前言
Java 在 JDK 1.4 引入了 ByteBuffer 等 NIO 相关的类,使得 Java 程序员可以抛弃基于 Stream ,从而使用基于 Block 的方式读写文件.
另外,JDK 还引入了 IO 性能优化之王—— 零拷贝 sendFile 和 mmap 。
但他们的性能究竟怎么样? 和 RandomAccessFile 比起来,快多少? 什么情况下快?到底是 FileChannel 快还是 MappedByteBuffer 快……
天啊,问题太多了。。。让我们慢慢分析。
看看善于利用IO零拷贝的MQ们
我们知道,Java世界有很多MQ:ActiveMQ,kafka,RocketMQ,QMQ(去哪儿MQ),他们是使用NIO零拷贝的大户。
然而,他们的性能却大相同,抛开其他的因素,例如网络传输方式,数据结构设计,文件存储方式,我们仅仅讨论 Broker 端对文件的读写,看看他们有什么不同。
下图是楼主查看源码总结的各个 MQ 使用的文件读写方式。
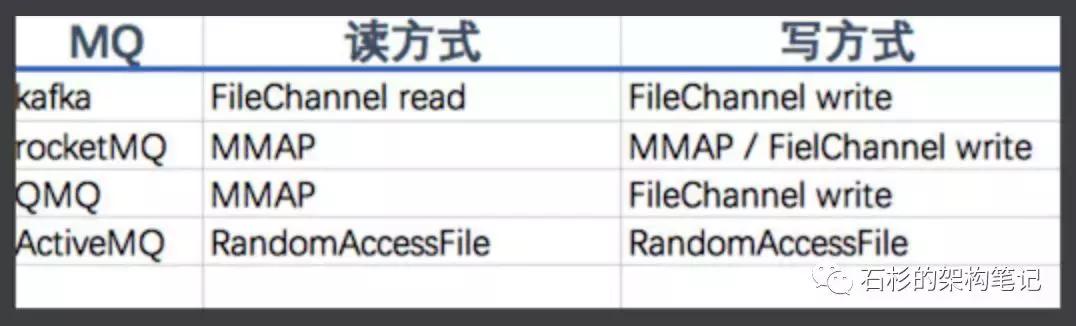
- Kafka :record 的读写都是基于 FileChannel。index 读写基于 MMAP。
- RocketMQ :读盘基于 MMAP,写盘默认使用 MMAP,可通过修改配置,配置成 FileChannel,原因是作者想避免 PageCache 的锁竞争,通过两层架构实现读写分离。
- QMQ : 去哪儿 MQ,读盘使用 MMAP,写盘使用 FileChannel。
- ActiveMQ 5.15 : 读写全部都是基于 RandomAccessFile,这也是我们抛弃 ActiveMQ 的原因。
那么,到底是 MMAP 强,还是 FileChannel 强?
MMAP 众所周知,基于 OS 的 mmap 的 内存映射 技术,通过 MMU 映射文件,使随机读写文件和读写内存相似的速度。
那 FileChannel 呢?是零拷贝吗?很遗憾,不是。FileChannel 快,只是因为他是基于 block 的。
接下来,benchmark everything —— 徐妈.
Benchmark ?
如何 Benchmark? Benchmark 哪些?
既然是读写文件,自然就要看读写性能,这是最基本的。
但,注意,通常MQ会使用定时刷盘,防止数据丢失,MMAP 和 FileChannel 都有 force 方法,用于将 pageCache 的数据刷到硬盘上。
force 会影响性能吗? 答案是会。影响到什么程度呢? 不知道。
每次写入的数据大小会影响性能吗,毫无疑问会,但规则是什么呢?FileOutputStream 真的一无是处吗?答案是不一定。
一直以来,文件调优都是艺术,因为影响性能的因素太多,首先, SSD 的出现,已经让传统基于 B+ tree 的树形结构产生了自我疑问。
第二,每个文件系统的性能不同,Linux ext3 和 ext4 性能天壤之别(删除文件的性能差距在 20 倍左右)。而 Max OS 的 HFS+ 系统被 Linus 称之为“有史以来最垃圾的文件系统”.
幸运的是,苹果终于在 2017 年推送了 macOS High Sierra 和 iOS 10.3 系统,这个两个系统都抛弃了 HFS+,换成了性能更高的 APFS。
每个文件系统又可以设置不同的调度算法,另外,还有 虚拟内存 缺页中断带来的性能毛刺…….
(tips:良心的 RocketMQ 提供了 Linux IO 调优的脚本,这点做的不错 :)
跑题了。
楼主写了一个小项目,用于测试 Java MappedByteBuffer & FileChannel & RandomAccessFile & FileXXXputStream 的读写性能。大家也可以在自己的机器上跑跑看。
测试环境
CPU:intel i7 4核8 线程 4.2GHz
内存:40GB DDR4
磁盘:SSD 读写 2GB/s 左右
JDK1.8
OS:Mac OS 10.13.6
虚拟内存: 未关闭,大小 9GB
测试注意点:
- 为了防止 PageCache 缓存的影响,每次都生成一个新的文件进行读取。
- 为了测试不同数据包对性能的影响,需要使用不同大小的数据包进行多次测试。
- force 对性能影响很大,应该单独测试。
- 使用 1GB 文件进行测试(小文件没有参考意义,大文件 mmap 无法映射)
纯粹读测试
1GB 文件:
测试 MappedByteBuffer & FileChannel & RandomAccessFile & FileInputStream .
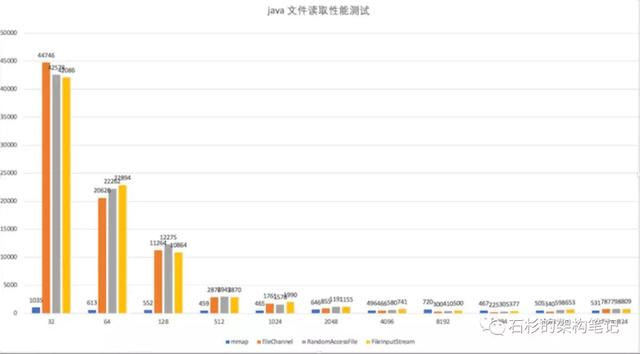
从这张图里,我们看到,mmap 性能完胜,特别是在小数据量的情况下。其他的流,只有在4kb 的情况下,才开始反杀 mmap。
因此,读 4kb 以下的数据,请使用 mmap。
再放大看看 mmap 和 FileChannel 的比较:

根据上图,我们看到,在写入数据包大于 4kb 以上的情况下,FileChannel 等一众非零拷贝,基本完胜 mmap,除了那个一次读 1G 文件的 BT 测试。
因此,如果你的数据包大于 4kb,请使用 FileChannel 。
纯粹写测试
1GB 文件:
测试 MappedByteBuffer & FileChannel & RandomAccessFile & FileInputStream.
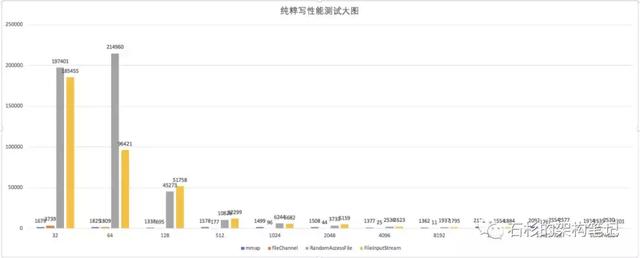
从上图,我们可以看出,mmap 性能还是一样的稳定。FileChannel 也不差,但是在 32 字节数据量的情况下,还差点意思。
再看缩略图:
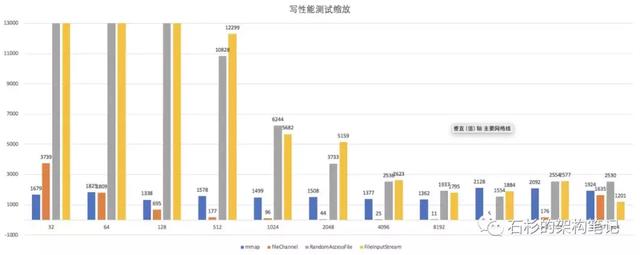
我们看到,64字节 是 FileChannel 和 mmap 性能的分水岭,从 64字节开始,FileChannel 一路反杀,直到 BT 1GB 文件稍稍输了一丢丢。
因此,我们建议: 如果你的数据包大小在 64 字节以上,请使用 FileChannel 写入。
异步 force 测试
我们知道,RocketMQ 使用异步刷盘,那么异步 force 对性能有没有影响呢?benchmark everything。我们使用异步线程,每 16kb 刷盘一次,看看性能如何。
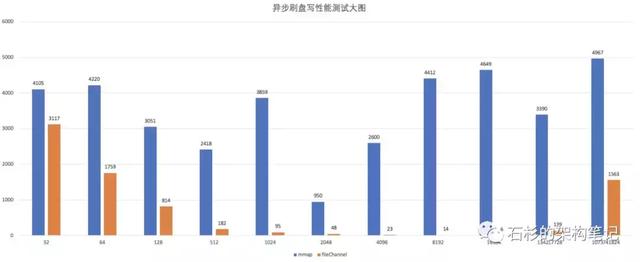
mmap 一直落后,且性能很差,除了在2048 字节那里有一点点抖动,基本维持在4000左右,而没有 force 的情况下,则在 1500 左右。而 FileChannel 则完全不受 force 的影响。
在我的测试中,1GB 的文件,一次 force 需要 800 毫秒左右。buffer 越大,时间越多,反之则越小。
说个题外话,Kafka 一直不建议使用 force,大概也有这个原因。当然,Kafka 还有自己的多副本策略保证数据安全。
这里,我们得出结论,如果你需要经常执行 force,即使是异步的,也请一定不要使用 mmap,请使用 FileChannel。
总结
基于以上测试,我们得出一张图表:

假设,我们的系统的数据包在 1024 – 2048 左右,我们应该使用什么策略?
答:读使用 mmap,仅仅写使用 FileChannel。
再回过头看看 MQ 的实现者们,似乎只有 QMQ是这么做的。
当然,RocketMQ 也提供了 FileChannel 的写选项。但默认 mmap 写加异步刷盘,应该是 broker busy 的元凶吧。
而 Kafka,因为默认不 force,也是使用 FileChannel 进行写入的。
为什么使用 FileChannel 读呢?大概是因为消息的大小在 4kb 以上吧。这样一揣测,这些 MQ 的设计似乎都非常合理。
最后,能不用 force 就别用 force。如果要用 force ,就请使用 FileChannel。


