前言
上篇只是简单的动手操作操作了流( Stream ),那 stream 到底是什么呢?
官方的简短定义:“ 从支持数据处理操作的源生成的元素序列 ”
分成三部分:
- 元素序列 :你可以简单将它类比于一样,不过集合说的是数据的集合,而 stream 重点在于表达计算。如我们之前说到的 filter、map、sorted、limit等等
- 源 :昨天我提到,如果了解过 Liunx 管道命令的朋友们,会知道,Liunx 的管道命令中的前一条命令的结果(输出流)就是执行下一条命令的输入流。 stream流其实也是类似的,每次执行完一个 filter、sorted 等等它们的返回值也是 stream 流,然后作为下一个操作的输入流,这种。
- 数据处理 :这里说的处理,就是那些filter、map、sorted、limit等。
你可以把它理解为概念上或是形式上的数据结构,而不是具体的。
只能遍历的一次 Stream
Stream 流和 迭代 器一样,它只能够迭代一次 。
当它遍历完的时候,我们就称它已经消费完了。如果还想重新执行操作,那么就只能从原来的地方再获取一个流啦。
/**
* 图个乐子
*/ public static List<String> list = Arrays.asList("医医","一一","花花","菡菡","春春","宁姐","...");
public static void main(String[] args) {
Stream<String> stream = list.stream();
stream.forEach(System.out::println);
stream.forEach(System.out::println);
}
复制代码 当执行第二句 stream.forEach(System.out::println); 时,会爆出如下异常:
Exception in thread "main" Java .lang.Illegal State Exception: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.sourceStageSpliterator(AbstractPipeline.java:279)
at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:580)
at com.nzc.stream02.Stream02Demo.main(Stream02Demo.java:25)
复制代码 stream has already been operated upon or closed :流已经被操作完或者关闭啦~
那么为什么流只能遍历一次呢?
我的回答肯定是 Java 中的设计是如此。
我们先来回忆一下我昨天没提到的一个知识点:
随便举一个例子,然后我们将 filter、map、limit、collect 都使用上。
List<Student> students = new ArrayList<>();
students.add(new Student("学生A", "大学1", 18, 98.0));
students.add(new Student("学生A", "大学1", 18, 91.0));
students.add(new Student("学生A", "大学1", 18, 90.0));
students.add(new Student("学生A", "大学1", 18, 76.0));
students.add(new Student("学生B", "大学1", 18, 91.0));
students.add(new Student("学生C", "大学1", 19, 65.0));
students.add(new Student("学生D", "大学2", 20, 80.0));
students.add(new Student("学生E", "大学2", 21, 78.0));
students.add(new Student("学生F", "大学2", 20, 67.0));
students.add(new Student("学生G", "大学3", 22, 87.0));
students.add(new Student("学生H", "大学3", 23, 79.0));
students.add(new Student("学生I", "大学3", 19, 92.0));
students.add(new Student("学生J", "大学4", 20, 84.0));
List<String> collect = students.stream().filter(student -> student.getAge() > 20).map(student -> student.getName()).limit(3).collect(Collectors.toList());
复制代码 昨天我没有具体说明这几步是如何执行的 。
画张图来简要的说明一下:
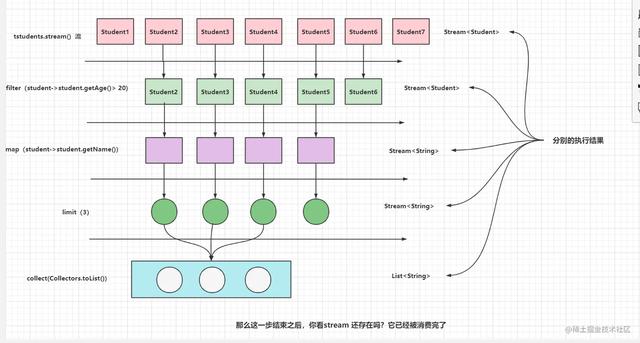
filter, 根据条件筛选掉一些元素
map,将元素转换成其他的形式
limit,将流进行截断,只获取其中的一部分
collect,这里主要就是将流转换成其他的集合对象,这一步也是流的终端操作,之后也会聊到。
在这里你可以看到Java 8中的 stream 的设计,就是只能遍历一次,并且当执行完终端操作的时候,流也是已经关闭或者说是消费完了。
流操作
上面刚刚提到了终端操作,这也是一个小小的知识点。
Stream 的api提供了不少方法,诸如 filter、sotred、limit、map、collect等。
其中 filter、sotred、limit、 map 它们的返回结果仍然是一个stream 流, 这些操作,我们称之为中间操作。并且它们之间的连接可以形成一个流水线任务 。
而 collect 则是一个终端操作,它会 触发并执行流水线任务,最终关闭它 。
中间操作
就是上面说的 filter、map等等,但是需要注意的是,如果流水线上没有一个终端操作,那么你写的filter、map什么的,并不会执行任何处理。
通过一个简单的案例,来看一看stream流中的lambda的函数的执行流程。
static List<Student> students = new ArrayList<>();
static {
students.add(new Student("学生A", "大学1", 18, 98.0));
students.add(new Student("学生A", "大学1", 18, 91.0));
students.add(new Student("学生A", "大学1", 18, 90.0));
students.add(new Student("学生A", "大学1", 18, 76.0));
students.add(new Student("学生B", "大学1", 18, 91.0));
students.add(new Student("学生C", "大学1", 19, 65.0));
students.add(new Student("学生D", "大学2", 20, 80.0));
students.add(new Student("学生E", "大学2", 21, 78.0));
students.add(new Student("学生F", "大学2", 20, 67.0));
students.add(new Student("学生G", "大学3", 22, 87.0));
students.add(new Student("学生H", "大学3", 23, 79.0));
students.add(new Student("学生I", "大学3", 19, 92.0));
students.add(new Student("学生J", "大学4", 20, 84.0));
}
复制代码
public static void main(String[] args) {
List<String> collect = students.stream().filter(student -> {
System.out.println("filter==>" + student.getName() + ":" + student.getAge());
return student.getAge() > 20;
}).map(student -> {
System.out.println("map==>" + student.getName() + ":" + student.getAge());
return student.getName();
}).collect(Collectors.toList());
}
复制代码 输出:
filter==>学生A:18
map==>学生A:18
filter==>学生A:18
map==>学生A:18
filter==>学生A:18
map==>学生A:18
filter==>学生A:18
map==>学生A:18
filter==>学生B:18
map==>学生B:18
filter==>学生C:19
map==>学生C:19
filter==>学生D:20
filter==>学生E:21
filter==>学生F:20
filter==>学生G:22
filter==>学生H:23
filter==>学生I:19
map==>学生I:19
filter==>学生J:20
复制代码 也许到这里还看的不明显,我们再加上一个 limit(3),来看一下这次会如何输出
List<String> collect = students.stream().filter(student -> {
System.out.println("filter==>" + student.getName() + ":" + student.getAge());
return student.getAge() < 20;
}).map(student -> {
System.out.println("map==>" + student.getName() + ":" + student.getAge());
return student.getName();
}).limit(3).collect(Collectors.toList());
System.out.println(collect);
复制代码 输出结果:
filter==>学生A:18
map==>学生A:18
filter==>学生A:18
map==>学生A:18
filter==>学生A:18
map==>学生A:18
[学生A, 学生A, 学生A]
复制代码 1、 实际上这里利用到的 limit(n) 就是俗称的短路技巧,像我们刚学 &&、| | 语法时一样,如果&&条件为false,则会短路,不执行&& 之后的表达式,这里的 limit 你可以看作是 || 的表达 。
Stream 流在内部迭代中主动帮我们进行了优化。
2、 另外看似 filter 和 map 是两个独立的函数,但实际上他们都是在一次遍历中所进行的 。这一点从输出中也可看出。
终端操作
终端操作,就是 触发并执行流水线任务,最终关闭流的操作 。
像之前写的 collect(Collectors.toList()) 和 forEach(System.out::println) 都是终端操作。
终端操作其结果返回的都是流的值,collect返回各种各样的集合啦,
forEach 返回的就是 void 值。
中间操作
操 作 | 类型 | 结果 | 操作参数 |
|
filter | 中间 | Stream | Predicate | T -> boolean |
map | 中间 | Stream | Stream Function | T -> R |
limit | 中间 | Stream |
|
|
sorted | 中间 | Stream | Comparator | (T, T) -> int |
distinct | 中间 | Stream |
|
|
终端操作
操 作 | 类 型 | 目 的 |
forEach | 终端 | 消费流中的每个元素并对其应用 Lambda。这一操作返回 void |
count | 终端 | 返回流中元素的个数。这一操作返回 long |
collect | 终端 | 把流归约成一个集合,比如 List、Map 甚至是 Integer 。 |


