
一、前言
分组查询是常见的SQL查询语句。首先,我们知道MySQL数据库分组功能主要是通过GROUP BY关键字来实现的,而且GROUP BY通常得配合 聚合函数 来使用用,比如说分组之后你可以计数(COUNT),求和(SUM),求平均数(AVG)等。但是今天我们要探讨的不是GROUP BY关键字学习和使用,而是一种有点另类的“分组”查询。
最近,项目上遇到这样一个功能需求。系统中存在资讯信息这样一个功能模块,用于发布一些和业务相关的活动动态,其中每条资讯信息都有一个所属类型(如科技类的资讯、娱乐类、军事类···)和浏览量字段。
而业务系统的官网上需要滚动展示一些热门资讯信息列表(浏览量越大代表越热门),而且每个类别的相关资讯记录至多显示3条,换句话:“按照资讯分类分组,取每组的前3条资讯信息列表”。
后面在尝试 GROUP BY 使用的各种方式都不能实现,最后在查阅相关资料后找到了实现的解决方法。
下面,我将模拟一些实际的测试数据重现问题的解决过程。
一、数据准备
数据库: MySQL 8.0社区版
表设计
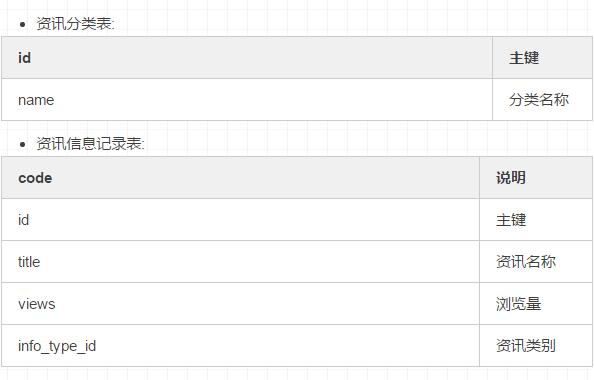
初始化 sql语句 :
资讯分类示例数据如下:
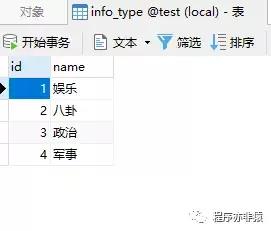
资讯分类
资讯信息记录表示例数据如下:
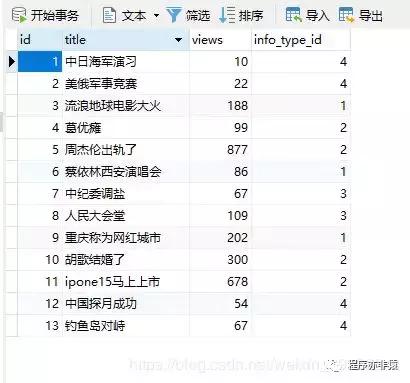
资讯信息记录表
需求 : 取热门的资讯信息列表且每个类别只取前3条。
二、核心思想
一般意义上我们在取前N条记录时候,都是根据某个业务字段进行降序排序,然后取前N条就能实现。
形如“select * from info order by views asc limit 0,3 ”,这条SQL就是取info表中的前3条记录。
但是当你仔细阅读我们的题目要求,你会发现: “它是让你每个类型下都要取浏览量的前3条记录” 。
一种比较简单但是粗暴的方式就是在 Java 代码中循环所有的资讯类型,取出每个类型的前3条记录,最后进行汇总。虽然这种方式也能实现我们的要求,但存在很严重的弊端,有可能会发送多次(夸张的说成百上千次也是有可能)sql语句,这种程序显然是有重大缺陷的。
但是,我们换一种思路。我们想在查询每条资讯记录时要是能查出其所在类型的排名就好了,然后根据排名字段进行过滤就好了。这时候我们就想到了子查询,而且MySQL是可以实现这样的功能子查询的。要计算出某条资讯信息的在同资讯分类下所有记录中排第几名,换成算出 有多少条浏览量比当前记录的浏览量高,然后根据具体的多少(N)条+1就是N+1就是当前记录所在其分类下的的排名。
假如以本文上面的示例数据说明:就是在计算每个资讯信息记录时,多计算出一列作为其“排名”字段,然后取“排名”字段的小于等于3的记录即可。如果这里还不是很理解的话,就先看下面的SQL,然后根据SQL再回过头来理解这段话。
三、SQL实现
方法一
SQL语句:

查询结果:
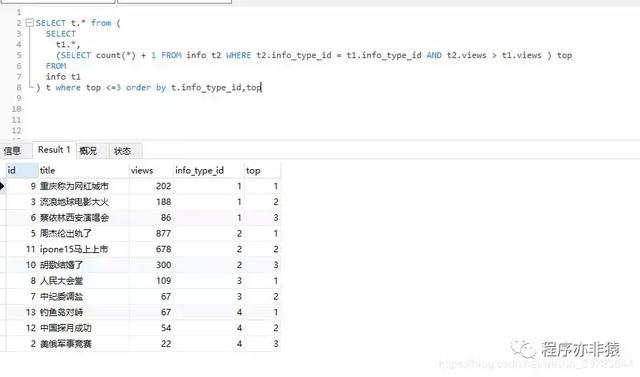
查询结果
说明:
分析top字段的子查询,发现其满足条件有两个:其一是info_type_id和当前记录的type_id相等;其二是info表所有记录大于
当前记录的浏览量且info_type_id相等的记录数量(假设为N),所有N+1就等于当前记录在其分类下的按照浏览量降序排名。
方法二
SQL语句:

查询结果

说明: 方法二可以看做是方法一的变体。
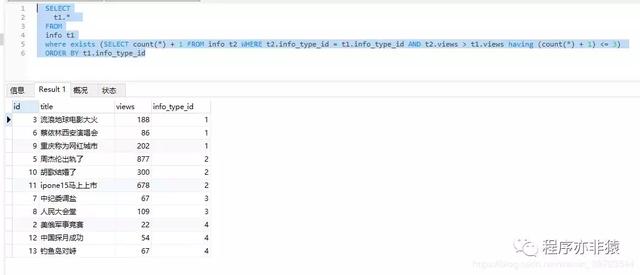
方法三
SQL语句
SELECT t1.* FROM info t1 where exists (SELECT count(*) + 1 FROM info t2 WHERE t2.info_type_id = t1.info_type_id AND t2.views > t1.views having (count(*) + 1) <= 3) ORDER BY t1.info_type_id
查询结果:
四、小结
其实,有时候在面临业务难题的时候,困难的地方往往不在技术本身,而在于我们解决问题的思维方式。
就正如案例中求记录的所在分类的排名,把其对等的“转换成有多少条同类别的记录的浏览量比当前记录的大(count聚合函数)”
问题马上就迎刃而解了。
原文来自微信公众号:程序亦非猿


