串。正则表达式和SQL语言是开发界的两个伟大发明。
正则表达式可以用于:
验证用户的输入。
搜索给定数据中的文本。(可在文本编辑器中使用)
编译器中的解析器
语法突显,数据包嗅探器等。
要全面了解Regex,我们要理解基本知识,下面我们分别介绍,示例中我们用到在线正则解析网站regex101。
基本量词(*+?和{n})
正则表示式子中(各语言通用)中的数量词由*,+.? 和{n}组成。
* 表示匹配零个或多个其先前模式的实例。例如,abc*表示文本必须与’ab’相匹配,后跟零个或多个’c’,即文本可能没有附加’c’并且文本也可能有一个或多个’c’。
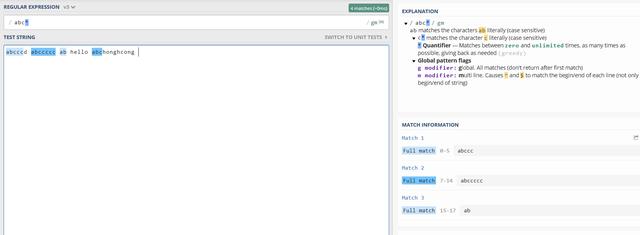
+ 匹配其先前模式的一个或多个实例,例如abc+表示文本必须带有”ab”,后跟一个或多个”c”。所以abc是您可以拥有的至少是正确的,而abcc也是正确的。
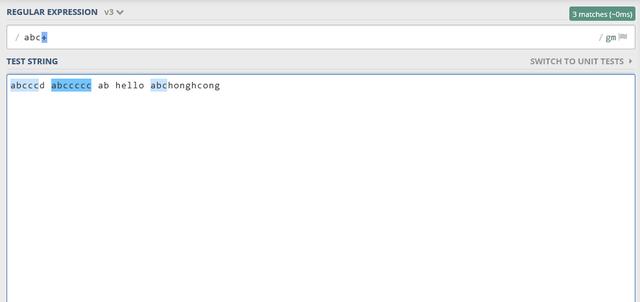
?匹配零个或一个出现的模式,例如abc?表示文本可以是abc或ab。
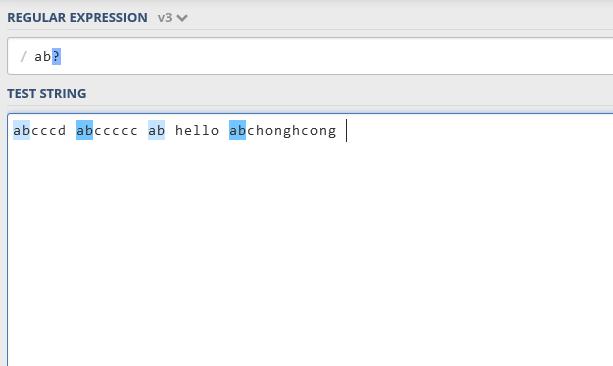
{n}表示与表达式中指定的确切数字(n)匹配。例如a{2}bc表示只能有两个”a”,然后是一个”bc”和一个”c”。
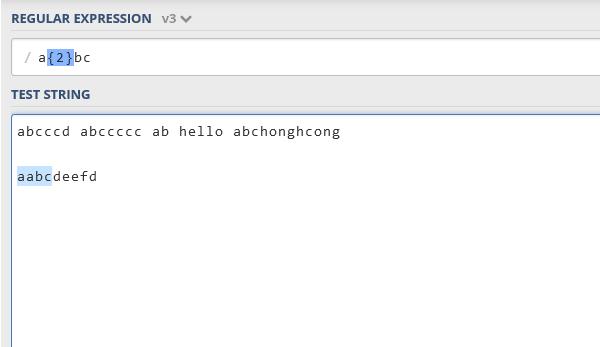
{n,}至少匹配指定的数字。必须具有n个或更多个前面的表达式,例如ab{2,}c表示必须具有个a,然后是两个或多个’b’,然后是c。
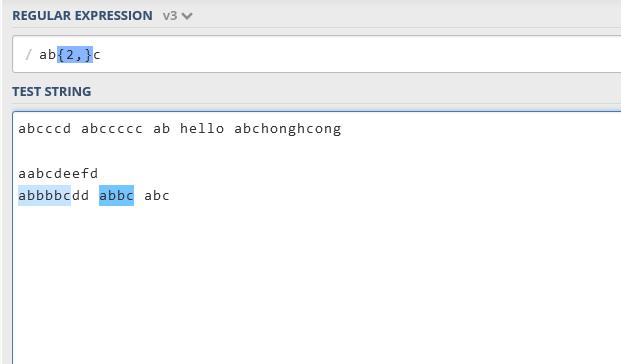
{n,m}表示在模式的n和m(含)之间匹配。这意味着您可以在前至后之间出现m到m个事件。例如ab{2,5}c表示abbc,abbbc,abbbbc,abbbbbc都是正确的。
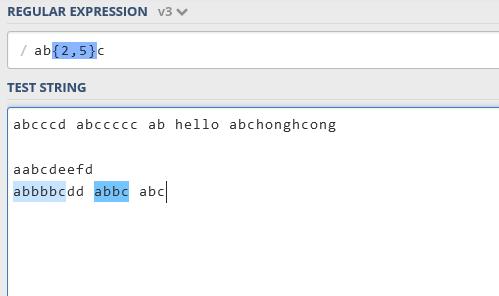
‘.’ 匹配所有非空格字符
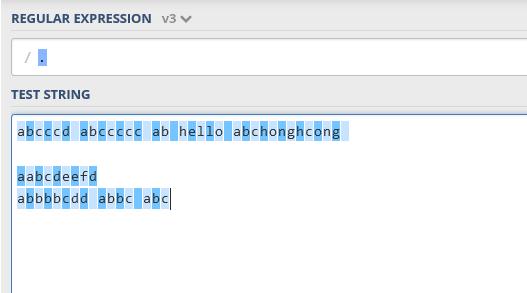
运算符(|| [] ^和())
|表示”或”。表示与左侧的表达式或右侧的表达式匹配。例如abc|abd表示文本应为abc或abd。

[]表示文本应与尖括号中的任何字符匹配,例如a[bc]表示文本应为”a”,后跟”b”或”c”。
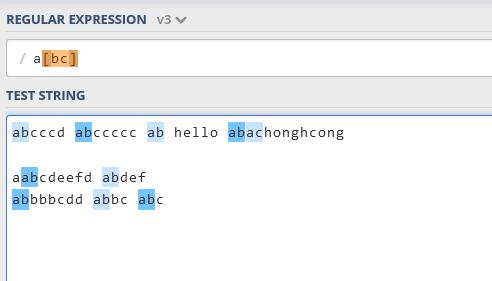
[0-9]%表示文本应为0到9之间的任何数字,后跟’%’
[a-zA-Z]表示匹配任何一个英文字母,只要介于az或AZ之间即可。
[abc]表示文本或字符串应为a或b或c。
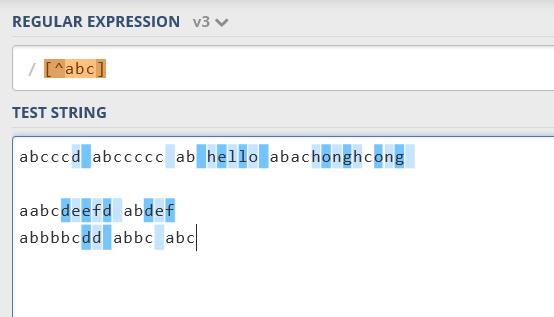
在任何表达式中添加”^”会否定该表达式的含义,例如[^abc]表示匹配任何除abc外的任何字符。
()表示分组,分组后可以在后续反向引用。反向引用存储与组匹配的字符串部分。可以使用符号$来引用特定的组。$1,$2…代表第一组1,第2组等。默认组为$0,表示字符串本身。例如,我们要删除行中的所有空格。此示例的正则表达式为以下代码片段:
private static String backReference(String text) {
String Pattern = "(\w+)([\s])";
return text.replaceAll(pattern, "$1");
}
上面代码中的正则表达式有2组:(\w+)和([\s])。表示字串是一系列单词字符(w+)后跟空格(s+)。后面一句,我们用组1($1)来替换整个文本,这样就删除了空格。
注意:在Java中,我们需要用一个斜杠对字符类(w和s)进行转义,否则会出现语法错误。
环视
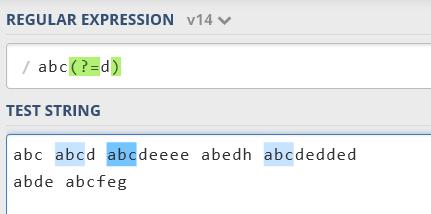
环视一种排除模式的方法。因此,可以说只有在特定字符串之前没有改符号时字符串才是有效的,反之亦然。例如,abc(?= d)只要与’d’相符,就会匹配’abc’。 “d”不会被匹配。这叫正向环视或者顺序环视。
环视不是所有语言都支持,不是通用的语法,但是妙用可以解决很多问题,比如我们要解析HTML语法:
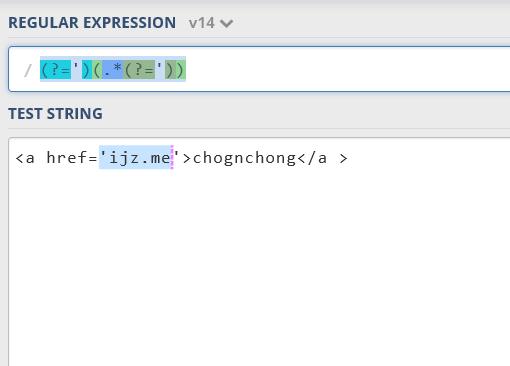
例如,对html中的一个连接
<a href='ijz.me'> chognchong</a > 我们要取其中的连接地址
(?=')(.*(?=')) 
还有一个表示对顺序环视的否定表达式,(?!pattern),表示如果’ab’后面没有’c’,则ab(?c)将匹配ab。
注意还有一个逆序环视,java中不支持,我们不介绍。
贪婪和懒惰
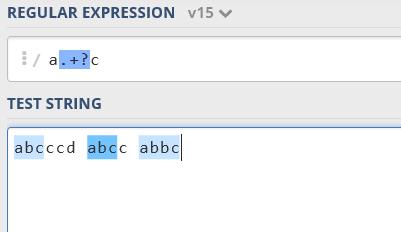
正则表达式中的的量词默认贪婪的,匹配时候会尽可能多的匹配,这样才能减少递归回溯搜索的次数,因而效率最高。例如,对于正则表达式a.+c,希望它表示文本应为’a’,后跟一个或多个非空格字符。可能的匹配匹配项为”abcccd”,”abcc”或”abbc”,都是可以的,但是由于贪婪的缘故,它将把所有文本(abcccd abcc abbc)作为一个并返回”abcccd abcc abbc”作为一个结果,因为如果您注意到,第一个字符是”a”,然后是任何其他字符中的一个或多个,它现在以与a.+c完全匹配的c结尾。

为了修改默认的,贪婪模式,只需在量词前面添加问号(?),这样使量词就会只要匹配最少匹配的模式。这时,ab.+?c就会单独匹配各个字串,而不是整个字符串。
对此的更好应用是:假设您只想从<h1> Chongchong </h1>中单独获得标签<h1>和</h1>,则希望它的正则表达式为<.+>但实际上,它将捕获整个文本(<h1> Hello Chongchong</h1>)并将其作为一个整体处理。 这时候用?就可以解决
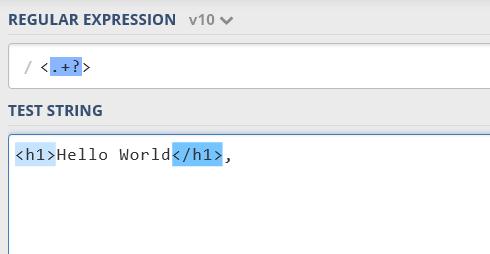
加’?’在量词前面有时被称为懒惰模式。
简而言之,贪婪模式表示匹配尽可能长的字符串,而懒惰模式表示匹配尽可能短的字符串。
字符类
字符类是代表一组字符的转义序列。下面列出了Java中的一些预定义字符:
d 表示任意数字;
s表示空格字符(tab 空格等);
w 任意单词字符;
D表示任意非数字;
S 表示任意非空格字符;
W表示任意非单词字符。
Java中使用正则表达式
好,学习了基础正则知识后,我们来转入到Java。来学习在Java中正则表达式的使用。在Java世界Java中的字符串类带有一个内置的布尔方法,该方法称为matchs,该方法用来对字符串进行正则匹配。
public static void main(String[] args) {
String value = “12345”;
System.out.println(“The Result is: “+value.matches(“\d{5}”));
}
上面的代码段将返回”结果为:true”,因为值(12345)恰好匹配5个字符。除5以外的任何其他值都将返回”结果为:false”。
Pattern/Matcher匹配
除了String类的matchs方法之外,java.util.regex包中也有正则表达式所需的类。它们由三类组成:
Pattern :这是正则表达式的编译表示。要使用此功能,必须首先在模式类中调用静态方法(编译),该方法返回一个模式对象。
Matcher :这是解释模式并针对输入字符串执行匹配操作的引擎。要获得一个对象,必须在Pattern对象上调用matcher方法。
PatternSyntaxException :这表示正则表达式模式中的错误
可以使用用模式Pattern/Matcher匹配字符串,一个例子是:
public static void main(String[] args) {
String value = "12345";
String regex = "\d{5}";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(value);
System.out.println("The Result is: "+matcher.matches());
} 获取匹配的字符
Matcher支持find和方法lookingAt()获取匹配的字符,一个例子:
Pattern p=Pattern.compile("\d+");
Matcher m=p.matcher("aaa2223bb");
m.find();//2223
m.start();//3
m.end();//7,这是2223后的索引号
m.group();//2223 也可以使用lookingAt()方法,只匹配之前的字符串:
Mathcer m2=m.matcher("2223bb");
m.lookingAt(); // 2223
m.start(); // 0,由于lookingAt()只能匹配前面的字符串, start()方法总是返回0
m.end(); // 4
m.group(); // 2223
性能问题
这样需要每次都先创建 Pattern/Matcher对象耗费资源太大,性能不行。使用Pattern/Matcher是在String类中实现了方法匹配。因此,对于匹配的每个字符串,它都会在匹配之前创建一个Pattern对象。为了解决这个问题,我们可以使用预编译方法,下面是一个实例:
{"nozzle","punjabi","waterlogged","guardrooms","roast","wattage","shortcuts","confidential","reprint","foxtrot","disposseslogsion","floodgate","unfriendliest","semimonthlies","dwellers","walkways","wastrels","dippers","engrlogossing","undertakings"};
List<String> resultStringMatches = matchUsingStringMatches(texts);
List<String> resultsPatternMatcher = matchUsingPatternMatcher(texts);
System.out.println("The Result for String matches is: "+resultStringMatches. toString ());
System.out.println("The Result for pattern/matcher is: "+resultStringMatches.toString());
}
private static List<String> matchUsingPatternMatcher(String[] texts) {
List<String> matchedList = new ArrayList<>();
String pattern = "[a-zA-Z]*log[a-zA-Z]*";
Pattern regexPattern = Pattern.compile(pattern);
Matcher matcher;
for (int i = 0; i < texts.length; i++) {
matcher = regexPattern.matcher(texts[i]);
if (matcher.matches()) {
matchedList.add(texts[i]);
}
}
return matchedList;
}
private static List<String> matchUsingStringMatches(String[] texts) {
String pattern = "[a-zA-Z]*log[a-zA-Z]*";
List<String> matchedList = new ArrayList<>();
for (int i = 0; i < texts.length; i++) {
//每次循环调用matches(pattern),都会创建一个pattern对象
if (texts[i].matches(pattern)) {
matchedList.add(texts[i]);
}
}
return matchedList;
}
} 上面的代码将数组中的所有元素与特定的正则表达式([a-zA-Z]*log[a-zA-Z]*)进行匹配。正则表达式用来获取所有带有”log”一词的文本。在与正则表达式匹配之前,必须先编译该表达式(Pattern.compile);
第一个方法matchUsingPatternMatcher()在寻找匹配项之前先编译模式,而第二个方法matchUsingStringMatches()创建一个新的模式对象
数组中每个元素的镜像(Pattern.compile())操作比较耗费内存,并且当数据/文本过多时,还可能会导致内存泄漏
因此,如果在处理大量数据比较关心性能时,请使用Pattern/Matcher类先进行编译,然后使用实例来匹配文本。


