1、 IK的介绍
Elasticsearch IK分析器插件是国内非常著名的开源中文分析器插件,它是基于国人所开发的另一款基于Luence 的IK分词器做的扩展,以达到对 Elasticsearch 的支持。Elasticsearch IK分词器是Java语言编写的,在Elasticsearch 0.16的时候就已经开始对其支持了,涵盖了Elasticsearch后续各版本的支持。
它包括了ik_smart和ik_max_word两种分析器,包括了与两种分析器对应的分词器ik_smart和ik_max_word,ik_smart和ik_max_word两种分析器的区别如下: ik_smart:ik_smart的分词的粒度比较粗,适合于基本Phrase的查询,如会把“中华人民共和国”只拆分成“中华人民共和国”; ik_max_word:ik_max_word的拆分就会很细,会穷尽所有的可能,以便于查找到最多的结果,适合于Term Query,同样的对“中华人民共和国”进行分词,它会拆分成“中华人民共和国,中华人民,中华,华人,人民共和国,人民,共和国,共和,国”;
2、 IK的安装
IK的项目托管在Github上,项目地址为:
IK的版本从5.x开始就和Elasticsearch的版本是一一对应的了,如下所示:
Elasticsearch版本
IK版本
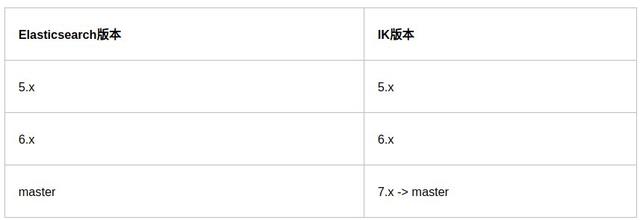
安装的时候一定要选与当前Elasticsearch版本一致的版本,因为每个版都可能会涉及到功能实现上的修改,以避免版本上的不一致出现的问题。
IK的安装方式有两种(也可以下载源码自己编译),针对5.5.1以前的版本,只能够将IK下载到Elasticsearch的plugins目录中,5.5.1过后的版本,支持通过Elasticsearch的插件安装命令进行安装,如下所示7.0.0的安装命令:
$ ./bin/elasticsearch-plugin install
安装完成后,需要重新启动整个集群。如果安装正常,会在Elasticsearch的启动控制台可以看到如下日志的输出:
loaded plugin [analysis-ik]
...
try load config from $ES_HOME/config/analysis-ik/IKAnalyzer. cfg .xml
try load config from $ES_HOME/plugins/ik/config/IKAnalyzer.cfg.xml
说明IK被成功加载。其中显示两次配置文件的加载,表示IK会从这两个位置加载配置文件,首先去Elasticsearch的配置文件所在目录加载:
$ ES_HOME/config/analysis-ik/IKAnalyzer.cfg.xml
如果没有加载成功,则从IK的安装目录进行加载:
$ ES_HOME/plugins/ik/config/IKAnalyzer.cfg.xml
配置文件IKAnalyzer.cfg.xml中的内容如下,默认如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM ""> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
该配置文件用于配置额外配置的扩展字典和扩展停止词字典,字典必须满足以下两个条件:
文件必须以UTF-8编码 每行一个词
配置文件中的ext_dict和ext_stopwords分别配置本地加载的扩展字典和扩展停止词字典,可以配置加载多个字典,他们以英文分号“;”做分隔符,不支持动态配置。remote_ext_dict和remote_ext_stopwords分别用于配置远程扩展词典和远程扩展停止词字典,可以用于动态加载字典,配置的地址为字典的URL地址,如“”,也可以以英文分号“;”做分隔符配置多个字典URL地址;为了让IK识别到字典有更新,需要在HTTP响应头Header中增加Last-Modified或ETag响应头,其中只要有一个响应头发生了变化,IK就会重新加载字典,这样就达到了通过远程文件对字典进行热更新的目的。
注:为了方便增加响应头,可以使用Nginx做为字典文件的HTTP服务器,Nginx会自动的为响应文件增加Last-Modified头。
如果没有配置扩展字典,IK默认不加载任何的扩展词,只加载以下的字典文件:
main.dic
preposition.dic
quantifier.dic
stopword.dic
suffix.dic
surname.dic
IK也自带了一些扩展词典:
extra_main.dic extra_single_word_full.dic extra_stopword.dic extra_single_word.dic extra_single_word_low_freq.dic
如果要想使用这些扩展词字典,只需要在配置文件IKAnalyzer.cfg.xml中配置好就行。
3、IK的使用
1)分词器的验证
验证一下IK是否安装成功,通过以下语句验证分词器ik_max_word。
请求:
GET /_analyze
{
"analyzer": "ik_max_word",
"text": ["中华人民共和国"]
}
响应:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
...省略更多的结果
]
}
通过以下语句验证分词器ik_smart。
请求:
GET /_analyze
{
"analyzer": "ik_smart",
"text": ["中华人民共和国"]
}
响应:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
}
]
}
2) 实例操作
以下是一个演示场景,先创建 索引 并指定mapping(如果不理解mapping,可以先理解为给数据库中表的字段定义类型,以后会详解),mapping中指定了用于测试的字段title的索引分析器为ik_max_word,希望其分析出的词项尽可能的多一些,以后被搜索到的机率就会更多,而搜索分析器指定的是ik_smark,希望搜索出来的结果中要尽量的包含输入的内容,然后插入数据,再执行查询操作并比较查询结果。
创建索引
请求:
PUT /ik_index_sample
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
响应:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "ik_index_sample"
}
索引创建成功。
写入数据
通过批量操作语句写入以下测试数据。
请求:
POST /_bulk
{ "index" : { "_index" : "ik_index_sample", "_id" : "1" } }
{ "title" : "中华人民共和国(People's Republic of China),简称“中国”,成立于1949年10月1日,位于亚洲东部,太平洋西岸" }
{ "index" : { "_index" : "ik_index_sample", "_id" : "2" } }
{ "title" : "中国政府网_中央人民政府门户网站官网" }
{ "index" : { "_index" : "ik_index_sample", "_id" : "3" } }
{ "title" : "中国(世界四大文明古国之一)_百度百科" }
{ "index" : { "_index" : "ik_index_sample", "_id" : "4" } }
{ "title" : "“金蓝领”为“中国创造”添彩--社会--人民网" }
{ "index" : { "_index" : "ik_index_sample", "_id" : "5" } }
{ "title" : "在4月29日播出的《 这就是中国 》节目中,复旦大学中国研究院院长张维为教授就“西方中心论”进行了解构。" }
响应:
{
"took" : 76,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "ik_index_sample",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
" total " : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
...//省略掉多余的语句
]
}
响应提示数据插入成功。
搜索
请求:
GET /ik_index_sample/_search
{
"query": {
"term": {
"title": {
"value": "中国"
}
}
}
}
响应:
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 0.11295266,
"hits" : [
{
"_index" : "ik_index_sample",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.11295266,
"_source" : {
"title" : "“金蓝领”为“中国创造”添彩--社会--人民网"
}
},
...//省略其它4条数据
]
}
}
提示5条记录全部查询出来了,可以认为达到了我们的预期结果。


