信息检索系统
信息检索系统分为信息采集、信息整理、用户查询。
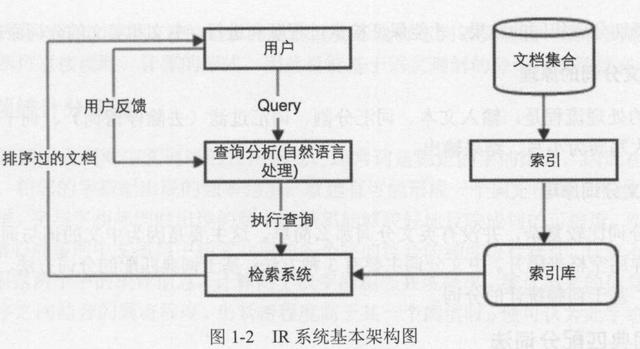
信息采集
网络爬虫:按照一定的规则,自动地抓取万维网信息的程序或脚本。
经过格式化处理之后提取网页信息为构建索引做准备。
整理信息
索引构建:信息检索系统整理信息的过程。
信息检索系统不仅要保存搜集起来的信息,还要将它们按照一定的规则进行编排。
接受查询
分词算法概述
词是表达语义的最小单位。
分词可以帮助搜索引擎自动识别语句的含义,从而使搜索结果的匹配程达到最高,分词的质量直接影响了搜索结果的准确度。
分词在文件索引的建立过程和用户提交检索过程中都存在。
利用相同的分词器,把短语或句子切分成相同的结果,才能保证检索结果顺利进行。
英文分词的原理
输入文本、词汇分割、词汇过滤(去除停留词)、词干提取(形态还原)、大写转为小写、结果输出。
中文分词原理
中文词与词之间不是用空格分隔的。
中文分词法——词典匹配分词法
按照一定的匹配策略将输入的字符串与机器字典词条进行匹配。
把一个句子从左向右扫描一遍,遇到字典中有的词就标识出来,遇到复合词就找最长词匹配,遇到不认识的字符串则 切分 为单个词。
中文分词法——词典匹配分词法——分类
扫描方向:正向匹配、逆向匹配、双向匹配
不同长度优先匹配:最大(最长)匹配、最小(最短)匹配
与词性标注过程相配合:单纯分词方法、分词与词性标注相结合
中文分词法——词典匹配分词法——最常用
正向最大匹配(由左到右的方向)
逆向最大匹配(由右到左的方向)
最少切分(每一句中切除的词数最少)
中文分词最大的问题是歧义处理,结合中文语言自身的特点,采用逆向匹配的切分算法,处理的精度高于正向匹配,产生的切分歧义最少。
真正实用的分词系统,都是把字典分词作为基础手段,结合语言的各种其他特征信息来提高切分的效果和准确度。
中文分词法—语义理解分词法
模拟人脑对语言和句子的理解,达到识别词汇单元的结果。
基本模式:把分词、句法、语义分析并行进行,利用句法和语义信息来处理分词的歧义。
包括分词子系统、句法语义子系统、 调度系统 。
在调度系统的协调下,分词子系统可以获得有关词、句子等的句法和语义信息,模拟人脑对句子的理解过程。
基于语义理解的分词方法需要使用大量的语言知识和信息。
中文分词法—词频统计分词法
基于对中文词语的直接感觉。
词是稳定的字的结合,在中文文章的上下文中,相邻的字搭配出现的频率越多,就越有可能形成一个固定的词。
根据n元语法知识,字与字相邻同时出现的频率或概率能够较好地反映成词的可信度。
无字典分词法或统计分词法。
实际应用的统计分词系统都使用一个基本的常用词字典,把字典分词和统计分词相结合。
基于统计的方法能很好地解决词典未收录新词的问题,即将中文分词中的串频统计和串匹配相结合起来,即发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的特点。


