简介
java 8引入 Stream 这个新特性之后,通过使用 lambda表达式 增强集合的功能,使程序员通过声明式的方式,快速和便捷的对批量数据进行过滤、转换、分组规约等操作,同时提高编程效率和代码可读性,可以说是一个真正的开发利器。本章我通过一个简单的示例,带领大家理解Stream的内部原理。
继承体系
在进入示例之前,我们先来看一下Stream的类继承结构。
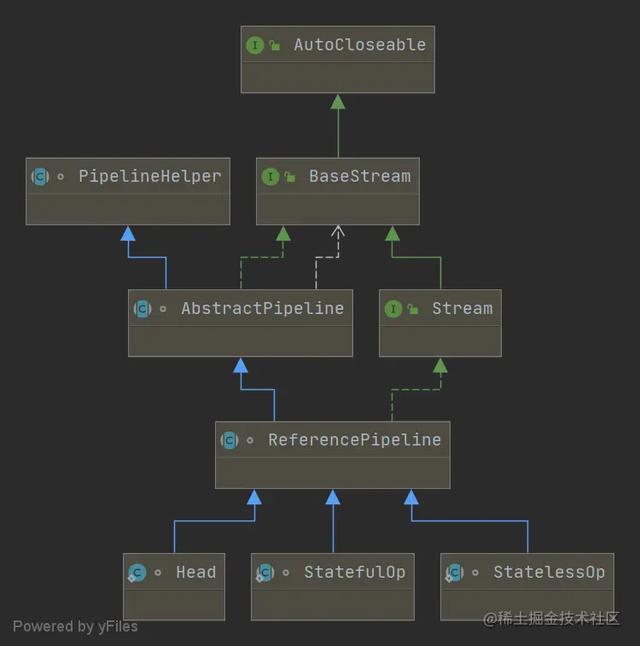
图中展示的是ReferencePipeline的继承关系,Stream和ReferencePipeline都是针对引用类型定义的接口和类,还有针对int、 Long 、double基础类型的流 Int Stream、LongStream、DoubleStream、IntPipeline、LongPipeline和DoublePipeline。本章只打算讲解引用类型的流,也就是大家常用的Stream,后面会有专门的章节来讲解基础类型的流,下面大致说明一下各个类和接口的职责功能。
- BaseStream: 所有Stream都继承自这个接口,主要声明了并行流和串行流的转换,判断流类型等方法。
- Stream: 继承BaseStream接口,提供了所有引用类型的中间操作和终止操作方法,什么是中间操作和终止操作,后面会详细讲解。
- PipelineHelper: 流管道的帮助类,定义了管道的基础方法,由AbstractPipeline实现。
- AbstractPipeline: 流管道基础类,继承PipelineHelper并且实现了继承BaseStream接口接口,所有的流都继承这个类,内部通过 双向链表 的结构来维护管道之间的关系。
- ReferencePipeline: 引用类型的管道类,继承了AbstractPipeline,连接管道的能力。同时实现了Stream接口,所以具备相应的流操作功能。
- Head: ReferencePipeline的内部类,同时也继承自ReferencePipeline,构建的Stream对象其实就是这个类的实例。
- StatelessOp: 同样是ReferencePipeline的内部类,并且继承了ReferencePipeline,调用流的无状态操作方法会返回这个类的子类实例。
- StatefulOp: 同上,不过表示有状态操作。
下面我们来看看顶层接口类的方法和字段声明,本章只粗略的讲解BaseStream、PipelineHelper和AbstractPipeline,其它的留到后面的章节详细讲解。
BaseStream
//返回流代表集合的 迭代器
iterator <T> iterator();
//返回流元素的Spliterator,什么是Spliterator,翻译成中文是分离器,
//目前大家只需要知道这是一个类似迭代器的东西,主要用于终止操作的时候遍历元素
Spliterator<T> spliterator();
//返回流是不是并行的
boolean isParallel();
//返回串行流
S sequential();
//返回并行流
S parallel();
复制代码 PipelineHelper
//返回流类型,有REFERENCE、INT_VALUE、LONG_VALUE、DOUBLE_VALUE类型
abstract StreamShape getSourceShape();
//返回流合并和操作的标志,这个过于复杂,不打算深讲
abstract int getStreamAndOpFlags();
//返回流元素大小,如果不确定将返回-1
abstract<P_IN> long exactOutputSizeIfKnown(Spliterator<P_IN> spliterator);
//由终止操作间接调用,调用wrapSink方法构建Sink链表,调用copyInto方法完成数据操作
abstract<P_IN, S extends Sink<P_OUT>> S wrapAnd copy Into(S sink, Spliterator<P_IN> spliterator);
//将Spliterator中的元素提供给Sink消费
abstract<P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
//类似copyInto,区别在于这个方法用于短路操作
abstract <P_IN> Void copyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
//包装Sink形成Sink链
abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
abstract<P_IN> Spliterator<P_OUT> wrapSpliterator(Spliterator<P_IN> spliterator);
abstract Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown,
IntFunction<P_OUT[]> generator);
//并行流调用,本系列文章不涉及
abstract<P_IN> Node<P_OUT> evaluate(Spliterator<P_IN> spliterator,
boolean flatten,
IntFunction<P_OUT[]> generator);
复制代码 AbstractPipeline
//pipeline 链表 的头结点
private final AbstractPipeline sourceStage;
//前一个节点
private final AbstractPipeline previousStage;
protected final int sourceOrOpFlags;
//下一个节点
private AbstractPipeline nextStage;
//节点的深度
private int depth;
private int combinedFlags;
//源Spliterator
private Spliterator<?> sourceSpliterator;
//同sourceSpliterator
private Supplier<? extends Spliterator<?>> sourceSupplier;
//pipeline是否已经被连接或者消费
private boolean linkedOrConsumed;
//pipeline上是否有有状态的操作
private boolean sourceAnyStateful;
private Runnable sourceCloseAction;
//是否是并行流
private boolean parallel;
复制代码 - sourceStage:pipeline链表的头结点,如果当前节点就是头节点,那么将指向自己。
- previousStage:链表的上一个节点。
- nextStage:链表的下一个节点。
- depth:节点的深度,头结点深度为0,后续每调用一个中间操作,返回的Stream节点深度加1。
- sourceSpliterator:源Spliterator。
- sourceSupplier:同sourceSpliterator。
- linkedOrConsumed:pipeline是否已经被连接或者消费,如果为true,再调用操作方法将抛出Illegal State Exception异常。
- sourceAnyStateful:pipeline上是否有有状态的操作,如果有调用有状态中间操作,那么头结点的sourceAnyStateful会被设置为true。
一个简单的示例
我们先来看一个使用Stream的例子
Stream.of("java", " scala ", "go", " python ")
.map(String::length)
.filter(len -> len <= 4)
. forEach (System.out::println);
复制代码 很显然,例子中的运行结果是在控制台输出4和2:
4
2
复制代码 上面的代码中通过Stream#of()方法创建一个源Stream实例,然后依次调用map()、filter()中间操作方法,最终调用 ForEach ()终止操作方法得到最终的结果。其中中间操作不会立即执行声明的逻辑,只有调用终止操作之后才触发所有的逻辑。
Stream的构建
我们先来看一下这个例子中Stream是如何构建的,方法Stream#of():
public static <T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
复制代码 Stream#of()是一个工厂方法,会调用到Arrays#stream():
public static <T> Stream<T> stream(T[] array) {
return stream(array, 0, array.length);
}
复制代码 然后调用重载方法
public static <T> Stream<T> stream(T[] array, int startInclusive, int endExclusive) {
return StreamSupport.stream(spliterator(array, startInclusive, endExclusive), false);
}
复制代码 构建一个Spliterator,目前我们只要知道它是一个类似迭代器一样的东西就行了,后面会详细讲解,所以还是看StreamSupport#stream()方法:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
复制代码 构建一个Head实例,Head就是上面讲到的ReferencePipeline的子类,我们看一下它的 构造方法 :
Head(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
复制代码 调用父亲 构造器 :
ReferencePipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
super(source, sourceFlags, parallel);
}
复制代码 最终调用到AbstractPipeline的构造方法:
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
//由于是头结点,所以上一个节点为null
this.previousStage = null;
//源Spliterator
this.sourceSpliterator = source;
//由于是头结点,所以sourceStage指向自己
this.sourceStage = this;
//涉及流合并和操作标记,过于复杂,暂时不讲解
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
//头结点的深度是0
this.depth = 0;
//并行流标记
this.parallel = parallel;
}
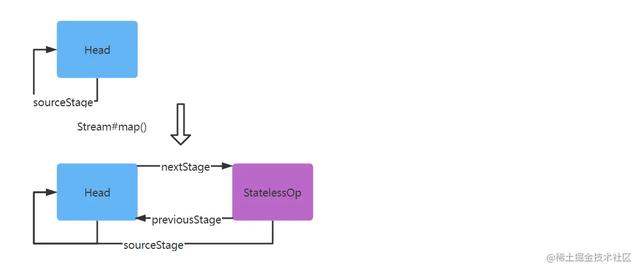
复制代码 所有说明都在源码上面注释了,从上面源码可以得出结论,构建Stream返回的是一个ReferencePipeline.Head实例,它的结构如下:

中间操作
map()方法
接下来我们看一下map()方法调用逻辑,首先会调用ReferencePipeline#map():
public final <R> Stream<R> map( Function <? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
//返回一个StatelessOp子类实例,传入Head实例
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
//这里先不展开,不然容易饶晕,后面再详细讲解
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
复制代码 我们发现这里创建了一个StatelessOp的子类实例,StatelessOp也就是上面讲到的ReferencePipeline的内部类和子类,它是一个无状态的中间操作,构造方法如下:
StatelessOp(AbstractPipeline<?, E_IN, ?> upstream,
StreamShape inputShape,
int opFlags) {
super(upstream, opFlags);
assert upstream.getOutputShape() == inputShape;
}
复制代码 还是调用ReferencePipeline的构造方法:
ReferencePipeline(AbstractPipeline<?, P_IN, ?> upstream, int opFlags) {
super(upstream, opFlags);
}
复制代码 最终还是调用到AbstractPipeline的构造方法:
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
//这里也解释了Stream只能被连接或者消费一次,否则会抛出异常
if (previousStage.linkedOrConsumed)
throw new IllegalState Exception (MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
//构建双向链表,将上一个节点也就是Head的nextStage指向自己
previousStage.nextStage = this;
//将当前节点的previousStage指向上一个节点,也就是Head对象
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
//将当前节点的sourceStage指向上一个节点的sourceStage,也就是Head对象
this.sourceStage = previousStage.sourceStage;
//如果当前操作是有状态的,那么sourceStage也就是Head对象sourceAnyStateful设置为true,这里是无状态的,跳过
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
//深度加1
this.depth = previousStage.depth + 1;
}
复制代码 注意构造参数,这个明显不是构建Stream的时候调用的构造器,上面传入的 previous Stage就是构建Stream时返回的Head对象。
所以经过Stream.of(“java”, “scala”, “go”, “python”).map(String::length)调用之后,返回的是ReferencePipeline.StatelessOp的子类实例,结构变化如下:
filter()方法
filter()方法首先会调用到ReferencePipeline#filter()方法:
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
////返回一个StatelessOp子类实例,注意与上面对比,这里传入的是map()方法体里面的StatelessOp子类实例
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
//暂不讲解
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
复制代码 与ReferencePipeline#map()方法一样,最终也会返回一个StatelessOp子类实例,结构变化如下:
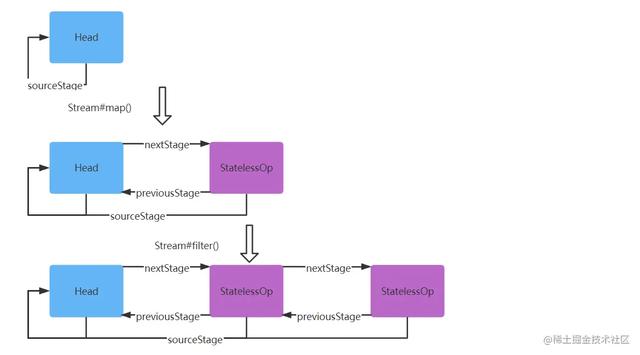
终止操作
示例中最后调用的是Stream#forEach()方法,forEach()是一个终止操作,会触发上面声明的逻辑真正执行,这里会调用到ReferencePipeline#forEach()方法:
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
复制代码 ForEachOps#makeRef()是一个工厂方法,会返回一个TerminalOp实例,它代表的就是终止操作,这里返回的是ForEachOp.OfRef:
public static <T> Terminal Op<T, Void> makeRef(Consumer<? super T> action,
boolean ordered) {
Objects.requireNonNull(action);
return new ForEachOp.OfRef<>(action, ordered);
}
复制代码 我们先来看一下OfRef:
static final class OfRef<T> extends ForEachOp<T> {
final Consumer<? super T> consumer;
//这里传入的consumer就是forEach()传入的lambda
OfRef(Consumer<? super T> consumer, boolean ordered) {
super(ordered);
this.consumer = consumer;
}
//在这个方法中真正的调用lambda
@Override
public void accept(T t) {
consumer.accept(t);
}
}
复制代码 OfRef继承自ForEachOp,那我们来看一下它的定义:
static abstract class ForEachOp<T>
implements TerminalOp<T, Void>, TerminalSink<T, Void> {
....
}
复制代码 ForEachOp实现了TerminalOp和TerminalSink接口,TerminalOp主要提供了evaluateParallel()和evaluateSequential()方法:
//并行流调用的方法,我们不关注
default <P_IN> R evaluateParallel(PipelineHelper<E_IN> helper,
Spliterator<P_IN> spliterator) {
if (Tripwire.ENABLED)
Tripwire.trip(getClass(), "{0} triggering TerminalOp.evaluateParallel serial default");
return evaluateSequential(helper, spliterator);
}
//这个方法在Stream终止操作当中会调用到,主要作用是封装sink链,执行数据处理逻辑,非常重要,后面会讲到
<P_IN> R evaluateSequential(PipelineHelper<E_IN> helper,
Spliterator<P_IN> spliterator);
复制代码 ForEachOp实现的另外一个接口是TerminalSink,它的接口声明如下:
interface TerminalSink<T, R> extends Sink<T>, Supplier<R> { }
复制代码 可以看到它聚合了Sink和Supplier接口,Supplier就是一个函数式接口,只有一个get()方法,我们来看一下Sink的定义:
interface Sink<T> extends Consumer<T> {
//发送数据到sink之前调用的方法
default void begin(long size) {}
//在所有数据被发送到sink后调用的方法
default void end() {}
//用于判断是否短路
default boolean cancellationRequested() {
return false;
}
}
复制代码 Sink继承了Consumer接口,拥有accept()方法。我们来看一下它的每一个方法是干什么的:
- begin():这个方法在发送数据到sink之前被调用,通常用于状态的清理和重置。对于无状态操作,一般只会向下游的sink传播;对于有状态的操作,还会初始化sink的一些内部变量。后面针对每一个sink实现类,我们会详细分析。
- accept():这个方法继承自Consumer,每一个元素被发送到sink,都会调用到这个方法。
- end():在流上的数据被sink处理完成之后,会调用这个方法。对于无状态操作,一般除了向下游传播,不会做其它操作;对于有状态的操作,会做一些清理或者更复杂的工作。
- cancellationRequested():这个方法用于判断是否可以提前结束,也就是我们所说的是否短路。
终止操作forEach()里面,返回了ForEachOp.OfRef实例之后就会调用evaluate()方法:
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
复制代码 这个方法在AbstractPipeline里面实现:
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
//校验Stream是否已经被消费过,更改状态
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
//示例中是串行流,所以只关心这个方法
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
复制代码 evaluate()做了linkedOrConsumed的状态校验,最终调用TerminalOp#evaluateSequential()方法,传入的参数是PipelineHelper和Spliterator。在本例中PipelineHelper就是Stream#filter()方法中的StatelessOp子类实例,忘记了的记得倒回去看哟。至于sourceSpliterator()返回的是什么Spliterator,我们进入这个方法看一下:
private Spliterator<?> sourceSpliterator(int terminalFlags) {
// Get the source spliterator of the pipeline
Spliterator<?> spliterator = null;
//实际走的是这个逻辑
if (sourceStage.sourceSpliterator != null) {
spliterator = sourceStage.sourceSpliterator;
sourceStage.sourceSpliterator = null;
}
else if (sourceStage.sourceSupplier != null) {
spliterator = (Spliterator<?>) sourceStage.sourceSupplier.get();
sourceStage.sourceSupplier = null;
}
else {
throw new IllegalStateException(MSG_CONSUMED);
}
//并行流的逻辑
if (isParallel() && sourceStage.sourceAnyStateful) {
...
}
if (terminalFlags != 0) {
// Apply flags from the terminal operation to last pipeline stage
combinedFlags = StreamOpFlag.combineOpFlags(terminalFlags, combinedFlags);
}
return spliterator;
}
复制代码 这个方法比较长,省略了无关代码,基本上都是并行流处理和返回新的Spliterator,串行流只会返回Head的sourceSpliterator。evaluate()最终调用的是ForEachOp.OfRef#evaluateSequential(),这个方法在ForEach中实现:
public <S> Void evaluateSequential(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
return helper.wrapAndCopyInto(this, spliterator).get();
}
复制代码 调用StatelessOp的wrapAndCopyInto()方法,传入ForEachOp.OfRef实例和spliterator,进入wrapAndCopyInto()看一下,AbstractPipeline#wrapAndCopyInto():
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
复制代码 首先调用AbstractPipeline#wrapSink()返回一个新的sink:
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
复制代码 这个方法的逻辑就是从Pipeline双向链表从后向前遍历直到Head,依次调用opWrapSink()方法包装一个新的Sink。我们来分析一下在本示例中构造的是一个什么样的sink:
- 首先,调用Stream.filter()方法中StatelessOp实例的opWrapSink()方法,传入的sink是代表终止操作的ForEachOp.OfRef实例:
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
//调用的就是这个方法
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
复制代码 我再次把代码放出来了,可以看到opWrapSink()返回的是一个Sink.ChainedReference实例,Sink.ChainedReference又是什么鬼?我们进入看一下:
static abstract class ChainedReference<T, E_OUT> implements Sink<T> {
protected final Sink<? super E_OUT> downstream;
public ChainedReference(Sink<? super E_OUT> downstream) {
this.downstream = Objects.requireNonNull(downstream);
}
@Override
public void begin(long size) {
downstream.begin(size);
}
@Override
public void end() {
downstream.end();
}
@Override
public boolean cancellationRequested() {
return downstream.cancellationRequested();
}
}
复制代码 ChainedReference实现了Sink接口,通过变量downstream形成一个连接下游sink的单链表,它实现的begin()、end()、cancellationRequested()方法都是向下游传播。所以在Pipeline链表上第一次迭代形成的sink链表结构如下:

- 我们再回到迭代逻辑:
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
复制代码 第二次调用的是Stream.map()方法中StatelessOp实例的opWrapSink()方法,传入的sink是filter方法中的Sink.ChainedReference实例:
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
//调用这个方法
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
复制代码 可以看到逻辑跟filter方法中的基本一致,都是返回一个Sink.ChainedReference子类实例,主要区别是accept()中的逻辑。所以经过第二次迭代形成的sink链表如下:
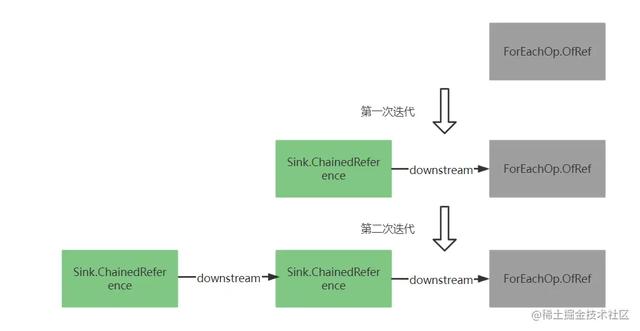
到这里sink链表就构造完成了,最终返回:
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
复制代码 可以看到for循环中的条件是p.depth > 0,并且Head#opWrapSink()会抛出UnsupportedOperationException异常,所以Head的opWrapSink()方法不会被调用。
final Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink) {
throw new UnsupportedOperationException();
}
复制代码 通过wrapSink()方法构造sink链表之后,会调用AbstractPipeline#copyInto()方法执行真正的数据处理逻辑:
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
//非短路操作,示例中进入的是这里的逻辑
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
//短路操作
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
复制代码 由于Stream#forEach()是非短路操作,所以进入的是上面的逻辑,通过调试也能够看出:
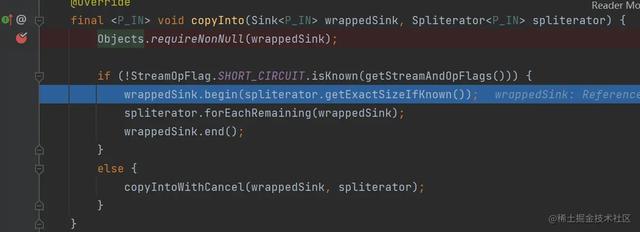
同时可以看到传入的sink就是上面分析的sink链表:
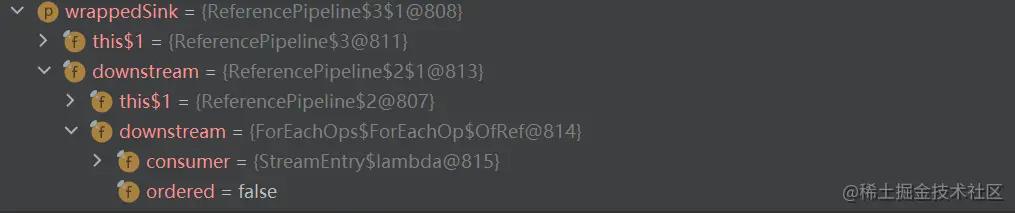
这里的逻辑分为三步,我们分开来讲解:
//1.调用sink链的begin()方法
wrappedSink.begin(spliterator.getExactSizeIfKnown());
//2.调用spliterator的forEachRemaining()方法
spliterator.forEachRemaining(wrappedSink);
//3.调用sink链的end()方法
wrappedSink.end();
复制代码 - 第一步:调用sink链的begin()方法,传入元素大小,这里通过spliterator#getExactSizeIfKnown()获取到,本例中是4,只是沿着sink链向下游传播,不做其它操作。
- 第二步:调用方法ArraySpliterator#forEachRemaining(),传入sink链,可以看到就是循环调用sink#accept()方法,传入数组元素:
public void forEachRemaining(Consumer<? super T> action) {
Object[] a; int i, hi; // hoist accesses and checks from loop
if (action == null)
throw new NullPointerException();
if ((a = array).length >= (hi = fence) &&
(i = index) >= 0 && i < (index = hi)) {
do { action.accept((T)a[i]); } while (++i < hi);
}
}
复制代码 经过sink链的流程如下:
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
复制代码 sink链头结点是Stream#map()方法里面的Sink.ChainedReference,元素经过函数String::length转换,然后传递给下一个sink:
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
复制代码 第二个sink节点是Stream#filter()方法中的Sink.ChainedReference,这里元素要经过函数len -> len <= 4判断返回true,才会传递到下一个节点:
static final class OfRef<T> extends ForEachOp<T> {
final Consumer<? super T> consumer;
OfRef(Consumer<? super T> consumer, boolean ordered) {
super(ordered);
this.consumer = consumer;
}
@Override
public void accept(T t) {
consumer.accept(t);
}
}
复制代码 最后一个节点是ForEachOp.OfRef,它的逻辑就是将前一个sink节点传递过来的元素都通过System.out::println打印到控制台。
- 第三步:调用sink链的end()方法,在这个例子中从sink头节点依次调用下一个节点的end()方法,什么都不做。
到这里使用Stream处理数据的流程和源码就分析完了。
总结
本文先通过介绍Stream的继承结构,以及分析顶层的接口和抽象类中的方法和字段,让大家对Stream这个家族有一个总体的认识。然后通过一个简单的例子,详细的讲解了Steam是怎么构建的,经过中间操作如何形成一个Pipeline链表,终止操作是如何将声明的函数构建为一个sink链表,Stream中的元素如何经过sink处理的。
写在最后
关于Java8中的Stream源码还有很多可以讲解的地方,比如有哪些方式创建Stream,中间操作是什么,有几种终止操作,Collector为什么有强大的分组规约能力,IntStream、LongStream、DoubleStream和普通Stream的关系。所以我打算写一系列文章、以专栏的形式,来详细讲解Stream相关的源码。
- 关于并行流,其中涉及到ForkJoinPool线程池、分治算法等更复杂的知识,将这些写进来会导致篇幅过大、不易阅读,所以本系列不打算讲解,大家略过就好,不会影响阅读。
- 关于StreamOpFlag,同理过于复杂,一来不易讲解,二来容易把大家绕晕,所以也不讲解。


