欢迎关注我的头条号:Wooola,10年Java软件开发及架构设计经验,专注于Java、Golang、微服务架构,致力于每天分享原创文章、快乐编码和开源技术。
前言
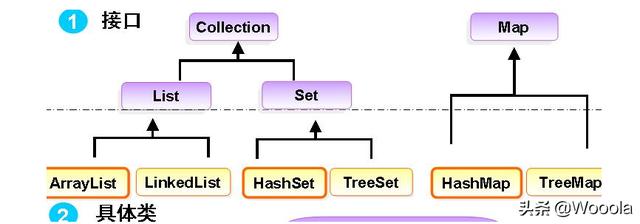
java的底层数据结构主要有 数组 、 链表 、hash 。
基于数组的集合
数组特点
元素的存储是用一个Object数组来维护的, 因此数组索引寻址查找快,但是在新增或者删除元素时,由于涉及到数组元素的复制以及新数组的内存开辟,所以新增或者删除元素性能差.
ArrayList 和 Vector 底层都是基于数组,两者之间主要区别是Vector的方法是线程安全。
集合扩容代码
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
集合底层数组元素复制代码
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
队列: Queue
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** The queued items */ final Object[] items;
}
java队列底层存储元素实质也是用的是Object数组,元素的删除在队列头,添加在队列尾。
ArrayBlockingQueue
实现接口 BlockingQueue,常用于生产者与消费者模式,中常用的阻塞有界队列, 先进先出-FIFO

基于链表的集合
链表特点
内存区间离散,占用内存较少,寻址困难,插入和删除容易。链表在插入、删除数据时比 数组( 线性表 ) 快,遍历比 数组 慢。
LinkedList
经典的双链表结构, 线程 不安全。
/** * Pointer to first node. * Invariant: (first == null && last == null) || * (first.prev == null && first.item != null) */transient Node<E> first; /** * Pointer to last node. * Invariant: (first == null && last == null) || * (last.next == null && last.item != null) */transient Node<E> last;
基于 哈希表 的集合:键值对key-value
hash的特点
数组 + 单链表
hash原理
哈希表依赖两个方法: hashCode 方法和equals方法,其原理是如果hashCode相同,则需要判断equals方式是否相等,如果相等说明元素存在,不相等则添加到集合。
HashMap (键值对key-value)
底层是 数组 + 单链表 的方式实现,其中jdk8中引入了红黑树对长度 > 8的链表进行优化
Map集合的数据结构仅仅针对键有效,与值无关,存储的是键值对形式的元素,键唯一,值可重复。线程不安全,效率高
注意,hashMap是允许Key为空的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
HashSet
HashSet底层是用一个HashMap来存储数据的,利用Map的key保证唯一性。其特点是元素无序且不重复,允许key为空。
LinkedHashSet
底层数据结构由链表和哈希表组成。由链表保证元素有序,由哈希表保证元素唯一。
TreeMap
TreeMap是由Entry对象为节点组成的一颗红黑树,是一种自平衡的 二叉树 ,元素的有序性通过元素的比较器:comparator来实现。
TreeSet
TreeSet 实际上就是用TreeMap来存储数据的
public TreeSet() {
this(new TreeMap<E,Object>());
}
底层数据结构是红黑树,是一种自平衡的二叉树,元素的有序性通过元素的比较器:comparator来实现。元素的唯一性是根据添加方法的返回值是否为空决定的。
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
其特点是元素不允许key为空且不能重复。


