
然后之前上一节我们看来,在flink中有3中更新模式,用来,比如
追加模式用来:插入流数据,
撤回模式,可以:add 可以delete 可以update对吧
更新插入模式,可以 upsert对吧,然后可以delete删除消息
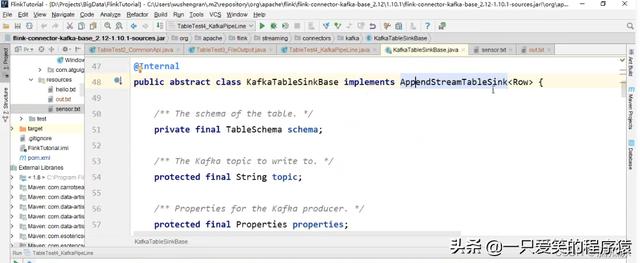
我们之前,说往文件中插入数据,以及往 kafka 中输出数据,
都是只能插入数据,不能插入经过聚合统计的数据对吧aggTable不能插入
可以看到文件输出,以及kafkaTableSinkBase都是实现了
Append StreamTableSink的
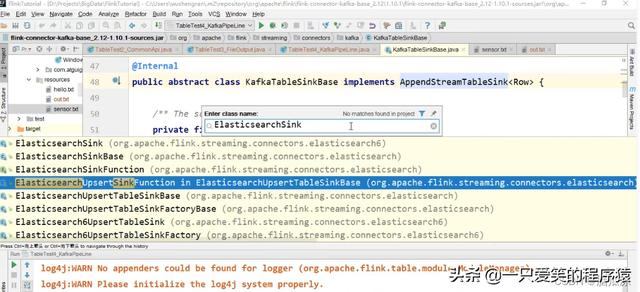
然后我们再来看,怎么样把aggTable,这样的经过聚合统计的数据,插入的存储系统呢?
注意,es可以,我们可以看到es有个 Elasticsearch UpsertSink Function 对吧
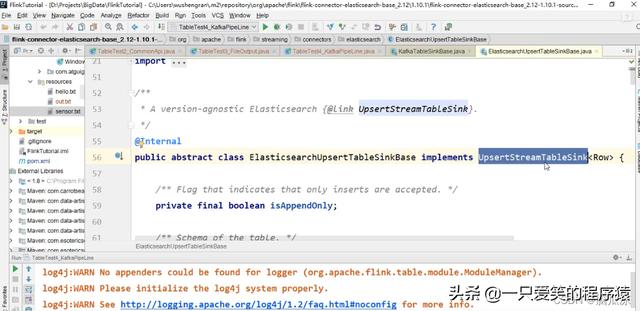
可以看到这个
ElasticsearchUpsertTableSinkBase,这个实现至
UpsertStreamTableSink对吧.可以看到这个是
可以进行插入以及更新的对吧

然后使用方法可以看到上面的代码,也很简单对吧
可以看到这里使用new Json的format插入的数据
这里要注意他使用的是:.inUpsertMode对吧
更新插入模式
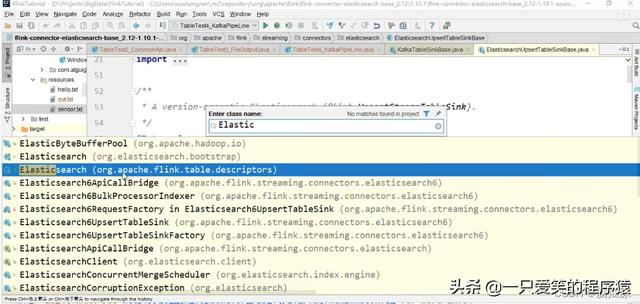
然后我们再看这个Elasticsearch这里
看源码,可以看到这里我们之前就引入了依赖了,不需要额外引入了
左侧已经有elasticsearch的依赖包了
然后我们在看,像上面我们做的聚合统计就可以输入到es中去了

可以看到这里主要是指定一下输出模式,这里用inUpsertMode模式
然后再看一下这里的ElasticsearchUpsertTableSinkBase
这里可以看到ElasticsearchUpsertTableSinkBase实现了UpsertStreamTableSink对吧.
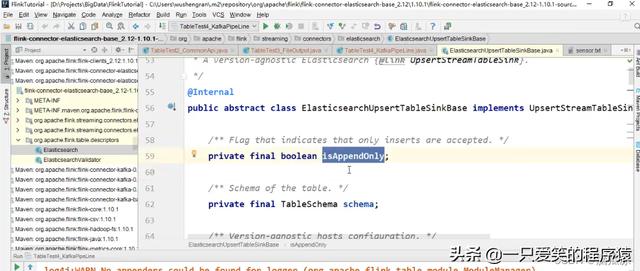
可以看到我们说,所有的支持Upsert操作的,输出的外部系统肯定都支持
插入操作对吧,所以可以看到
在这个ElasticsearchUpsertTableSinkBase中,有个isAppendOnly,这个属性
可以看到,这个默认就是isAppendOnly 是true对吧,如果我们直接调用的话,他默认
就是只插入的,如果我们指定了:
inUpsertMode以后,这个属性其实就变成false了,就是不仅仅用,只插入数据的
模式了.

然后我们再看一下,把数据输出到mysql中
可以看到这里直接就是使用 ddl 对吧,可以看到

这里需要引入一个mysql的依赖,flink对mysql的支持
flink- jdbc _2.12对吧


