今日寄语
爬虫学的好,监狱进的早,
爬虫学的6,牢饭吃个够。

今天学习内容
- HttpClient抓取数据
- Jsoup解析数据
HttpClient
HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性,它不仅使客户端发送Http请求变得容易,而且也方便开发人员测试接口(基于Http协议的),提高了开发的效率,也方便提高代码的健壮性。
HttpClient的主要功能:
- 实现了所有 HTTP 的方法(GET、POST、PUT、HEAD、DELETE、HEAD、OPTIONS 等)
- 支持 HTTPS 协议
- 支持代理服务器(Nginx等)等
- 支持自动(跳转)转向
- 通过Http代理建立透明的连接。
Get请求
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("#34;);
CloseableHttpResponse response = httpClient.execute(httpGet);
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity, "utf8");
System.out.println(content);
}
if(response != null){
response.close();
}
if(httpClient != null){
httpClient.close();
}
} 请求结果
带参数Get请求
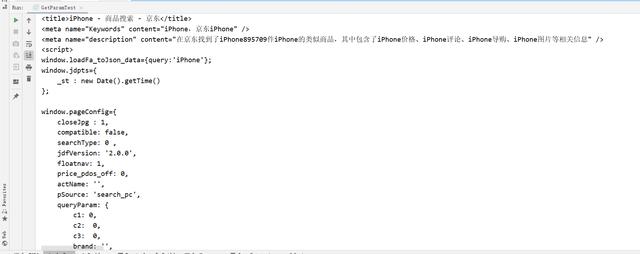
public static void main(String[] args) throws URISyntaxException, IOException {
CloseableHttpClient httpClient = HttpClients.createDefault();
URIBuilder uriBuilder = new URIBuilder("#34;);
uriBuilder.setParameter("keyword","iPhone");
HttpGet httpGet = new HttpGet(uriBuilder.build());
CloseableHttpResponse response = httpClient.execute(httpGet);
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity, "utf8");
System.out.println(content);
}
if(response != null ){
response.close();
}
if(httpClient != null){
httpClient.close();
}
} 运行结果
Post请求
public static void main(String[] args) throws IOException {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpPost httpPost = new HttpPost("#34;);
CloseableHttpResponse response = httpClient.execute(httpPost);
if (response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity, "utf8");
System.out.println(content);
}
if(response != null){
response.close();
}
if(httpClient != null){
httpClient.close();
}
} 带参数Post请求
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpPost httpPost = new HttpPost("#34;);
ArrayList<NameValuePair> params = new ArrayList<NameValuePair>();
params.add(new BasicNameValuePair("key", "java"));
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(params, "utf8");
httpPost.setEntity(formEntity);
CloseableHttpResponse response = httpClient.execute(httpPost);
if (response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity, "utf8");
System.out.println(content);
}
if (response != null) {
response.close();
}
if (httpClient != null){
httpClient.close();
}
} 连接池
public static void main(String[] args) throws IOException {
//创建连接池管理器
PoolingHttpClientConnectionManager pool = new PoolingHttpClientConnectionManager();
//设置最大连接数
pool.setMaxTotal(100);
//设置每个主机最大连接数
pool.setDefaultMaxPerRoute(10);
CloseableHttpClient httpClient = HttpClients.custom().setConnectionManager(pool).build();
HttpGet httpGet = new HttpGet("#34;);
CloseableHttpResponse response = httpClient.execute(httpGet);
if(response.getStatusLine().getStatusCode() == 200){
HttpEntity entity = response.getEntity();
String content = EntityUtils.toString(entity, "utf8");
System.out.println(content);
}
if(response != null){
response.close();
}
} Jsoup解析
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
主要功能
- 从URL中,文件或字符串中解析HTML
- 使用DOM或CSS选择器查找,取出数据
- 可操作HTML元素,属性,文本
jsoup依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.5</version>
</dependency>
<!--Jsoup-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency> 解析URL
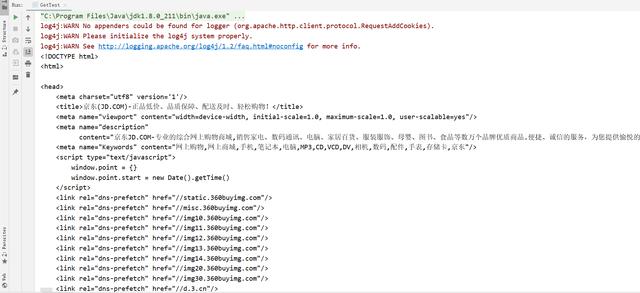
public void testUrl() throws Exception {
Document doc = Jsoup.parse(new URL("#34;), 1000);
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
} 解析字符串
public void testString() throws IOException {
String html = FileUtils.readFileToString(new File("d:test.html"), "utf8");
Document doc = Jsoup.parse(html);
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
} 解析文件
public void testFile() throws IOException {
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
String title = doc.getElementsByTag("title").first().text();
System.out.println(title);
} 元素获取
测试代码
<html>
<head>
<title>传智播客官网-一样的教育,不一样的品质</title>
</head>
<body>
<div class="city">
<h3 id="city_bj">北京中心</h3>
<fb:img src="/2018czgw/images/slogan.jpg" class="slogan"/>
<div class="city_in">
<div class="city_con" style="display: none;">
<ul>
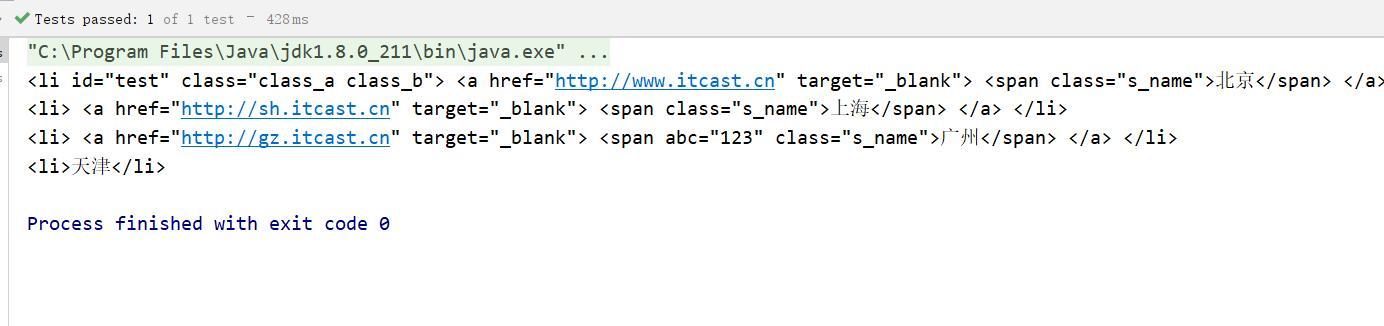
<li id="test" class="class_a class_b">
<a href="#34; target="_blank">
<span class="s_name">北京</span>
</a>
</li>
<li>
<a href="#34; target="_blank">
<span class="s_name">上海</span>
</a>
</li>
<li>
<a href="#34; target="_blank">
<span abc="123" class="s_name">广州</span>
</a>
</li>
<ul>
<li>天津</li>
</ul>
</ul>
</div>
</div>
</div>
</body>
</html>
- 根据id查询元素getElementById
public void getElementByIdTest() throws IOException {
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Element element = doc.getElementById("city_bj");
System.out.println(element);
} 运行结果
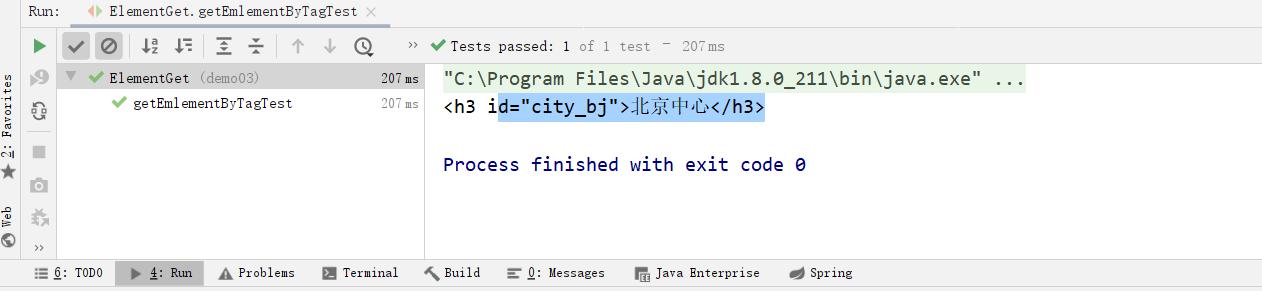
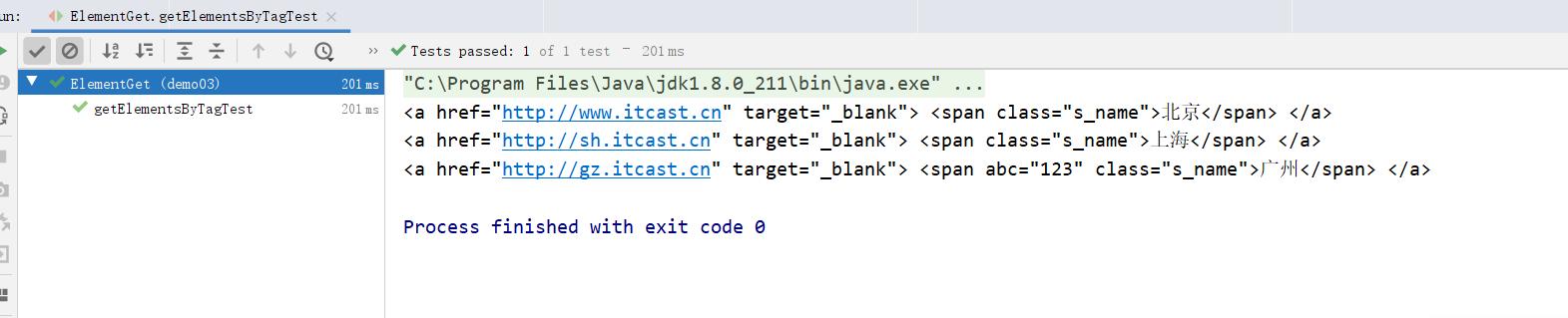
- 根据标签获取元素getElementsByTag
public void getElementsByAttribute() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements elements = doc.getElementsByAttribute("abc");
System.out.println(elements);
} 运行结果
- 根据class获取元素getElementsByClass
public void getElementsByClassTest()throws Exception{
Document doc = Jsoup.parse(new File("C:test.html"), "utf8");
Elements element = doc.getElementsByClass("city_in");
System.out.println(element);
} 运行结果

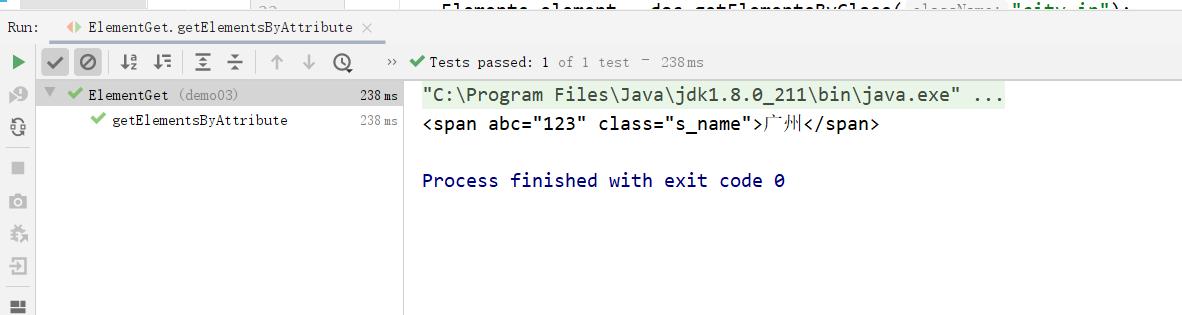
- 根据属性获取元素getElementsByAttribute
public void getElementsByAttribute() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements elements = doc.getElementsByAttribute("abc");
System.out.println(elements);
} 运行结果
元素中获取数据
- 从元素中获取id
public void idTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Element element = doc.getElementById("test");
String str = element.id();
System.out.println(str);
} 运行结果

- 从元素中获取className
public void classNameTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Element element = doc.getElementById("test");
String str = element.className();
System.out.println(str);
} 运行结果

- 从元素中获取属性的值attr
public void attrTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Element element = doc.getElementById("test");
String str = element.attr("id" );
System.out.println(str);
} 运行结果

- 从元素中获取文本内容text
public void textTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Element element = doc.getElementById("test");
String str = element.text();
System.out.println(str);
} 运行结果

选择器语法
- tagname: 通过标签查找元素
public void tagNameTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements elements = doc.select("span");
System.out.println(elements);
} 运行结果

- #id: 通过ID查找元素
public void idTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements elements = doc.select("#city_bj");
System.out.println(elements);
} 运行结果

- .class: 通过class名称查找元素
public void classTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements elements = doc.select(".class_a");
System.out.println(elements);
} 运行结果

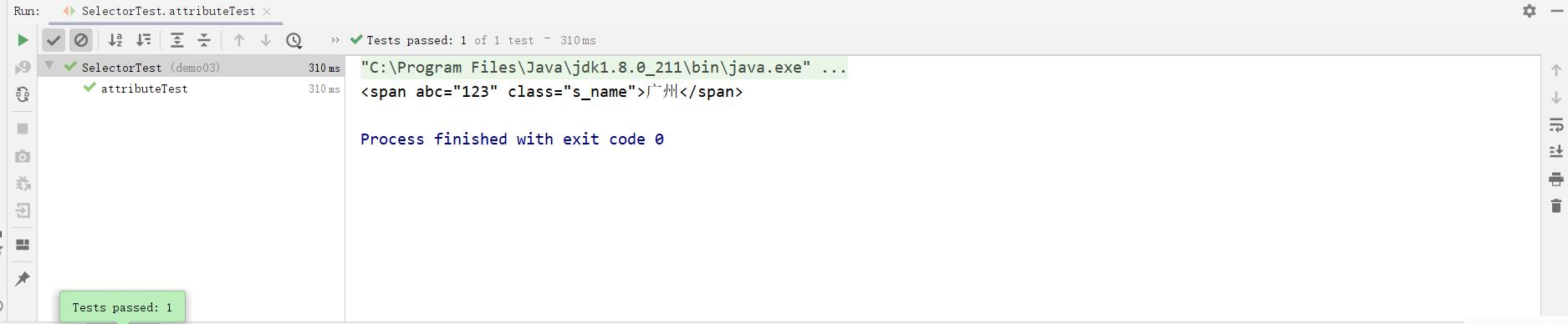
- [attribute]: 利用属性查找元素
public void attributeTest () throws Exception{
Document doc = Jsoup.parse(new File("c:test.html "), "utf8");
Elements select = doc.select("[abc]");
System.out.println(select);
} 运行结果
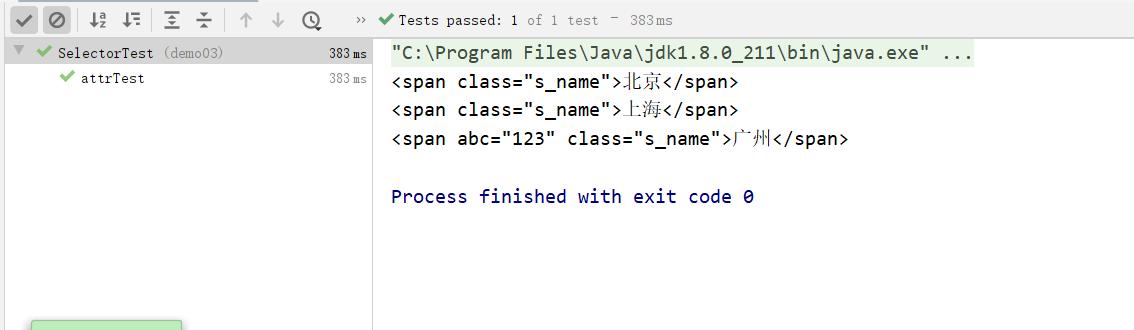
- [attr=value]: 利用属性值来查找元素
public void attrTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements elements = doc.select("[class=s_name]");
System.out.println(elements);
} 运行结果
select选择器组合使用
- el#id : 元素+ID,比如: h3#city_bj
public void elidTest() throws IOException {
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements el = doc.select("h3#city_bj");
System.out.println(el);
}
运行结果

- el.class : 元素+class,比如: li.class_a
public void elClassTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements el = doc.select("li.class_a");
System.out.println(el);
} 运行结果
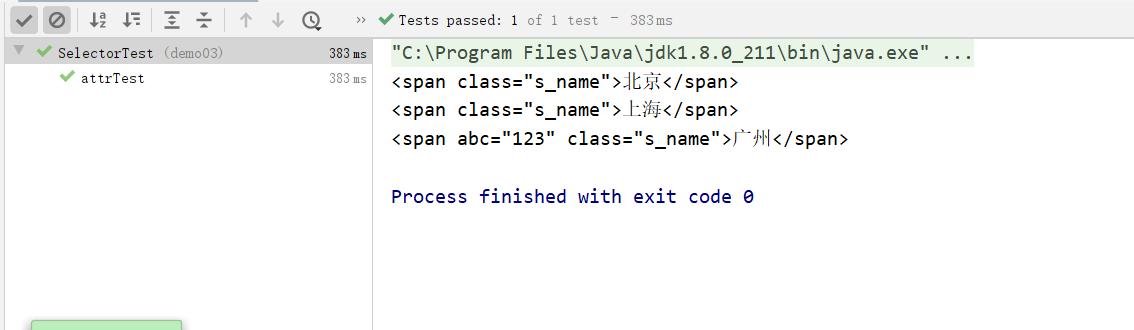
- el[attr] : 元素+属性名,比如: span[abc]
public void elAttrTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements el = doc.select("span[abc]");
System.out.println(el);
} 运行结果
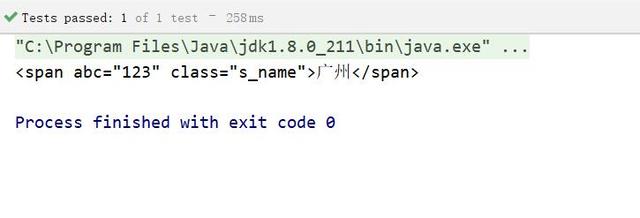
- 任意组合 : 比如:span[abc].s_name
- ancestor child : 查找某个元素下的元素,比如:.city_con li 查找”city_con”下的所有li
public void ancestorTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements el = doc.select(".city_con li");
System.out.println(el);
} 运行结果
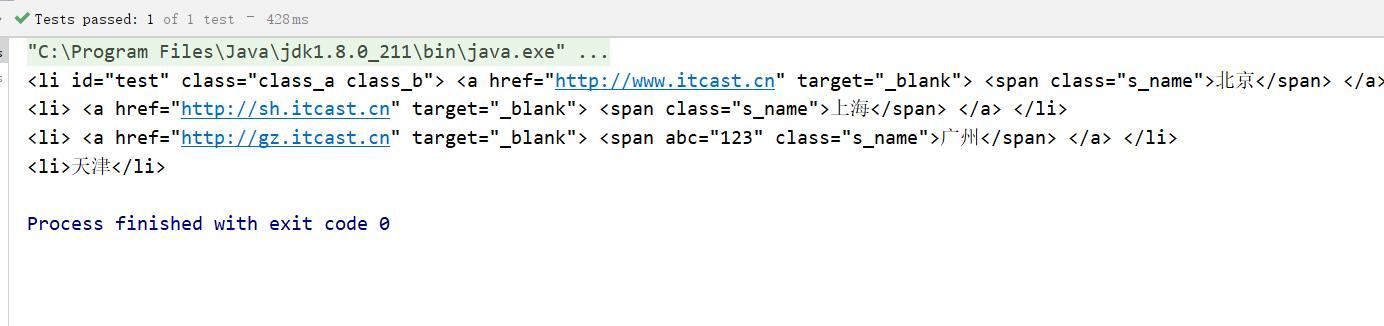
- parent > child : 查找某个父元素下的直接子元素,比如:.city_con > ul > li: 查找city_con第一级(直接子元素)的ul,再找所有ul下的第一级li
public void ancestorTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements el = doc.select(".city_con ul > li");
System.out.println(el);
} 运行结果
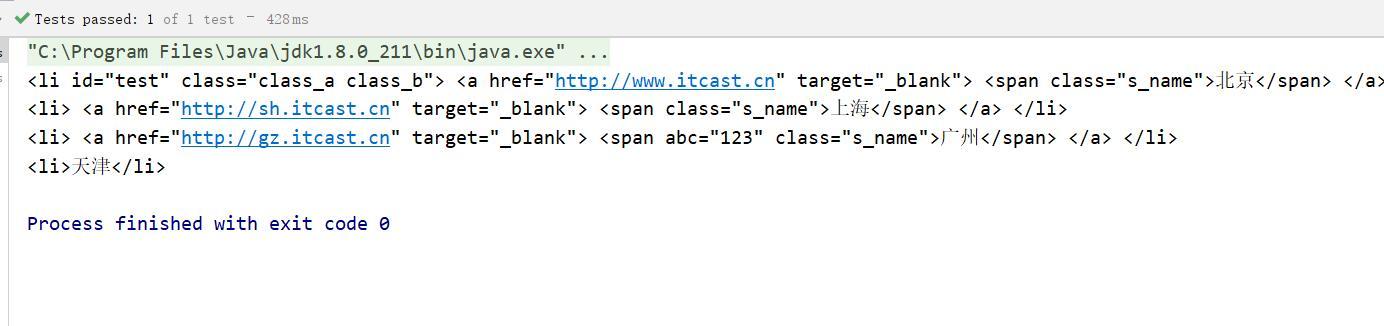
- parent > * : 查找某个父元素下所有直接子元素
public void ancestorTest() throws Exception{
Document doc = Jsoup.parse(new File("c:test.html"), "utf8");
Elements el = doc.select(".city_con ul > *");
System.out.println(el);
} 运行结果