作者:孤独烟
转载:
话说前几天有一次,某大厂的二面。然后呢,烟哥那天刚好有事,所以去不了。于是就约了一场视频面试了!
全局Session
当时的情形是这样的,先介绍一下自己的项目。然后介绍完项目背景以后,因为有一个登陆模块。于是乎有了如下问题
这个问题还是很容易的。因为一个应用通常有多台服务器,在登陆成功后,Session只会在其中某一台存储。需要想办法让多台服务器都识别到这个Session,因此才有了这个全局Session的概念。我们用的是 后端统一存储 的策略,有专门的用户管理系统,上面存储着用户信息以及Session状态。
烟哥注:目前业内在解决全局Sesssion上无外乎四种方法
- (1)服务端自己进行同步,例如早期的项目,大概是07年那会的(我司老古董项目啊),那会Tomcat的集群能力不行。用的是 Weblogic 服务器,使用的就是Weblogic的Session复制功能。
- (2)客户端存储法,将session存储到浏览器cookie中,每次http请求都带session。这里摸着良心坦白说,该方案从没用过,安全性太差。
- (3)反向代理 hash 一致性,不需要修改应用代码。修改nginx的配置,保证同一个ip的请求落在同一个web-server上即可。
- (4)后端统一存储,后端统一找一个 中间件 将Session存起来即可,这个中间件是数据库或者 缓存 。
面试官:“那你知道这个平台里Session怎么管理的么?”
必须不知道啊!对我们来说该平台只是一个黑盒,会调接口即可。
于是乎,一个让我头疼的问题出现了!
面试官:“如果让你设计这样一个平台,管理这些Session,你会怎么设计?”
用 redis 来存储Session,用sessionId作为key,用session当value进行存储。
OK,这时我头脑浮现的架构是这样的
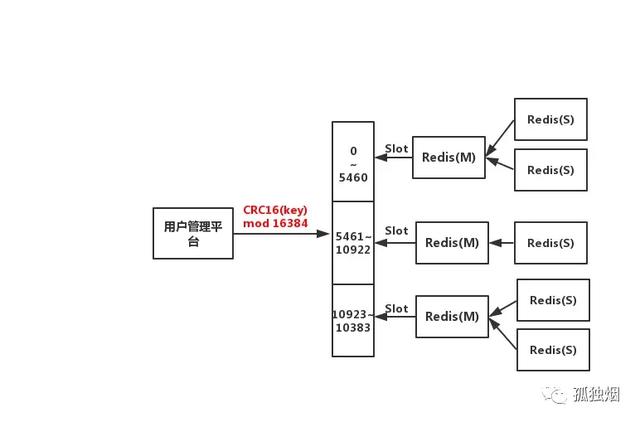
面试官:”如果redis挂了呢?”
咦,这个时候,我突然懵了。面试官到底想问我什么?难道挂了,不是redis从服务器顶上么?这个问题莫非有什么玄机?
然后我是这样答的。
一般情况,主redis挂了,由从redis顶上。如果redis某个slot的主从节点全挂了,
那么我们在rediscluster中有一个配置叫
cluster-require-full-coverage
当cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用。但是该槽的相关命令不可用。
当cluster-require-full-coverage为yes时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群不可用。
该值默认值为yes,也就是集群处于不可用的状态。
这个时候,可能出现了网络中断!
面试官:”你的意思是,redis挂了,整个集群数据就不可用了?”
我回答嗯嗯,是的!
这个时候,面试官
面试官:”你不知道 一致性哈希 算法么?回去了解一下!”
然后我突然懵了。原来是我想太多,他这样问完,我才get到他问的点。
烟哥注:所以我才说这个面试我有点失败,和面试官不在一个频道上。如果是现场面,可以现场画图,则不会出现这种问题!
面试官想到的架构应该是这样的

上图中,由于有4台服务器(排除从库),因此公式为hash(sessionId) % 4 = 2 ,可知定位到了第2号服务器。
但是呢,普通的如果4台 缓存服务器 已经不能满足我们的缓存需求,那么我们应该怎么做呢?很简单,多增加几台缓存服务器不就行了!
假设:我们增加了一台缓存服务器,那么缓存服务器的数量就由4台变成了5台。那么原本hash(sessionId) % 4 = 2 的公式就变成了hash(sessionId) % 5 = ?, 可想而知这个结果肯定不是2的,这种情况带来的结果就是当服务器数量变动时,所有缓存的位置都要发生改变!
于是乎,他才想引我去答一致性哈希算法!总之,该死的破网络!导致两边不在一个频道上!
一致性哈希
既然都提到了一致性哈希算法了,就当复习一下吧~~
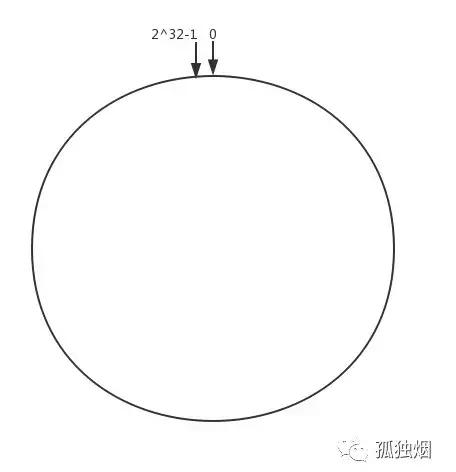
一致性哈希算法的精髓只有一个:对2^32次方取模。
我们将二的三十二次方想象成一个圆,这个圆上的数字就是即0~(2^32)-1。
如下图所示
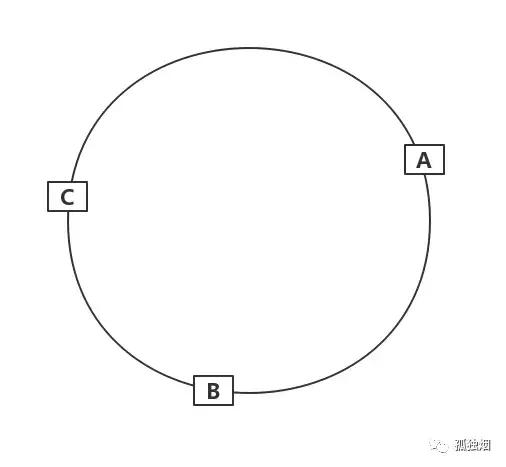
这时候有三台缓存服务器A、B、C。
我们
hash(服务器A的IP地址) % 2^32
插播一下,写到这里,这里我又想起一道题了!
有哪些常见的hash算法啊?
OK,先继续我们的话题。经过上面的运算,我们算出的结果一定是一个0到2^32-1之间的一个整数,我们就用算出的这个整数,代表服务器A,既然这个整数肯定处于0到2^32-1之间,那么,上图中的hash环上必定有一个点与这个整数对应,我们使用这个整数代表服务器A,那么,服务器A就可以映射到这个环上。
同理进行
hash(服务器B的IP地址) % 2^32
hash(服务器C的IP地址) % 2^32
于是,得到了下面这一张图
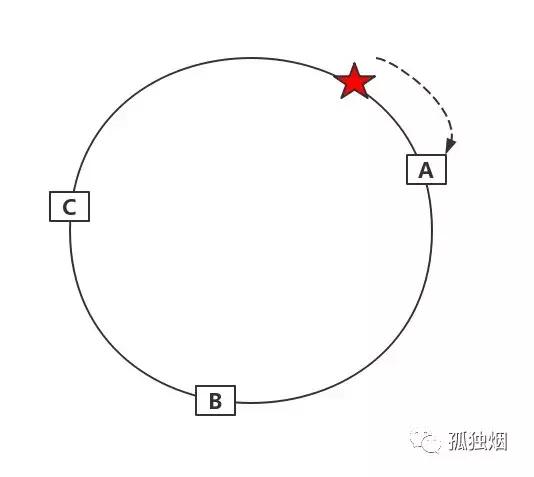
那么,我们要用服务器存储session,那么我们用sessionId做key,进行如下运算
hash(sessionId) % 2^32
得到的一个环上的值。那我们怎么知道session被存到哪个服务器上呢,OK,顺时针方向找到的第一个服务器就是。如下图所示
假设,我们现在有四个session,分别进行映射运算后得到如下的环
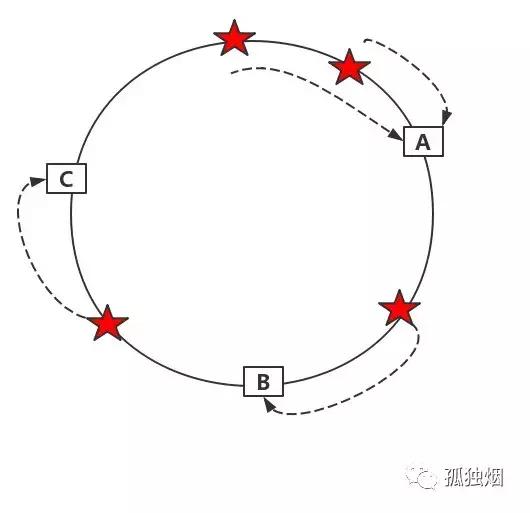
这么做的好处?
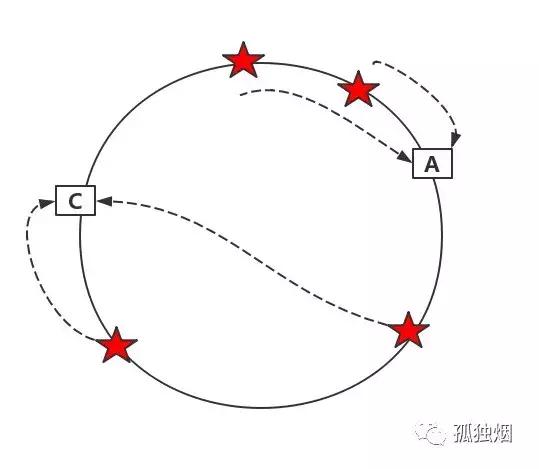
使用一致性算法后,当服务器B移除的时候,服务器B上的数据会顺时针移动到服务器C上去。从而避免了当服务器数量发生改变当时候,所有的session都失效。
如下所示
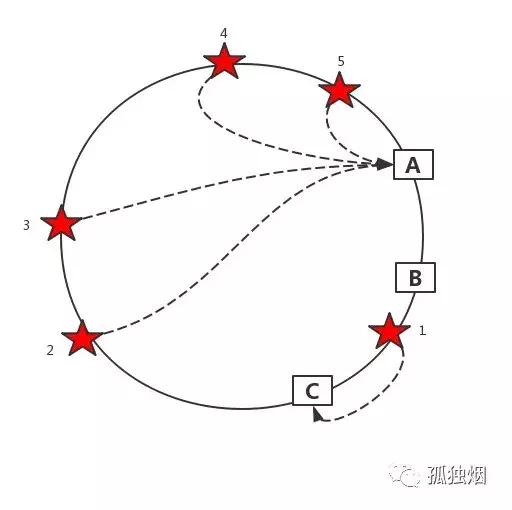
虚拟槽的应用?
真实世界中,服务器可能映射的并不均匀。这就导致了数据可能是下面这样的,大量的数据在A服务器上,导致数据不均匀
为了解决这个问题,我们给A、B、C三台服务器引入虚拟节点。如下图所示(图中黄色节点为虚拟节点)
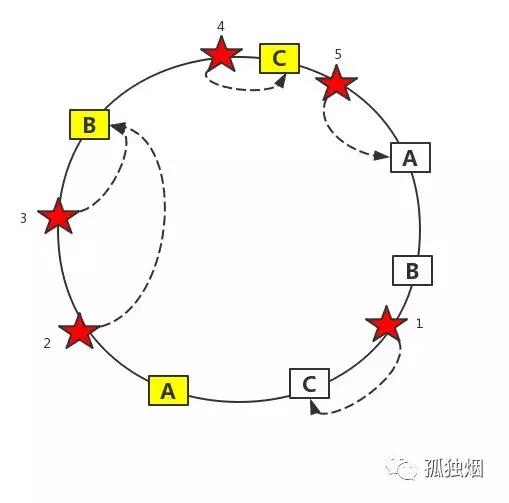
如图所示,2号session和3号session映射到了虚拟B节点,就会存储到真实的B节点上。通过引入虚拟节点的方式,实现数据的均匀分配!
最后,本文内容全当复习一次一致性哈希算法。希望大家有所收获。


