在软件系统的开发中经常会遇到 Excel 导入导出的场景,对于Java开发者经常会使用 Apache POI 这个库来处理Excel,这是一个非常流行的 Java API for Microsoft Documents。
XSSFWorkbook读取Excel
最常用的读取代码如下:
workbook workbook = new XSSFWorkbook([Input Stream]);
IntStream.range(0, workbook.getNumberOfSheets()).forEarch(
sheetIndex -> {
Sheet sheet = workbook.getSheetAt(sheetIndex);
// 处理数据
}
) 在导入数据量较小的情况下,通常都能正常工作,但是当导入的Excel数据量非常大而运行环境内存不足时,会遇到内存溢出的错误。我构造了含有8000行数据的Excel用来测试,并设置了 JVM 参数“-Xms32M -Xmx32M”,产生了如下错误:
Exception in thread "main"
java.lang.OutOfMemoryError: Java heap space 这个文件仅仅占用了279K的磁盘大小,有趣的是 POI 在处理Excel文件时所使用的内存却远大于279K, 原因是 xlsx 基本上是一堆压缩的 XML 文件,而且 XML 被很好地压缩(大约 10 倍)。将这个 XML 放在未压缩的内存中已经将内存消耗增加了十倍,再算上添加数据结构的所有开销,内存占用将更大。
XSSFReader读取Excel
为了解决内存占用的问题,对于XSSF可以获取底层XML数据并自行处理。虽然需要学习一些xlsx文件的结构,但可以以相对较小的占用内存读取大数据量的XLSX文件。
需要注意的是对XML的解析也分为 DOM 解析和SAX解析,他们的区别在于DOM使用简单,但是会占用大量内存,而 SAX 解析是以流的方式读取XML文件,并通过事件触发方式通知代码。对于XLSX文件格式,没有填写内容的单元格在XML中是不存在的,也就是说不是每个行都拥有同样数量的单元格Cell元素,你需要通过代码解决这些问题。
解压后的Excel文件
要查看Excel中的XML信息,将Excel后缀名改为“.zip”,打开“xl > worksheets” ,查看对应Sheet的标签节点信息。
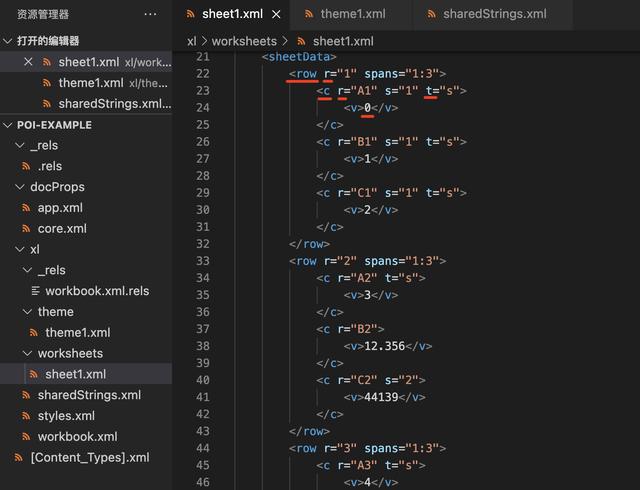
sheet.xml
从如上截图可以看到,sheet标签中包含了row(行标签)、c(Cell标签)、r(Cell的Excel编号属性)、t(Cell的Type属性)等节点,要了解XML的结构可以访问 Microsoft 官方文档,你可以在本文末处找到链接地址。
接下来,我们创建一个XSSFReader实例,使用SAX解析读取数据,示例代码如下:
public class XSSFReaderExample {
public static void main(String[] args) {
OPCPackage pkg = OPCPackage.open(filePath);
XSSFReader r = new XSSFReader(pkg);
SharedStringsTable sst = r.getSharedStringsTable();
XMLReader parser = XMLHelper.newXMLReader();
ContentHandler handler = new SheetHandler(sst);
parser.setContentHandler(handler);
// 从xml中获取Id,一般是rId# or rSheet#
InputStream sheet = r.getSheet("rId1");
InputSource sheetSource = new InputSource(sheet);
parser.parse(sheetSource);
sheet.close();
}
private static class SheetHandler extends DefaultHandler {
private final SharedStringsTable sst;
private String lastContents;
private boolean nextIsString;
// Row数据,使用TreeMap保持顺序
private Map<String, String> rowData = new TreeMap<>();
private int cellSeq = 0; // Cell序列,处理Cell为空的情况
private int rowSeq = 0; // Row序列
private OrderSheetHandler(SharedStringsTable sst) {
this.sst = sst;
}
@ Override
public void startElement(String uri,
String localName, String qName, Attributes attributes) {
if (qName.equals("row")) {
cellSeq = 0;
rowSeq = Integer.parseInt(attributes.getValue("r"));
}
// c => cell
if (qName.equals("c")) {
String cellSeqStr = CellReference
.convertNumToColString(cellSeq++) + rowSeq;
String readCellStr = attributes.getValue("r");
while (!cellSeqStr.equals(readCellStr)) {
rowData.put(cellSeqStr, "");
cellSeqStr = CellReference.convertNumToColString(cellSeq++)
+ rowSeq;
}
String cellType = attributes.getValue("t");
if (cellType != null && cellType.equals("s")) {
nextIsString = true;
} else {
nextIsString = false;
}
}
// Clear contents cache
lastContents = "";
}
@Override
public void endElement(String uri, String localName, String qName) {
if (qName.equals("row")) {
// 处理行数据rowData
rowData.clear();
}
if (nextIsString) {
// sheet xml中存储的是文字索引
int idx = Integer.parseInt(lastContents);
lastContents = sst.getItemAt(idx).getString();
nextIsString = false;
}
// v => 单元格的内容
if (qName.equals("v")) {
rowData.put(
CellReference.convertNumToColString(cellSeq - 1) + rowSeq,
lastContents);
}
}
// 接收元素内字符数据
@Override
public void characters(char[] ch, int start, int length) {
lastContents += new String(ch, start, length);
}
}
} 采用XSSFWorkbook案例相同的内存配置,使用上述代码读取大数据量Excel,能轻松处理,不会出现内存溢出的现象。
XSSFWorkbook写入Excel
XSSF是POI提供的常用Excel写入工具,示例代码如下:
XSSFWorkbook wb = new XSSFWorkbook();
Sheet sh = wb.createSheet("order");
AtomicInteger rownum = new AtomicInteger(0);
Row headerRow = sh.createRow(rownum.getAndIncrement());
headerRow.createCell(0).setCellValue("Title-1");
headerRow.createCell(1).setCellValue("Title-2");
headerRow.createCell(2).setCellValue("Title-3");
headerRow.createCell(3).setCellValue("Title-4");
IntStream.rangeClosed(rownum.get(), 8000)
. forEach (
idx -> {
Row row = sh.createRow(rownum.getAndIncrement());
row.createCell(0).setCellValue("value-column-1" + idx);
row.createCell(1).setCellValue("value-column-2" + idx);
row.createCell(2).setCellValue("value-column-3" + idx);
row.createCell(3).setCellValue("value-column-4" + idx);
});
wb.write(new FileOutputStream(filePath)); 设置JVM启动参数“-Xms16M -Xmx16M”运行上述代码,遇到如下错误:
Exception in thread "main"
java.lang.OutOfMemoryError: Java heap space
at org.apache.xmlbeans.impl.store.Saver$TextSaver.resize(Saver.java:1701)
...... 原因依然是由于XSSF在内存中组织数据,需要消耗大量的内存。这类错误笔者曾在给某金融公司做顾问时听到他们的抱怨,他们的生产环境在导出几次大量数据的Excel之后,内存占用开始上升,直至遇到内存溢出的错误。
SXSSFWorkbook写入Excel
好消息是Apache POI 引入了 SXSSF, 用于在电子表格中流式传输非常大量的数据,具有非常好的性能和低内存使用率。示例代码如下:
// .... 与上面的代码一致
SXSSFWorkbook wb = new SXSSFWorkbook(SXSSFWorkbook.DEFAULT_WINDOW_SIZE);
Sheet sh = wb.createSheet("order");
// .... 与上面的代码一致 与上面的代码的区别在于使用SXSSFWorkbook来写入,它的构造函数的参数是允许在内存中的数据行数,当达到行数后row的索引值会被刷新,临时数据会被写入磁盘,通过以下代码可以设置POI使用的临时目录:
TempFile.setTempFileCreationStrategy(
new DefaultTempFileCreationStrategy(new File(poiTempDir))); 此时运行代码可以观察到POI处理数据时所生成的临时文件,如下图:

POI Temp File
这两种处理Excel写入的方式内存占用差异见下图,前部分是SXSSF方式的内存占用,非常稳定,后部分是XSSF方式,内存占用非常大。
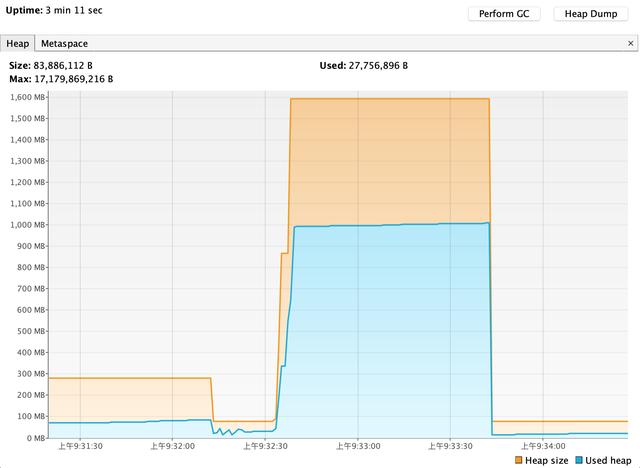
XSSF与SXSSF内存占用对比
此外大数据量的写入不都是像示例代码中这样通过逻辑写入数据,通常是将数据库中的数据读取出来组织后写入Excel,要注意设置好 JDBC featchSize参数,流式读取以防止内存占用过大造成OOM。
本文总结
- POI读取的2种方式:XSSF与SAX解析,读取大数据量用SAX解析防止OOM;
- POI写入的2种方式:XSSF与SXSSF,写入大数据量用SXSSF方式OOM;
- JDBC读取大数据量设置featchSize参数,流失读取防止大量内存占用;
参考资料
另:示例代码POI版本:4.1.2


