前言
金九银十就要来了,不知道程序员们都准备好了吗?
今天就给大家分享一波一位小伙伴面试大厂的经历、知识点和面试题分享,主要内容包括:JVM、 Java 集合、JAVA多线程并发、JAVA基础、Spring原理、微服务、Netty与RPC、网络、日志、 Zookeeper、 Kafka、 RabbitMQ、 Hbase、 MongoDB、 Cassandra、设计模式、负载均衡、数据库一致性算法、 JAVA算法、数据结构、加密算法、分布式缓存、Hadoop、Spark、Storm、YARN、机器学习、云计算。
Zookeeper+微服务+消息中间件+高并发架构设计+幻影读+分段锁+Spring Cloud+秒杀+事务+集群+秒杀架构等等。
希望能够成就大家的大厂梦!!!
小伙伴基本情况介绍
北京985渣硕一枚,是真的渣,舍友商汤、旷世,出国留学,学校中各类大佬一坨,在夹缝中求生,混口饭吃。
主攻方向 :无。领导搞行政的,天天端茶倒水取快递,外挂写不尽的基金本子,论文全靠个人参悟+上天怜悯。
说点正事吧,关于工作路线,我最终选择的是大数据研发方向,主要原因是研一上了点分布式的课,拿出来吹一吹,还能唬的住人。个人感觉算法也能做,研发、算法半斤八两吧
学校这边的话,有优秀高校背书自然要好,没有的话,就没有吧,大牛们不差这点,渣渣们大家也强不到哪去,不必强求。
项目, 在读书过程中,一定要了解个项目,否则面试官真没啥问题你的,尬场基本就凉凉了。这项目不必真的是你的,当找工作时,所有前辈、朋友的项目全都是你的,包装下,你说是你的就是你的,没人去查你底细的,关键了解要深,这样和别人说底气才足。我有幸给一个数据流项目做了些边角任务,但在简历上,我成为了该项目的负责人…自己体会包装的艺术…
简历,我以前认为大家“没见过猪跑还没吃过猪肉吗”,网上那么多强调简历重要性的,直到我看见我小师弟的简历,发现真的有人没吃过猪肉(我学硕他专硕,一起找工作,他有百度大厂背书,可这工作找的唉…)。最简单的修改方法,让你附近的同学看看,第一眼感觉可以吗,可以就ok,不可以就gg,照着人家的改改。
现在前头,准备要早,投的也要早基本7月中旬就陆陆续续开始有提前批了,错过就没了。>…< 。
第一家(Zookeeper+微服务+消息中间件+高并发架构设计)
一面
- JVM数据存储模型,新生代、年老代的构造?
- java GC算法,什么时候会触发minor gc,什么时候会触发full gc?
- GC 可达性分析中哪些算是GC ROOT?
- 你熟悉的JVM调优参数,使用过哪些调优工具?
- Java 有什么锁类型?
- 描述下 线程池 的处理流程?
- 类加载机制,一个类加载到虚拟机中一共有几个步骤,这些步骤的顺序哪些是固定的,哪些是不固定的,为什么不固定?
- HashMap 是线程不安全的, ConcurrentHashMap 是 线程安全 的,怎么实现的线程安全?
- volatile关键字解决了什么问题,实现原理是什么?
- 并发容器有哪些,并发容器和同步容器的区别
二面
- 在工作中, SQL 语句的优化和注意的事项
- 哪些库或者框架用到NIO
- Spring 都有哪几种注入方式,什么情况下用哪种,ioc实现原理
- 如何定位一个慢查询,一个服务有多条SQL你怎么快速定位
- 聚集索引和非聚集索引知道吗?什么情况用聚集索引什么情况用非聚集索引
- NoSQL 引擎用的什么存储结构,关系型数据库和NoSQL各自的优劣点是什么,如何技术选型?
- 微服务架构下,如果有一个订单系统,一个库存系统,怎么保证事务?
- 分布式一致性协议raft,paxos 了解吗
- Zookeeper中的ZAB协议,选主算法
三面
- 自我介绍
- 参与的并发项目,从设计到部署,按照流程讲一遍。
- 项目相关你用过 Redis ,用在什么场景,怎么使用的?
- mysql同步机制原理,有哪几种同步方法
- 数据库主从同步如何实现,事务如何实现
- 谈谈你对SOA和微服务的理解,以及分布式架构从应用层面涉及到的调整和挑战。
- 阿里系中间件metaQ及原理与现有的kafka有什么异同
- 在阿里有了解过什么中间件吗?实现原理?与其他开源消息队列有什么特点?
- 为什么选择换公司?
- 三年到五年的职业规划?
- 你有想问我的?
第二家(幻影读+分段锁+Spring Cloud+秒杀)
一面
- 简短自我介绍
- 事务的ACID,其中把事务的隔离性详细解释一遍
- 脏读、幻影读、不可重复读
- 红黑树 、二叉树的算法
- 平常用到哪些集合类?ArrayList和LinkedList区别?HashMap内部数据结构?ConcurrentHashMap分段锁?
- jdk1.8中,对hashMap和concurrentHashMap做了哪些优化
- 如何解决hash冲突的,以及如果冲突了,怎么在hash表中找到目标值
- synchronized 和 ReentranLock的区别?
- ThreadLocal?应用场景?
- Java GC机制?GC Roots有哪些?
- MySQL行锁是否会有死锁的情况?
二面
- 乐观锁和悲观锁了解吗?JDK中涉及到乐观锁和悲观锁的内容?
- Nginx负载均衡策略?
- Nginx和其他负载均衡框架对比过吗?
- Redis是单线程?
- Redis高并发快的原因?
- 如何利用Redis处理热点数据
- 谈谈Redis哨兵、复制、集群
- 工作中技术优化过哪些?JVM、MySQL、代码等都谈谈
三面
- Spring Cloud用到什么东西?如何实现负载均衡?服务挂了注册中心怎么判断?
- 网络编程nio和netty相关,netty的线程模型,零拷贝实现
- 分布式锁的实现你知道的有哪些?具体详细谈一种实现方式
- 高并发的应用场景,技术需要涉及到哪些?怎样来架构设计?
- 接着高并发的问题,谈到了秒杀等的技术应用:kafka、redis、mycat等
- 最后谈谈你参与过的项目,技术含量比较高的,相关的架构设计以及你负责哪些核心编码
第三家
一面(50分钟)
- hashmap,怎么扩容,怎么处理数据冲突?怎么高效率的实现数据迁移?
- Linux的共享内存如何实现,大概说了一下。
- socket网络编程,说一下TCP的三次握手和四次挥手
- 同步IO和异步IO的区别?
- Java GC机制?GC Roots有哪些?
- 红黑树讲一下,五个特性,插入删除操作,时间复杂度?
- 快排的时间复杂度,最坏情况呢,最好情况呢,堆排序的时间复杂度呢,建堆的复杂度是多少
二面(40分钟)
- 自我介绍,主要讲讲做了什么和擅长什么
- 设计模式了解哪些?
- AtomicInteger怎么实现原子修改的?
- ConcurrentHashMap 在Java7和Java8中的区别?为什么Java8并发效率更好?什么情况下用- —
- HashMap,什么情况用ConcurrentHashMap?
- redis数据结构?
- redis数据淘汰机制?
三面(约1个小时)
- mysql实现事务的原理(MVCC)
- MySQL数据主从同步是如何实现的?
- MySQL 索引 的实现,innodb的索引,b+树索引是怎么实现的,为什么用b+树做索引节点,一个节点存了多少数据,怎么规定大小,与磁盘页对应。
- 如果Redis有1亿个key,使用keys命令是否会影响线上服务?
- Redis的持久化方式,aod和rdb,具体怎么实现,追加日志和备份文件,底层实现原理的话知道么?
- 遇到最大困难是什么?怎么克服?
- 未来的规划是什么?
- 你想问我什么?
第四家 (事务+集群+秒杀架构)
一面
- 常见集合类的区别和适用场景
- 并发容器了解哪些?
- 如何判断链表是否有环
- concurrentHashMap如何实现
- 集群服务器 如何application 共享
- JAVA网络编程中:BIO、NIO、AIO的区别和联系
- jvm内存模型jmm 知道的全讲讲
- JAVA的垃圾回收,标记算法和复制算法的区别,用在什么场合?
- http和https的区别,http1.x和http2.0的区别,SSL和TSL之间的区别
- GC、G1和ZGC的区别
- B+树和B树的区别,和红黑树的区别
- 内存泄漏与内存溢出的区别
- session的生命周期是多久
- 关于Mina框架了解多少?(因为我在项目里用到了Mina,所以提到了这个部分)
二面
- java cas原理
- JAVA线程池有哪些参数,如果自己设计一个线程池要考虑哪些问题?
- Java的 Lock 的底层实现?
- mysql数据库默认存储引擎,有什么优点
- MySQL的事务隔离级别,分别解决什么问题。
- 四个表 记录成绩,每个大约十万条记录,如何找到成绩最好的同学
- 常见的负载均衡算法有哪些
- 如果Redis有1亿个key,使用keys命令是否会影响线上服务
- Redis的持久化方式,aod和rdb,具体怎么实现,追加日志和备份文件,底层实现原理的话知道么
三面
- 请画一个完整大型网站的分布式服务器集群部署图
- 多个RPC请求进来,服务器怎么处理并发呢
- 讲一下Redis的哨兵机制
- 数据库分库分表一般数据量多大才需要?
- 如何保证数据库与redis缓存一致的
- 项目中消息队列怎么用的?使用哪些具体业务场景?
- JVM相关的分析工具有使用过哪些?具体的性能调优步骤吗?
- MySQL的慢sql优化一般如何来做?除此外还有什么方法优化?
- 线上的服务器监控指标,你认为哪些指标是最需要关注的?为什么?
- 如何做压测,抗压手段
- 秒杀模块怎么设计的
HR面
- 自我介绍
- 你怎么评价你之前的3轮面试
- 你怎么看待你自己,你最大的核心竞争力是什么
- 未来自己的职业规划
- 对阿里技术氛围有什么样的理解,用过哪些阿里的开源库
- 期望的薪资是多少
- 最后,你有什么想了解的
题外话
写给需要的,不想死磕互联网的人:ヽ(。◕‿◕。)ノ
- 读博真的不错,大家可以考虑下,真的是条出路,尤其你比较年轻的话
- 户口互联网不可兼得,最近在考虑户口唉
- 国企、银行、公务员都可以考虑啊,感觉这类工作有空陪家人
知识点
最后,送上我面试过程中整理出的Java核心知识点(可能有误-_-||),供大家查漏补全,希望大家都能找到个好offer~~~~~~~~~~
Java
线程并发
这就是一天坑,基本问不完,难度也是拉满的那种…
Q:进程和线程的区别?
- 进程是资源分配的基本单位,线程是程序执行的最小单位
- 进程有独立的地址空间,线程依托于进程存在,线程切换的开销小
- 多进程组成的服务更稳定,一个进程挂了不会对另一个进程造成影响,相反,一个线程挂了,依托该进程的所有线程都会崩溃
Q:进程间通信方式?
- 管道
- 信号量
- 消息队列
- 共享内存(IPC)
- socket
核心目的是交换数据
除了会枚举,这些名词的具体概念也应该做到心中有数,传送门
Q:线程间通信方式?
- 锁机制
- 信号量
核心目的是同步
Q:Callable、Runnable区别?
- 核心区别 Callable 有返回值,Runnable 没有返回值
- Callable的方法是call(),而 Runnable的方法是run()
- Callable可以抛出异常,而 Runnable不可以抛出异常
Q:Future和Callable的关系?
- Callable执行完后会有一个返回结果,可以通过Future类返回(异步计算的结果)。
- 此外,应当了解下FutureTask,其实现了Runnable和Future,并存在接收Callable的构造函数
Q:创建线程的方法?
- 继承Thread,再通过Thread的start()
- 实现Runnable,再通过new Thread(runnable)包装后,start()
- 用ExecutorService提交
Q:volatile关键字的作用?
- 防止指令重排(单例模式中)
- 内存可见性
Q:synchronized的用法?
- 修饰实例方法,作用于当前对象,两个不同对象不冲突
- 修饰静态方法,作用于当前类,两个不同对象也冲突
- 修饰代码块,对指定对象加锁
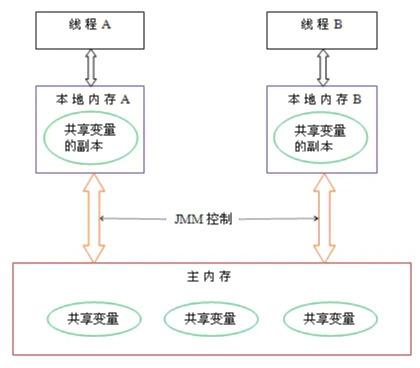
Q:讲一下Java内存模型?
网上一大堆,引用前人的清明上河图
Q:CountDownLatch和CyclicBarrier了解吗?
- CountDownLatch中一个线程等待其他几个线程完成。
- CyclicBarrier中几个线程相互等待某一事件的达成。
- CyclicBarrier可以复用。
Q:Semaphore用法?
控制一组资源的使用,通过acquire()和release()获取和释放这组锁,盼盼防盗门
Q:ThreadLocal作用?
修饰变量,控制变量作用域,使变量在同一个线程内的若干个函数中共享。
大佬指路
Q:单例与多例的区别?
- 单例非static和static变量都是线程不安全的
- 多例非static变量是线程安全的,但static变量依旧是线程不安全的
- 可以通过synchronized或ThreadLocal来完成static变量的线程安全
Q:锁释放的时机?
- 执行完同步代码块后
- 执行同步代码块途中,发生了异常,导致线程终止
- 执行同步代码块途中,遇到wait关键字,该线程释放对象锁,当前线程会进入线程等待池中,等待被唤醒
Q:notify唤醒时机?
notify后不会立刻唤醒处于线程等待池中的线程,而是等当前同步代码块执行完,才释放当前的对象锁,并唤醒等待线程。
Q:notify和notifyAll区别?
notify通知一个线程获取锁,而notifyAll通知所有相关的线程去竞争锁
Q:讲一下Lock?
Lock是为了弥补synchronized的缺陷而诞生的,主要解决两种场景
- 读写操作,读读不应该互斥
- 避免永久的等待某个锁
Lock是一个类,并非Java本身带的关键字,相对于synchronized而言,需要手动释放锁。
Q:锁的种类?
- 可重入锁,如ReentrantLock
- 可中断锁,lockInterruptibly()反应了Lock的可中断性
- 公平锁,synchronized是非公平锁,Lock默认也是非公平锁(可调整)
- 读写锁,如ReadWriteLock
集合
集合相对容易,常规送分题,基本都会问到HashMap
Q:TreeSet特性?
内部元素通过compare排序。
Q:LinkedHashMap特性?
内部有个双向链表维护了插入key的顺序,使得map能够依据插入key的顺序迭代。
Q:ArrayList与Vector的差别?
ArrayList是非线程安全的,Vector是线程安全的。
Q:LinkedList与ArrayList的差别?
- LinkedList基于链表,ArrayList基于数组
- LinkedList没有随机访问的特性
- ArrayList删除添加元素没有LinkedList高效
Q:HashMap与 HashTable 的差别?
- HashTable线程安全,HashMap线程不安全
- HashMap允许null key和value,而HashTable不允许
Q:Set与List的差别?各自有哪些子类?
Set不允许重复元素,List允许重复元素,List有索引
- Set:HashSet、LinkedHashMap、TreeSet
- List:Vector、ArrayList、LinkedList
Q:hashCode()、equals()、==区别?
- equals 比较两个对象是否相等,若相等则其hashCode必然相等
- 若两个对象的hashCode不等,则必然不equals
- ==比较内存地址,比较是否是同一对象
Q:Java容器中添加的对象是引用还是值?
引用
Q:Iterator和 ListIterator 的区别?
- ListIterator 能向前遍历,也能向后遍历
- 可以添加元素
- 可以定位当前index
Q:HashMap实现?
内容巨多,引用大佬面经,值得一看,目录供大家参考
- hashing的概念
- HashMap中解决碰撞的方法(拉链法)
- equals()和hashCode()的应用,在HashMap中到底如何判断一个对象有无
- 不可变对象的好处
- HashMap多线程的条件竞争
- 重新调整HashMap的大小
PS:HashSet是通过HashMap实现的
Q:ConcurrentHashMap和HashTable区别?
- HashTable通过synchronized来实现线程安全
- ConcurrentHashMap通过分段锁,仅锁定map的某一部分
GC
这块主要介绍JVM内存的划分以及GC算法
Q:什么是内存泄漏和内存溢出?
- 内存泄漏:无法释放已申请的内存空间,一次内存泄露危害可以忽略,但堆积后果很严重,无论多少内存,迟早会被漏光。
- 内存溢出:没有足够的内存空间供其使用。
内存泄漏最后会导致没有足够的空间分配对象,从而导致内存溢出,当然也可能开始分配过大的对象导致内存溢出
Q:导致内存溢出的因素?
- 内存中加载的数据量过于庞大,如一次从数据库取出过多数据。
- 集合类中有对象的引用,使用完后未清空,使得JVM不能回收。
- 代码中存在死循环或循环产生过多重复的对象实体。
- 启动参数内存值设定的过小。
Q:JVM内存划分?
- 堆:对象
- 方法区:类、静态变量和常量
- 栈:局部变量表
基本说出上面三条就可以了,更详细的见下图,前门

Q:简单说一下垃圾回收?
这可不简单…
垃圾定义:
- 引用计数法:循环引用会bug
- 可达性算法:GC Roots,如 栈中的引用对象、方法区静态、常量对象、本地方法区内的对象,不在堆中就可以
堆中内存分布:
- 新生代(33%):小对象,Eden:From Survivor:To Survivor=8:1:1
- 老年代(66%):大对象、长期存活的对象
- 永生代(三界之外):通常利用永生代来实现方法区
垃圾回收算法:
- 标记清除算法
- 复制清除(新生代)
- 标记整理清除(老年代)
Q:Minor GC、Major GC和 Full GC的区别?
- Minor GC是对 新生代 做垃圾回收
- Major GC是对 老年代 做垃圾回收
- Full GC是对 整个堆 做垃圾回收
Q:Full GC触发时机?
- System.gc(),并非一定触发,只是建议
- 老年代空间不足(核心触发点,其他方案都是从这里衍生出来)
- 永生代空间不足(当将方法区放在永生代中时)
- Minor GC后晋升到老年代中的大小>老年代剩余空间(其实就是2.老年代空间不足的一种表现)
- 堆中分配大对象(大对象可以直接进入老年代,导致老年代空间不足)
Q:什么是常量池?
常量池分为静态常量池和运行时常量池。
- 静态常量池:指的是在*.class文件中的常量池
- 运行常量池:指的是将*.class文件中的常量装载到内存中方法区的位置(当方法区放在永生代时,也可以理解为内存中的永生代)
包含的信息:
- 字符串字面量
- 类、方法信息
该问题一般会引出字符串常量比较
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel";
String s5 = "lo";
String s6 = s4 + s5;
String s7 = "Hel" + new String("lo");
String s8 = new String("Hello");
String s9 = s8.intern();
System.out.println(s1 == s2); // true,直接取自常量池
System.out.println(s1 == s3); // true,在编译时会优化成常量池内字符串的拼接,区别 s6
System.out.println(s1 == s6); // false,本质上是变量拼接,区别 s3
System.out.println(s1 == s7); // false,含有对象 new String("lo")
System.out.println(s1 == s8); // false,对象与字符串常量比较
System.out.println(s1 == s9); // true,字面量比较
复制代码 类加载
面试时有人问到过,回去大概查了下
Q:讲一下类加载过程?
- 加载:将*.class文件通过各种类加载器装载到内存中
- 链接:分为三步 验证:保证加载进来的字节流符合JVM的规范,我理解成语法上的验证(可能不严谨) 准备:为类变量(非实例变量)分配内存,赋予初值(该初值是JVM自已约定的初值,非用户自定义初值,除非是常量,用final static修饰的) 解析:将符号引用替换成直接引用(A.a()=> 某一内存地址)
- 初始化:对类变量初始化,执行类变量的构造器
Q:Java初始化顺序?
这是在爱奇艺碰到的一面试道题,当时差点两眼一抹黑过去了…头一次发现这么多东西要初始化
- 一个类中初始化顺序(先类后实例)
类内容(静态变量、静态初始化块) => 实例内容(变量、初始化块、构造器)
- 继承关系的两个类中初始化顺序(先类后实例,再先父后子)
父类的(静态变量、静态初始化块)=> 子类的(静态变量、静态初始化块)=> 父类的(变量、初始化块、构造器)=> 子类的(变量、初始化块、构造器)
Q:Java类加载器的种类?
- 启动Boostrap类加载器:加载路径<JAVA_HOME>/lib
- 扩展Extension类加载器:加载路径<JAVA_HOME>/lib/ext
- 系统System类加载器:加载路径 -classpath
Q:双亲委派模式了解吗?
我理解的深度比较浅,个人理解,委派就是加载类时先看上层加载过没,如果加载过了,当前就不加载了,直接使用当成加载器加载的类。
其次是加载顺序,System->Extension->Boostrap
优点:
- 避免重复加载类
- 核心API不会被改动
面向对象
这些问题很弱鸡,但考的也比较多
Q:面向对象的三大特性?
顺口溜一般的背出来:封装、继承、多态
然后会让你讲讲这三个特性如何体现,大家自己想想吧,言之有理即可
Q:Java中接口和抽象类区别?
- 可以实现多个接口(implement),但只能继承一个抽象类(extend)
- 接口中的方法不能实现,抽象类中可以实现部分方法
- 接口中数据全是public static final类型的,方法全是public abstract的
- 本质上,接口是说对象能干什么,抽象类是说对象是什么
Q:重载和重写?
猪脑子,老记混
- 重载:同一个类中,函数名一样,但接受的参数一定不同,返回的结果可以不同
- 重写:不同类中,函数名一样,参数一样,结果也一样
设计模式
Q:例举一下你了解的设计模式?
一般说5、6个,有个样例就行了
- 组合模式:集合的addAll
- 装饰者模式:stream的各种嵌套
- 抽象工厂:JDBC中driver创建新连接
- 建造者模式:StringBuilder或SQL中PreparedStatement
- 责任链:structs2中对请求的处理各种Filter
- 解释器:正则表达式
- 观察者:swing中的事件监听各种Listener
Q:手撸单例?
撸完,让你讲讲内部细节,volatile或多例问题
public class Singleton {
private volatile static Singleton singleton;
private Singleton(){}
public static Singleton getSingleton(){
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
复制代码 网络协议
Q:TCP3次握手4次挥手?
基本画张图就K.O.了,fate门,内部的问题也建议看一下
Q:TCP为什么是一定要是3次握手,而不是2次或3次以上?
2次挥手的问题
在第1次建立过程中,client请求链接在网络中滞留过久,导致client发送第2次请求,建立完毕后,这时第1次的请求到达server,server接收又维护一链接,但该链接实际上已经作废,浪费了server端的资源。
3次以上的方案
理论上,做到3次以上是可行的,但真正想做到一个完美可靠的通信是不可能的,因为每次答复都是对上次请求的响应,但该次答复在不可靠的信道中仍是会丢失的,考虑到现实效率问题,3次足以。
Q:TCP为什么是4次挥手,而不是3次呢?
- 握手的第二次携带了,响应ACK和请求SYN信息
- 挥手过程中不能一次性携带这两种信息,因为server方可能还有数据没传输完。
Q:TCP半连接池与全连接池?
- 半连接池:接受client握手第一步请求时,将该次链接放到半连接池中,Synflood的主要攻击对象
- 全连接池:接受client握手第二步请求时,将该次链接从半连接池中取出放到全连接池中。
Q:TCP和 UDP 的区别?
- TCP基于连接,而UDP基于无连接
- TCP由于有握手和挥手的过程消费资源相对较多
- TCP是传输数据流,而UDP是数据报
- TCP保证数据正确性和顺序性,而UDP可能丢包,不保证有序
Q:TCP和UDP的应用?
- TCP:FTP、HTTP、POP、IMAP、SMTP、TELNET、SSH
- UDP:视频流、网络语音电话
Q:TCP/IP与OSI模型?
TCP/IP模型,自下而上
- 链路层
- 网络层(IP、ICMP、IGMP)
- 运输层(TCP、UDP)
- 应用层(Telnet、FTP)
OSI模型,自下而上
- 物理层
- 数据链路层
- 网络层
- 运输层
- 会话层
- 表示层
- 应用层
Q:ping命令基于哪种协议?
ICMP
Q:阻塞式和非阻塞式IO区别?
阻塞式
- 每来一个连接都会开启一个线程来处理,10个线程对应10个请求
- 线程大多时候都在等在数据的到来,浪费资源
- 适合并发量小,数据量大的应用
非阻塞式
- 基本思想,将所有连接放在一张table中,然后轮询处理
- 实现上可以用事件通知机制,可以用10个线程处理100个请求
- 适合并发量大,数据量小的应用
数据库
用数据库做过开发,但是了解的不深入,面试问我会不会写SQL时,我多答“简单的可以,复杂的尝试一下”…SQL复杂起来真不是人写的…
Q:聚集索引和非聚集索引区别?
- 聚集索引:叶子节点是实际数据,表中只能有一个聚集索引
- 非聚集索引:叶子节点是地址,需要再跳转一次,表中可以有多个非聚集索引
Q:where、group by、having执行顺序?
- where 过滤行数据
- group by 分组
- having 过滤分组
Q:星型、雪花结构?
- 星型:存在部分冗余
- 雪花:表切分的十分细,没有冗余
出自
Q:SQL纵向转横向,横向转纵列?
基本上,除了 group by + 聚集函数 外,这是最难的 SQL 题了
- 纵向转横向
sum(case when A=’a’ then B else 0 end) as D
这里需要用sum或其他聚集函数,因为作用在一个group中
- 横向转纵向
核心用union
记住这两条做到举一反三就可以了,Demo
Q:脏读、不可重复读、幻读?
- 脏读:事务A读取了事务B提交的值
- 不可重复读:事务A两次读取了事务B的值,事务B在该过程中修改并提交过,导致A两次读取值不一致
- 幻读:事务A修改 a 到 b ,事务B在该过程中添加了新的a,导致新添加的a,没有修改成b
这引出事务隔离级别
事务隔离级别 脏读 不可重复读 幻读 读未提交(read-uncommitted) 是 是 是 不可重复读(read-committed) 否 是 是 可重复读(repeatable-read) 否 否 是 串行化(serializable) 否 否 否
Q:join实现的三种方式?
- nested loops:嵌套迭代,相当于两个for循环,内部表有索引时,效果较好
- merge join:将两表先sort(如果没sort的话),再合并
- hash join:将表hash,然后扫描另一表
Linux
Q:查看xxx端口占用?
- netstat -tunlp |grep xxx
- lsof -i:xxx
Q:查看xxx进程占用?
- ps -ef |grep xxx
Q:查看CPU使用情况?
- top
Q:查看内存使用情况?
- free
- top
Q:查看硬盘使用情况?
- df -l
Q:$0、$n、$#、$*、$@、$?、$$含义?
变量 含义 $0 当前脚本的文件名 $n 传递给脚本的第n个参数 $# 传递给脚本的参数个数 $* 传递给脚本所有参数 $@ 传递给脚本所有参数。与$*有小差别,出门下扒 $? 上个命令的退出状态 $$ 当前Shell进程ID
Q:>、>>区别?
- >:重定向到一个文件
- >>:追加到一个文件
Q:>、1>、2>、2>&1、2>1区别?
- >:默认是正确输出到某一文件,错误直接输出到控制台
- 1>:正确输出
- 2>:错误输出
- 2>&1:将错误输出重定向到正确输出中,一般前面会有 1> a.txt,这样后面的错误也会输出到 a.txt,通过正确输出
- 2>1:错误输出到 1 文件中,错误写法,区分&1
Q:定时任务命令?
- crontab
算法
算法的海洋的无边无际,但是应付面试题的算法,个人认为《剑指offer》一本足矣…
个人《剑指offer》刷了大概四遍,基本上看到一道题,所有解法都知道,面试上也基本从这里出
我遇到现场出的算法题(除了《剑指offer》上的),一般是暴力搜索题,不要上来想DP…
经典问题
- 子串匹配问题
- 子序列匹配问题
- 合并链表
- 树中两个节点最近的公共父节点
- 快排、堆排
- 各种类型的二分查找
- 两数交换,不用第三变量
- 水塘抽样,大佬题解
智力题
- 一根棍子随机折三节,组成三角形的概率
- 倒水问题
- 面粉称重问题
- 烧绳子问题
大数据
这方面一般问的是偏向于各类框架
- Hadoop
- Yarn
- Spark
- Hive
- HBase
- Zookeeper
以上框架,大家各取所需吧,总有几个要能拿出来吹的,我个人主要吹Spark这块
Hive、HBase一般也是当工具用的,主要问平时用没用过,用过的话就会多问些,我一般是回答搭建过,照着文档看过一阵子,对方一般就不问了
Zookeeper在底层维护分布式的一致性,多少了解一些分布式协议raft这类的也是加分点
Hadoop
Q:两表Join方案?
- reduce side join:最基本的
- map side join:分发小表,做only map
- semi join + reduce side join:提取一表的key,分发出去,再做reduce side join,减轻join的数据量
- semi join + bloomfilter + reduce side join:基于上面方案的改良,主要应对key太大也放不下去的情况
3、4方案了解即可,个人感觉有些不靠谱,面试中一般没提,面试官一般要求到2,有数据倾斜的另说
Q:MapReduce过程?
大数据岗位必考题
三言两语也说不清,建议去看网上大佬的,传送门
看完后能回答如下几个问题即可:
- map处理过程中,数据满了如何处理的
- combiner作用、位置
- 几次sort,发生位置,什么样的sort
Q:Hadoop 中 Secondary NameNode作用?
合并fsimage与editlog
Yarn
Q:Yarn架构?
Q:Yarn相对于Hadoop的优势,或说为什么要有Yarn?
- 简化JobTracker,将其功能下放到ResourceManager和ApplicationMaster
- 资源以内存为单位,相比之前剩余slot更合理
- 通过Container的抽象,使集群能支持多种框架如Spark
Q:Yarn延迟调度的含义?
主要针对当作业所需的资源,在本地并没有满足时,会延迟一段时间,再尝试调度,实在不行时会放到别的机器上调度,主要因为本地调度效率最高。
Spark
Q:Spark有几种部署模式?
- local
- standalone
- yarn
- mesos
Q:standalone基本架构?
- Client:提交job
- Master:收集client提交的job,管理worker
- Worker:管理本节点的资源,定时想master汇报使用情况
- Driver:含DAGScheduler、TaskScheduler,根据client与cluster决定driver的具体在client还是worker上
- Executer:位于Worker上,job真正执行的地方
Q:groupByKey和reduceByKey哪个效率高?
- reduceByKey效率更高,在每个executor上执行时,附带合并逻辑,结果更紧凑(可以理解为 key,value),shuffle量小
- groupByKey保留同key的所有数据(可以理解为 key,List)
Q:数据倾斜是什么?如何处理?
必考题,可以问的很深…
定义:shuffle过程中,某个几个key对应的value太多,集中在某一个reduce task中,导致该task处理过慢或直接崩掉(out of memory)
解决方案:
- 换用更高性能的计算机,加memory:从而避免内存溢出,不过治标不治本,面试官一般不会满意
- 修改并行度:说不定刚好把这几个拥有众多value的key划分开来,当都集中在少数的key,或说在1个key上时,无效
- 加随机数,做两次聚合:第一次聚合时,key以 random数_key 作为新key,第二次聚合时,去掉random数,相当于将原始key所对应的分区先局部聚合,再统一聚合,面试官一般期待能讲到这里
求大佬点拨,个人认为随机数这种算法可以解决一定的数据倾斜,但
- 用combiner的思想和这个是一致的?那random数_key似乎没有什么价值了
- 只能解决可以用combiner的场景,不能用combiner的场景如何解决呢?
Q:倾斜join如何处理?
和上面的数据倾斜有一定联系,但不完全相同
- map side join:在hadoop那边讲join方式提到过
- 加随机值并扩容表:将倾斜key中,较小表映射成 range_key,其中range取遍[0,…,n-1]中每个数,即小表中每条记录会被映射成n条不一样key的记录;将较大表映射成single_key,其中single 是由 random(n) 产生,即大小表中每条记录会被映射成唯一一条随机key的记录,然后做join即可
Q:基本概念?
问的很多,主要看你对Spark的了解程度
- RDD
- DAG
- Stage
- 宽依赖、窄依赖
- 并行度
Q:枚举一下transform和action?
- transform:filter、map、flatmap、reduceByKey、groupByKey
- action:take、collect、count、foreach
Kafka
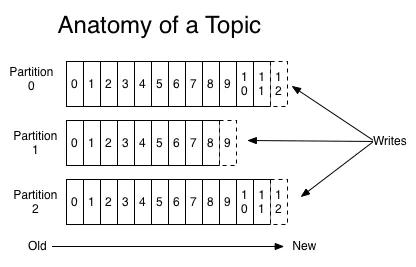
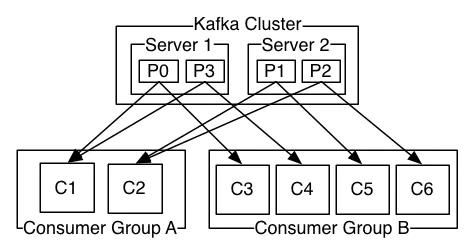
Q:基本架构?

- Producer
- Consumer
- Broker
- Topic
- Partition
- Leader
- Follower
- User Group
- Offset
能把以上这些概念串起来基本就OK
Q:介绍下ISR副本策略?
一个leader与一堆副本follower,follower从leader上拉取副本并返回ack,leader收集到足够多的ack后,认为该message是committed,并返回给client。
该leader与这些follower被称为 in sync 状态,这个集合是动态变化的,当某个follower拉下太多时,会被踢出该集合,从而保证了能快速的响应用户请求,当它追上来时会再加入该集合。
为了保证数据不丢失,可以设置该集合最少需要多少个follwer,当小于该数时该partition便不可用瞅一眼?
因为包含的知识点内容实在是太多了,所以总结成为了Java核心知识点技术文档,希望大家能够喜欢!!!
JVM
2.1. 线程
2.2. JVM内存区域
2.3. JVM运行时内存
2.4.垃圾回收与算法
2.5. JAVA四中引用类型
2.6. GC分代收集算法VS分区收集算法
2.7. GC垃圾收集器
2.8. JAVA IO/NIO
2.9. JVM类加载机制
JAVA集合
3.1. 接口继承关系和实现
3.2. List
3.3. Set
3.4. Map
Java多线程并发
4.1.1. JAVA并发知识库
4.1.2. JAVA线程实现/创建方式
4.1.3. 4种线程池
4.1.4.线程生命周期(状态)
4.1.5.终止线程4种方式
4.1.6. sleep与wait区别
4.1.7. start与run区别
4.1.8. JAVA后台线程
4.1.9. JAVA锁
4.1.10.线程基本方法
4.1.11.线程上下文切换
4.1.12.同步锁与死锁
4.1.13.线程池原理
4.1.14. JAVA阻塞队列原理
4.1.15. CyclicBarrier、CountDownLatch、Semaphore的用法
4.1.16. volatile关键字的作用(变量可见性、禁止重排序)
4.1.17.如何在两个线程之间共享数据
4.1.18. ThreadLocal作用(线程本地存储)
4.1.19. synchronized和ReentrantLock的区别
4.1.20. ConcurrentHashMap并发
4.1.21. Java中用到的线程调度
4.1.22.进程调度算法
4.1.23.什么是CAS (比较并交换-乐观锁机制锁自旋)
4.1.24.什么是AQS (抽象的队列同步器)
Java基础
5.1.1. JAVA异常分类及处理
5.1.2. JAVA反射
5.1.3. JAVA注解
5.1.4. JAVA内部类
5.1.5. JAVA泛型
5.1.6. JAVA序列化(创建可复用的Java对象)
5.1.7. JAVA复制
Spring原理
6.1.1. Spring特点
6.1.2. Spring核心组件
6.1.3. Spring常用模块
6.1.4. Spring主要包
6.1.5. Spring常用注解
6.1.6. Spring第三方结合
6.1.7. Spring I0C原理
6.1.8. Spring APO原理
6.1.9. Spring MVC原理
6.1.10. Spring Boot原理
6.1.11. JPA原理
6.1.12. Mybatis缓存
6.1.13. Tomcat架构
微服务
7.1.1.服务注册发现
7.1.2. API网关
7.1.3.配置中心
7.1.4.事件调度(kafka)
7.1.5.服务跟踪(starter-sleuth
7.1.6.服务熔断(Hystrix)
7.1.7. AP|管理
Netty与RPC
8.1.1. Netty原理
8.1.2. Netty高性能
8.1.3. Netty RPC实现
8.1.4. RMI实现方式
8.1.5. Protoclol Buffer
8.1.6. Thrift
网络
9.1.1.网络7层架构
9.1.2. TCP/IP原理
9.1.3. TCP三次握手/四次挥手
9.1.4. HTTP原理
9.1.5. CDN原理
日志
10.1.1. SIf4j
10.1.2. Log4j
10.1.3. LogBack
10.1.4. ELK
Zookeeper
11.1.1. Zookeeper概念
11.1.1. Zookeeper角色
11.1.2. Zookeeper工作原理(原子广播)
11.1.3. Znode有四种形式的目录节点
Kafka
12.1.1. Kafka概念
12.1.2. Kafka数据存储设计
12.1.3.生产者设计
12.1.1.消费者设计
RabbitMQ
13.1.1.概念
13.1.2. RabbitMQ架构
13.1.3. Exchange类型
Hbase
14.1.1.概念
14.1.2.列式存储
14.1.3. Hbase核心概念
14.1.4. Hbase核心架构
14.1.5. Hbase的写逻辑
14.1.6. HBase Vs Cassandra
MongoDB
15.1.1.概念
15.1.2.特点
Cassandra
16.1.1.概念
16.1.2.数据模型
16.1.3. Cassandra-致Hash和虚拟节点
16.1.4. Gossip协议
16.1.5.数据复制
16.1.6.数据写请求和协调者
16.1.7.数据读请求和后台修复
16.1.8.数据存储(CommitLogMemTable、SSTable)
16.1.9.二级索引(对要索弓的value摘要,生成RowKey)
16.1.10.数据读写
设计模式
17.1.1.设计原则
17.1.2.I厂方法模式
17.1.3.抽象工厂模式
17.1.4.单例模式
17.1.5.建造者模式
17.1.6.原型模式
17.1.7.适配器模式
17.1.8.装饰器模式
17.1.9.代理模式
17.1.10.外观模式
17.1.11.桥接模式
17.1.12.组合模式
17.1.13.享元模式
17.1.14.策略模式
17.1.15.模板方法模式
17.1.16.观察者模式
17.1.17.迭代子模式
17.1.18.责任链模式
17.1.19.命令模式
17.1.20.备忘录模式
17.1.21.状态模式
17.1.22.访问者模式
17.1.23.中介者模式
17.1.24.解释器模式
负载均衡
18.1.1.四层负载均衡vs七层负载均衡
18.1.2.负载均衡算法/策略
18.1.3. LVS
18.1.4. Keepalive
18.1.5. Nginx反向代理负载均衡
18.1.6. HAProxy
数据库
19.1.1.存储引擎
19.1.2.索引
19.1.3.数据库三范式
19.1.4.数据库是事务
19.1.5.存储过程(特定功能的SQL语句集)
19.1.6.触发器(一段能自动执行的程序)
19.1.7.数据库并发策略
19.1.8.数据库锁
19.1.9.基于Redis分布式锁
19.1.10.分区分表
19.1.11.两阶段提交协议
19.1.12.三阶段提交协议
19.1.13.柔性事务
19.1.14. CAP
一致性算法
20.1.1. Paxos
20.1.2. Zab
20.1.3. Raft
20.1.4. NWR
20.1.5. Gossip
20.1.6.一致性Hash
JAVA算法
21.1.1.二分查找
21.1.2.冒泡排序算法
21.1.3.插入排序算法
21.1.4.快速排序算法
21.1.1.希尔排序算法
21.1.2.归并排序算法
21.1.3.桶排序算法
21.1.4.基数排序算法
21.1.5.剪枝算法
21.1.6.回溯算法
21.1.7.最短路径算法
21.1.8.最大子数组算法
21.1.9.最长公共子序算法
21.1.10.最小生成树算法
数据结构
2.1.1.栈(stack)
2.1.2.队列(queue)
2.1.3.链表(ink)
22.1.4.散列表(Hash Table)
22.1.5.排序二叉树
22.1.6.红黑树
22.1.7. B-TREE
22.1.8.位图
加密算法
23.1.1. AES
23.1.2. RSA
23.1.3. CRC
23.1.4. MD5
分布式缓存
24.1.1.缓存雪崩
24.1.2.缓存穿透
24.1.3.缓存预热
24.1.4.缓存更新
24.1.5.缓存降级
Hadoop
25.1.1.概念
25.1.2. HDFS
25.1.3. MapReduce
25.1.4. Hadoop MapReduce作业的生命周期
Spark
26.1.1.概念
26.1.2.核心架构
26.1.3.核心组件
26.1.4. SPARK编程模型
26.1.5. SPARK计算模型
26.1.6. SPARK运行流程
26.1.7. SPARK RDD流程
26.1.8. SPARK RDD
Storm
27.1.1.概念
27.1.1.集群架构
27.1.2.编程模型(spout-> tuple-> bolt)
27.1.3. Topology运行
27.1.4. Storm Streaming Grouping
YARN
28.1.1.概念
28.1.2. ResourceManager
28.1.3. NodeManager
28.1.4. ApplicationMaster
28.1.5. YARN运行流程
机器学习
29.1.1.决策树
29.1.2.随机森林算法
29.1.3.逻辑回归
29.1.4. SVM
29.1.5.朴素贝叶斯
29.1.6. K最近邻算法
29.1.7. K均值算法
29.1.8. Adaboost算法
29.1.9.神经网络
29.1.10.马尔可夫
云计算
30.1.1. SaaS
30.1.2. PaaS
30.1.3. laas
30.1. .4. Docker
30.1.4.1.概念
30.1.4.2. Namespaces
30.1.4.3.进程(CLONE_ NEWPID实现的进程隔离)
30.1.4.4. Libnetwork与网络隔离
30.1.4.5.资源隔离与CGroups
30.1.4.6.镜像与UnionFS
30.1.4.7.存储驱动
30.1.5. Openstack
需要这份Java核心知识点的朋友,可以转发关注小编,私信小编“面试”来获取!!
还有一份大厂面试题分享给大家!


需要这份Java核心知识点和面试题的朋友,可以转发关注小编,私信小编“面试”来获取!!


