目录:
一.生产者和消费者模式
二.线上问题定位
三.性能测试
四.异步任务池
当你在进行并发编程时,看着程序的执行速度在自己的优化下运行得越来越快,你会觉得越来越有成就感,这就是并发编程的魅力。但与此同时,并发编程产生的问题和风险可能也会随之而来。
一.生产者和消费者模式
线程通信 ,在 多线程 系统中,不同的线程执行不同的任务;如果这些任务之间存在联系,那么执行这些任务的线程之间就必须能够通信,共同协调完成系统任务。

线程通信
生产者、消费者案例
案例分析
在案例中明,蔬菜基地作为生产者,负责生产蔬菜,并向超市输送生产的蔬菜;消费者通过向超市购买获得蔬菜;超市怎作为生产者和消费者之间的共享资源,都会和超市有联系;蔬菜基地、共享资源、消费者之间的交互流程如下:

生产者、消费者案例
在这个案例中, 为什么不设计成生产者直接与给消费者交互 ?让两者直接交换数据不是更好吗?选择先把 数据存储 到共享资源中,然后消费者再从共享资源中取出数据使用,中间多了一个环节不是更麻烦了?
其实不是的,设计成这样是有原因的,因为这样设计很好地体现了面向对象的 低 耦合 的设计理念 ;通过这样实现的程序能更加符合人的操作理念,更加贴合现实环境;同时,也能很好地避免因生产者与消费者直接交互而导致的操作不安全的问题。
我们来对 高耦合和低耦合 做一个对比就会很直观了:
- 高(紧)耦合:生产者与消费者直接交互 ,生产者(蔬菜基地)把蔬菜直接给到给消费者,双方之间的依赖程度很高;此时,生产者中就必须持有消费者对象的引用,同样的道理,消费者也必须要持有生产者对象的引用;这样,消费者和生产者才能够直接交互。
- 低(松)耦合: 引入一个 中间对象(共享资源) 来,将生产者、消费者中需要对外输出或者从外数据的操作封装到中间对象中,这样,消费者和生产者将会持有这个中间对象的引用,屏蔽了生产者和消费者直接的数据交互.,大大见减小生产者和消费者之间的依赖程度。
关于高耦合和低耦合的区别,电脑中主机中的集成显卡和独立显卡也是一个非常好的例子。
- 集成显卡 普遍都集成于 cpu 中,所以如果集成显卡出现了问题需要更换,那么会连着CPU一块更换,其维护成本与CPU其实是一样的;
- 独立显卡 需要插在主板的 显卡接口 上才能与计算机通信,其相对于整个计算机系统来说,是独立的存在,即便出现问题需要更换,也只更换显卡即可。
案例的代码实现
接下来我们使用多线程技术实现该案例,案例代码如下:
蔬菜基地对象,VegetableBase.java
// VegetableBase.java
// 蔬菜基地
public class VegetableBase implements Runnable {
// 超市实例
private Supermarket supermarket = null;
public VegetableBase(Supermarket supermarket) {
this.supermarket = supermarket;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if (i % 2 == 0) {
supermarket.push("黄瓜", 1300);
System.out.println("push : 黄瓜 " + 1300);
} else {
supermarket.push("青菜", 1400);
System.out.println("push : 青菜 " + 1400);
}
}
}
}
消费者对象,Consumer.java
// Consumer.java
// 消费者
public class Consumer implements Runnable {
// 超市实例
private Supermarket supermarket = null;
public Consumer(Supermarket supermarket) {
this.supermarket = supermarket;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
supermarket.popup();
}
}
} 超市对象,Supermarket. Java
// Supermarket.java
// 超市
public class Supermarket {
// 蔬菜名称
private String name;
// 蔬菜数量
private Integer num;
// 蔬菜基地想超市输送蔬菜
public void push(String name, Integer num) {
this.name = name;
this.num = num;
}
// 用户从超市中购买蔬菜
public void popup() {
// 为了让效果更明显,在这里模拟网络延迟
try {
Thread.sleep(1000);
} catch (Interrupted Exception e) {
}
System.out.println("蔬菜:" + this.name + ", " + this.num + "颗。");
}
} 运行案例,App. java
// 案例应用入口
public class App {
public static void main(String[] args) {
// 创建超市实例
Supermarket supermarket = new Supermarket();
// 蔬菜基地线程启动, 开始往超市输送蔬菜
new Thread(new VegetableBase(supermarket)).start();
new Thread(new VegetableBase(supermarket)).start();
// 消费者线程启动,消费者开始购买蔬菜
new Thread(new Consumer(supermarket)).start();
new Thread(new Consumer(supermarket)).start();
}
} 发现了问题
运行该案例,打印出运行结果,外表一片祥和,可还是被敏锐地发现了问题,问题如下所示:

案例运行中发现的问题
在一片看似祥和的打印结果中,出现了一个很不祥和的特例,生产基地在输送蔬菜时,黄瓜的数量一直都是1300颗,青菜的数量一直是1400颗,但是在消费者消费时却出现了 蔬菜名称是黄瓜的,但数量却是青菜的数量 的情况。
之所以出现这样的问题,是因为在本案例共享的资源中,多个线程共同竞争资源时没有使用 同步操作 ,而是异步操作,今儿导致了资源分配紊乱的情况;
需要注意的是, 并不是因为我们在案例中使用Thread.sleep();模拟网络延迟才导致问题出现,而是本来就存在问题,使用Thread.sleep();只是让问题更加明显。
案例问题的解决
在本案例中需要 解决的问题有两个 ,分别如下:
- 问题一: 蔬菜名称和数量不匹配的问题。
- 问题二: 需要保证超市无货时生产,超市有货时才消费。
针对 问题一解决方案 :保证蔬菜基地在输送蔬菜的过程保持同步,中间不能被其他线程(特别是消费者线程)干扰,打乱输送操作;直至当前线程完成输送后,其他线程才能进入操作,同样的,当有线程进入操作后,其他线程只能在操作外等待。
所以, 技术方案 可以使用 同步代码块/同步方法/ Lock 机制 来保持操作的同步性。
针对 问题二的解决方案 :
- 给超市一个有无货的状态标志,超市无货时,蔬菜基地输送蔬菜补货,此时生产基地线程可操作;
- 超市有货时,消费者线程可操作;就是:保证生产基地 ——> 共享资源 ——> 消费者这个整个流程的完整运行。
技术方案 :使用线程中的 等待和唤醒机制 。
同步操作, 分为 同步代码块 和 同步方法 两种。详情可查看我的另外一篇关于多线程的文章: Java 线程不安全分析,同步锁和Lock机制,哪个解决方案更好
- 在同步代码块中的 同步锁 必须选择 多个线程共同的资源对象 ,当前生产者线程在生产数据的时候(先 拥有同步锁 ),其他线程就在锁池中等待获取锁;当生产者线程执行完同步代码块的时候,就会 释放同步锁 ,其他线程开始抢锁的使用权,抢到后就会拥有该同步锁,执行完成后释放,其他线程再开始抢锁的使用权,依次往复执行。
- 多个线程只有使用 同一个对象 (就好比案例中的共享资源对象)的时候,多线程之间才有互斥效果,我们把这个 用来做互斥的对象称之为同步监听对象, 又称 同步监听器、互斥锁、同步锁 ,同步锁是一个抽象概念,可以理解为在对象上标记了一把锁。
- 同步锁对象可以选择 任意类型的对象 即可,只需要保证多个线程使用的是相同锁对象即可。 在任何时候,最多只能运行一个线程拥有同步锁 。因为只有同步监听锁对象才能调用wait和notify方法,wait和notify方法存在于Object类中。
线程通信之 wait和notify方法
在 java.lang .Object类 中提供了用于操作线程通信的方法,详情如下:
- wait(): 执行该方法的线程对象会释放同步锁,然后 JVM 把该线程存放到 等待池 中,等待着其他线程来唤醒该线程;
- notify(): 执行该方法的线程会 唤醒 在等待池中处于等待状态的的 任意一个线程 ,把线程转到 同步锁池 中等待;
- notifyAll(): 执行该方法的线程会 唤醒 在等待池中 处于等待状态的所有的线程 ,把这些线程转到 同步锁池 中等待;
注意:上述方法只能被 同步监听锁对象 来调用,否则发生 IllegalMonitor State Exception 。
wait和notify方法应用实例
假设 A线程 和 B线程 共同操作一个 X对象(同步锁) ,A、B线程可以通过X对象的wait和notify方法来进行通信,流程如下:
- 当A线程执行X对象的同步方法时,A线程持有X对象的锁,B线程没有执行机会,此时的B线程会在X对象的锁池中等待;
- 当A线程在同步方法中执行X.wait()方法时,A线程会释放X对象的同步锁,然后进入X对象的等待池中;
- 接着,在X对象的锁池中等待锁的B线程获取X对象的锁,执行X的另一个同步方法;
- 当B线程在同步方法中执行X.notify()方法时,JVM会把A线程从X对象的等待池中转到X对象的同步锁池中,等待获取锁的使用权;
- 当B线程执行完同步方法后,会释放拥有的锁,然后A线程获得锁,继续执行同步方法;
基于上述机制,我们就可以使用 同步操作 + wait和notify方法 来解决案例中的问题了,重新来实现共享资源——超市对象:
// 超市
public class Supermarket {
// 蔬菜名称
private String name;
// 蔬菜数量
private Integer num;
// 超市是否为空
private Boolean isEmpty = true;
// 蔬菜基地向超市输送蔬菜
public synchronized void push(String name, Integer num) {
try {
// 超市有货时,不再输送蔬菜,而是要等待消费者获取
while (!isEmpty) {
this.wait();
}
this.name = name;
this.num = num;
isEmpty = false;
this.notify(); // 唤醒另一个线程
} catch (Exception e) {
}
}
// 用户从超市中购买蔬菜
public synchronized void popup() {
try {
// 超市无货时,不再提供消费,而是要等待蔬菜基地输送
while (isEmpty) {
this.wait();
}
// 为了让效果更明显,在这里模拟网络延迟
Thread.sleep(1000);
System.out.println("蔬菜:" + this.name + ", " + this.num + "颗。");
isEmpty = true;
this.notify(); // 唤醒另一线程
} catch (Exception e) {
}
}
} 线程通信之 使用Lock和Condition接口
由于wait和notify方法,只能被同步监听锁对象来调用,否则发生 IllegalMonitorStateException。从Java 5开始,提供了 Lock机制 ,同时还有 处理Lock机制的通信控制的Condition接口 。Lock机制没有同步锁的概念,也就 没有自动获取锁和自动释放锁 的这样的操作了。
因为没有同步锁,所以Lock机制中的线程通信就不能调用wait和notify方法了;同样的,Java 5 中也提供了解决方案,因此从Java5开始,可以:
- 使用 Lock机制 取代 synchronized 代码块 和 synchronized 方法 ;
- 使用Condition接口对象的 await、signal、signalAll 方法取代Object类中的 wait、notify、notifyAll 方法;
Lock和Condition接口 的性能也比同步操作要高很多,所以这种方式也是我们推荐使用的方式。
我们可以使用 Lock机制和Condition接口 方法来解决案例中的问题,重新来实现的共享资源——超市对象,代码如下:
// 超市
public class Supermarket {
// 蔬菜名称
private String name;
// 蔬菜数量
private Integer num;
// 超市是否为空
private Boolean isEmpty = true;
// lock
private final Lock lock = new ReentrantLock();
// Condition
private Condition condition = lock.newCondition();
// 蔬菜基地向超市输送蔬菜
public synchronized void push(String name, Integer num) {
lock.lock(); // 获取锁
try {
// 超市有货时,不再输送蔬菜,而是要等待消费者获取
while (!isEmpty) {
condition.await();
}
this.name = name;
this.num = num;
isEmpty = false;
condition.signalAll();
} catch (Exception e) {
} finally {
lock.unlock(); // 释放锁
}
}
// 用户从超市中购买蔬菜
public synchronized void popup() {
lock.lock();
try {
// 超市无货时,不再提供消费,而是要等待蔬菜基地输送
while (isEmpty) {
condition.await();
}
// 为了让效果更明显,在这里模拟网络延迟
Thread.sleep(1000);
System.out.println("蔬菜:" + this.name + ", " + this.num + "颗。");
isEmpty = true;
condition.signalAll();
} catch (Exception e) {
} finally {
lock.unlock();
}
}
}
二.线上问题定位
背景
大家都知道,在服务/应用发布到预览或者线上环境时,经常会出现一些测试中没有出现的问题。并且由于环境所限,我们也不可能在线上调试代码,所以只能通过日志、系统信息和dump等手段来在线上定位问题。
通常需要借助一些工具,例如 jdk 本身提供的一些jmap,jstack等等,或者是 阿里 提供的比较强大的Arthus,另外就是最基础的一些命令。根据经验,系统上发生的主要问题是在cpu、内存、磁盘几个方面,因此会优先针对这类问题进行定位。由于绝大部分服务都是部署在 Linux 环境下,所以一下以 Linux命令 为例进行说明。
top命令
top命令可以用于查询每个进程的情况,显示信息如下:
如上面内容所示,需要注意一下各列的含义,这里再重复一遍,如下表所示:
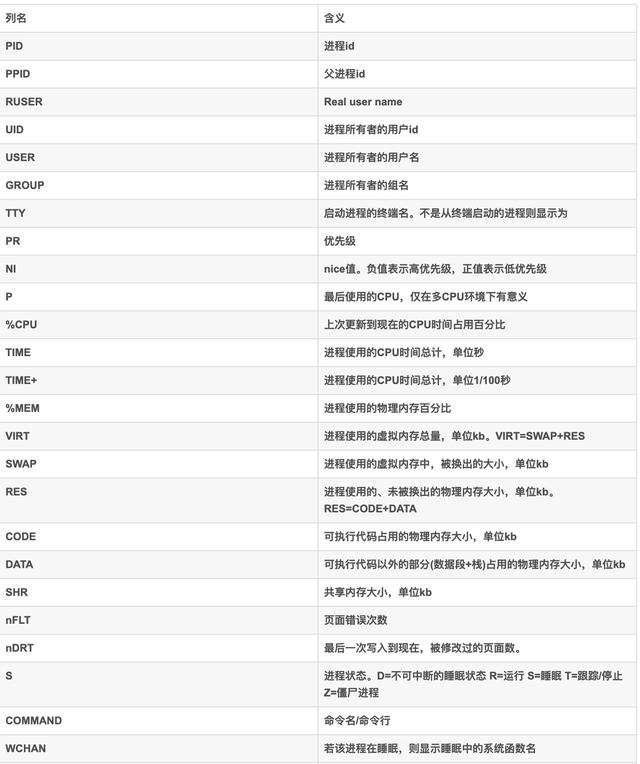
由于限定我们的应用是Java应用,所以只需要关注COMMOND列是java的进程信息。
有时候%CPU这列的数字可能会超过100%,这不一定是出了问题,因为是机器所有核加在一起的CPU利用率,所以我们需要计算一下,平均每个核上的利用比例,再来确定是否是CPU使用过高,进而再去分析是否发生了死循环、内存回收等问题的可能。
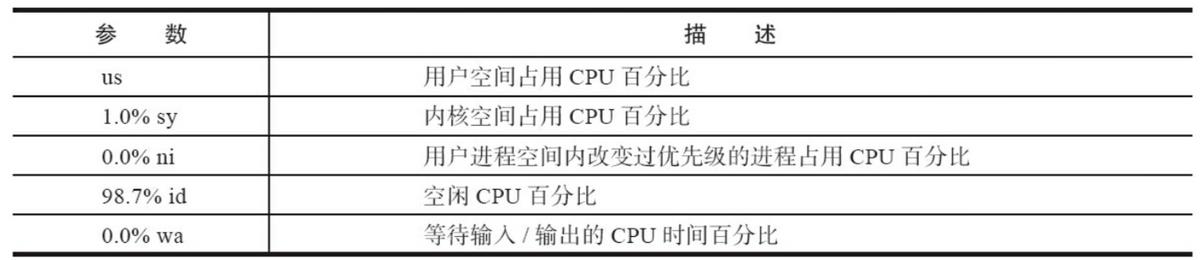
在top命令出来的界面下,输入1(top的交互命令数字),可以查看每个CPU的性能信息:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5875 qkadmin 20 0 163144 3324 1612 R 1.0 0.0 0:00.24 top
1498 root 20 0 3243684 665836 14684 S 0.3 4.1 39:27.18 java 27412 root 20 0 3243684 665836 14684 S 0.3 4.1 15:14.25 java
4982 root 20 0 6715536 129904 13368 S 0.3 0.8 198:59.46 java
8287 root 20 0 1003108 118728 18812 S 0.3 0.7 688:11.51 node /opt/my-ya 10289 root 20 0 3089652 673520 15880 S 0.3 4.1 30:15.15 java 12261 root 20 0 803192 10800 4592 S 0.3 0.1 10:05.35 aliyun-service 12263 root 20 0 803192 10800 4592 S 0.3 0.1 5:45.73 aliyun-service 14351 root 20 0 2998424 556848 14548 S 0.3 3.4 1:14.78 java
以上是我们某台机器上的实时数据,因为当前运行正常,所以没有异常数据。但看一下下面的数据:

命令行显示了5个CPU,说明是一个5核的机器,平均每个CPU利用率在60%以上。有时可能存在CPU利用率达到100%,如果出现这种情况,那么很有可能是代码中写了死循环,继续看代码定位问题原因。
CPU参数的含义如下:
交互命令H,可以查看每个线程的性能信息:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5875 qkadmin 20 0 163144 3324 1612 R 1.0 0.0 0:00.24 top
1498 root 20 0 3243684 665836 14684 S 0.3 4.1 39:27.18 java 27412 root 20 0 3243684 665836 14684 S 0.3 4.1 15:14.25 java
4982 root 20 0 6715536 129904 13368 S 0.3 0.8 198:59.46 java
8287 root 20 0 1003108 118728 18812 S 0.3 0.7 688:11.51 node /opt/my-ya 10289 root 20 0 3089652 673520 15880 S 0.3 4.1 30:15.15 java 12261 root 20 0 803192 10800 4592 S 0.3 0.1 10:05.35 aliyun-service 12263 root 20 0 803192 10800 4592 S 0.3 0.1 5:45.73 aliyun-service 14351 root 20 0 2998424 556848 14548 S 0.3 3.4 1:14.78 java
可能发生的几个问题和对应的现象有:
1、某个线程,CPU利用率一直在100%左右,那么说明这个线程很有可能出现死循环,记住这个PID,并进一步定位具体应用;另外也可能是出现内存泄漏,触发频繁GC导致。这种情况,可以使用jstat命令查看GC情况,以分析是否持久代或老年代内存区域满导致触发Full GC,进而使CPU利用率飙高,命令和显示信息如下(81443是当前机器上观察的进程id):
jstat -gcutil 81443 1000 5
信息:
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 53.94 78.77 0.05 97.26 93.39 1 0.006 0 0.000 0.006
0.00 53.94 78.77 0.05 97.26 93.39 1 0.006 0 0.000 0.006
0.00 53.94 78.77 0.05 97.26 93.39 1 0.006 0 0.000 0.006
0.00 53.94 78.77 0.05 97.26 93.39 1 0.006 0 0.000 0.006
0.00 53.94 78.77 0.05 97.26 93.39 1 0.006 0 0.000 0.006
dump
下一步,可以把线程dump下来,然后再继续分析是哪个线程、执行到那段代码导致CPU利用率飙高。使用命令可以参考如下:
jstack 81443 > ./dump01
dump文件内容:
192:dubbo-proxy-tools xxx$ cat dump01 2021-02-13 22:51:08
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.212-b10 mixed mode):
“Attach Listener” #14 daemon prio=9 os_prio=31 tid=0x00007f8cef903000 nid=0x1527 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
“DestroyJavaVM” #12 prio=5 os_prio=31 tid=0x00007f8cef91d000 nid=0x2803 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
“JPS event loop” #10 prio=5 os_prio=31 tid=0x00007f8cf1153800 nid=0xa703 runnable [0x0000700003656000]
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.KQueueArrayWrapper.kevent0(Native Method)
at sun.nio.ch.KQueueArrayWrapper.poll(KQueueArrayWrapper.java:198)
at sun.nio.ch.KQueueSelectorImpl.doSelect(KQueueSelectorImpl.java:117)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)
– locked <0x00000007b5700798> (a io.netty.channel.nio.SelectedSelectionKeySet)
– locked <0x00000007b57007b0> (a java.util.Collections$UnmodifiableSet)
– locked <0x00000007b5700748> (a sun.nio.ch.KQueueSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)
at io.netty.channel.nio.SelectedSelectionKeySetSelector.select(SelectedSelectionKeySetSelector.java:62)
at io.netty.channel.nio.NioEventLoop.select(NioEventLoop.java:753)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:408)
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:897)
at java.lang.Thread.run(Thread.java:748)
“Service Thread” #9 daemon prio=9 os_prio=31 tid=0x00007f8cf3822800 nid=0x5503 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
“C1 CompilerThread3” #8 daemon prio=9 os_prio=31 tid=0x00007f8cf1802800 nid=0x3a03 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
“C2 CompilerThread2” #7 daemon prio=9 os_prio=31 tid=0x00007f8cf480c000 nid=0x3c03 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
线程id (nid=0x2803) 是16进制,可与转成10进制,来跟top命令观察的id对应(可以简单地使用 printf “%xn” 0x5503即可):
192:dubbo-proxy-tools xxxx$ printf “%xn” 0x55035503
2、某个线程一直在top 10的位置,那么说明该线程可能有性能问题
3、CPU利用率高的线程不断变化,说明不是某一个线程导致的CPU利用率飙高
三. 性能测试
测试并发程序而言,所面临的主要挑战在于:潜在的错误发生具有不确定性,需要比普通的串行程序测试更广的范围并且执行更长的时间。
并发测试大致分为两类:安全性测试和活跃性测试。
安全测试 —– 通常采用测试不变性条件的形式,即判断某个类的行为是否与其他规范保持一致。
活跃性测试 —– 包括进展测试和无进展测试两个方面(很难量化)。
性能测试—– 性能测试与活跃性测试相关,主要通过:吞吐量、响应性、可伸缩性衡量。
正确性测试
测试并发类设计单元测试时,首先要执行与测试串行类时相同的分析—-找出需要检查的不变性条件与后验条件。(不变性条件:判断状态是有效还是无效,后验条件:判断状态改变后是否有效)。接下来讲通过构建一个基于Semaphore来实现的缓存的有界缓存,测试缓存的正确性。
基本单元测试(基于信号量有界缓存BoundedBuffer例子)
知识铺垫(Semaphore可以控制同时访问资源的线程个数,例如,实现一个文件允许的并发访问数。单个信号量的Semaphore对象可以实现互斥锁的功能,并且可以是由一个线程获得了“锁”,再由另一个线程释放“锁”)
BoundedBuffer 用一个泛型数组、Semaphore 实现了一个固定长度的、可以缓存队列可删除可插入个数的队列。availableItems表示可以从缓存中删除的元素个数。availableSpaces表示可以插入到缓存的元素个数,初始值等于缓存的大小。分析:
availableItems 设置为0,要求任何线程在accquire之前要release保证了队列必须插入有值才能take
availableSpaces 初始值为大小为capacity,表明队列最大值为capacity,同时也表明一开始最多有capacity个线程可以同时put队列,当然随着队列插入可同时插入的线程变少。
在最关键的插入、取出队列的操作中,采用synchronized 包装两个方法,保证了同步性。
说明:在实际使用中,肯定不可能自己编写一个有界缓存,但是此例实现的思路值得学习。如果实际需要使用有界缓存,应该直接使用ArrayBlockingQueue或者LinkedBlockingQueue。
public class BoundedBuffer<E> {
//可用信号量、空间信号量
private final Semaphore availableItems, availableSpaces;
private final E[] items;//缓存
private int putPosition = 0, takePosition = 0;//放、取索引位置
public BoundedBuffer(int capacity) {
availableItems = new Semaphore(0);//初始时没有可用的元素
availableSpaces = new Semaphore(capacity);//初始时空间信号量为最大容量
items = (E[]) new Object[capacity];
}
public boolean isEmpty() {
//如果可用信号量为0,则表示缓存为空
return availableItems.availablePermits() == 0;
}
public boolean isFull() {
//如果空间信号量为0,表示缓存已满
return availableSpaces.availablePermits() == 0;
}
public void put(E x) throws InterruptedException {
availableSpaces.acquire();//阻塞获取空间信号量
doInsert(x);
availableItems.release();//可用信号量加1
}
public E take() throws InterruptedException {
availableItems.acquire();
E item = doExtract();
availableSpaces.release();
return item;
}
private synchronized void doInsert(E x) {
int i = putPosition;
items[i] = x;
putPosition = (++i == items.length) ? 0 : i;
}
private synchronized E doExtract() {
int i = takePosition;
E x = items[i];
items[i] = null;//加快垃圾回收
takePosition = (++i == items.length) ? 0 : i;
return x;
}
} 先进行基本的单元测试:该基本的单元测试相当于串行上下文中执行的测试,测试了BoundedBuffer的所有方法,间接验证其后验条件和不变性条件。
public class BoundedBufferTest extends TestCase {
//刚构造好的缓存是否为空测试
public void testIsEmptyWhenConstructed() {
BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
assertTrue(bb.isEmpty());
assertFalse(bb.isFull());
}
//测试是否满
public void testIsFullAfterPuts() throws InterruptedException {
BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
for (int i = 0; i < 10; i++)
bb.put(i);
assertTrue(bb.isFull());
assertFalse(bb.isEmpty());
} 对阻塞行为与对中断响应的测试
在测试并发的基本属性时,需要引入多个线程。大多数测试框架并不能很好的支持并发性测试, 测试阻塞行为,当然线程被阻塞不再执行时,阻塞才是成功的,为了让阻塞行为效果更明显,可以在阻塞方法中抛出异常。
当阻塞发生后,要使方法解除阻塞最简单的方式是采用中断,可以在阻塞方法发生后,线程阻塞后再中断它,当然这要求阻塞方法提取返回或者抛出InterrupedException来响应中断。
例如BoundedBuffer的阻塞行为以及对中断的响应性测试,如果从空缓存中获取一个元素,如果take方法成功,表明测试失败。在等待“获取”一段时间后,再中断该线程,如果线程在调用Object类的wait()、 join() 或者sleep()方法被强行中断,那么将会抛出InterruptedException。
public class TestBoundedBufferBlock extends TestCase {
public void testTakeBlocksWhenEmpty() {
final BoundedBuffer<Integer> bb = new BoundedBuffer<Integer>(10);
Thread taker = new Thread() {
public void run() {
try {
int unused = bb.take();
System.out.println("由于阻塞,将不会输出此句");
fail(); // 如果运行到这里,就说明有错误,fail会抛出异常
} catch (InterruptedException success) {
success.printStackTrace();
}
}
};
try {
taker.start();
Thread.sleep(100);
// taker.interrupt();//中断阻塞线程
taker.join(1000);//等待阻塞线程完成
assertFalse(taker.isAlive());//断言阻塞线程已终止
} catch (Exception unexpected) {
fail();
}
}
public static void main(String[] args) {
TestBoundedBufferBlock boundedBufferTest = new TestBoundedBufferBlock();
boundedBufferTest.testTakeBlocksWhenEmpty();
}
} 可进行interrupt强行中断,将抛出异常InterrupedException。

以下结果是,执行线程执行join()方法,设置等待该线程最长时间为1秒,最后断言线程已中止。

安全性测试(测试BoundedBuffer生产者—消费者)
安全性测试即测试是否会发生数据竞争从而引发错误,测试类似BoundedBuffer生产者—消费者模式的类,需要创建多个线程来分别执行put和take操作。
为了尽可能达到多个线程并行执行,避免线程交替执行达不到预期的结果,可采用CountDownLatch或者CyclicBarrier。若采用两个CountDownLatch,其中一个作为开启阀门,另一个作为结束阀门。若采用CyclicBarrier相对简单。(CyclicBarrier初始化时规定一个数目,然后计算调用了CyclicBarrier.await()进入等待的线程数。当线程数达到了这个数目时,所有进入等待状态的线程被唤醒并继续。 )
分析:
PutTakeTest开启了10对生产—消费者线程,初始化CyclicBarrier时将计数值指定为工作者总线程的数量再加1,并在运行开始和结束时,使工作者线程和测试线程都在这个栅栏处等待。这能确保所有线程在开始执行任何工作之前,都首先执行到同一位置。
通过一个对顺序敏感的校验和计算函数来计算所有入列元素以及出列元素的校验和,并进行比较。如果两者相等,程序最终没有报错,则测试就是成功的。事实上也确实没有报错。
public class PutTakeTest extends TestCase {
protected static final ExecutorService pool = Executors
.newCachedThreadPool();
protected CyclicBarrier barrier;//为了尽量做到真正并发,使用屏障
protected final BoundedBuffer<Integer> bb;
protected final int nTrials, nPairs;//元素个数、生产与消费线程数
protected final AtomicInteger putSum = new AtomicInteger(0);//放入元素检验和
protected final AtomicInteger takeSum = new AtomicInteger(0);//取出元素检验和
public static void main(String[] args) throws Exception {
new PutTakeTest(10, 10, 100000).test(); // sample parameters
pool.shutdown();
}
public PutTakeTest(int capacity, int npairs, int ntrials) {
this.bb = new BoundedBuffer<Integer>(capacity);
this.nTrials = ntrials;
this.nPairs = npairs;
this.barrier = new CyclicBarrier(npairs * 2 + 1);
}
void test() {
try {
for (int i = 0; i < nPairs; i++) {
pool.execute(new Producer());//提交生产任务
pool.execute(new Consumer());//提交消费任务
}
barrier.await(); // 等待所有线程都准备好
barrier.await(); // 等待所有线程完成,即所有线程都执行到这里时才能往下执行
assertEquals(putSum.get(), takeSum.get());//如果不等,则会抛异常
} catch (Exception e) {
throw new RuntimeException(e);
}
}
class Producer implements Runnable {
public void run() {
try {
//等待所有生产-消费线程、还有主线程都准备好后才可以往后执行
barrier.await();
// 种子,即起始值
int seed = (this.hashCode() ^ (int) System.nanoTime());
int sum = 0;//线程内部检验和
for (int i = nTrials; i > 0; --i) {
bb.put(seed);//入队
/*
* 累计放入检验和,为了不影响原程序,这里不要直接使用全局的
* putSum来累计,而是等每个线程试验完后再将内部统计的结果一
* 次性存入
*/
sum += seed;
seed = xorShift(seed);//根据种子随机产生下一个将要放入的元素
}
//试验完成后将每个线程的内部检验和再次累计到全局检验和
putSum.getAndAdd(sum);
//等待所有生产-消费线程、还有主线程都完成后才可以往后执行
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
class Consumer implements Runnable {
public void run() {
try {
//等待所有生产-消费线程、还有主线程都准备好后才可以往后执行
barrier.await();
int sum = 0;
for (int i = nTrials; i > 0; --i) {
sum += bb.take();
}
takeSum.getAndAdd(sum);
//等待所有生产-消费线程、还有主线程都完成后才可以往后执行
barrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
/*
* 测试时尽量不是使用类库中的随机函数,大多数的随机数生成器都是线程安全的,
* 使用它们可能会影响原本的性能测试。在这里我们也不必要使用高先是的随机性。
* 所以使用简单而快的随机算法在这里是必要的。
*/
static int xorShift(int y) {
y ^= (y << 6);
y ^= (y >>> 21);
y ^= (y << 7);
return y;
}
} 资源管理测试(测试资源泄露)
书中原文,通过一些测量应用程序中内存使用情况的堆检查工具,可以很容易地测试出对内存的不合理占用,许多商用和开源的堆分析工具中都支持这种功能。下面程序的testLeak方法中包含了一些堆分析工具用于抓取堆的快照,这将强制执行一次垃圾回收,然后记录堆大小和内存使用量信息。
testLeak方法将多个大型对象插入到一个有界缓存中,然后将它们移除。第2个堆快照中的内存用量应该与第1个堆快照中的内存用量基本相同。然而,doExtract如果忘记将返回元素的引用置为空(items[i] = null),那么在两次快照中报告的内存用量将明显不同。(这是为数不多几种需要显式地将变量置空的情况之一。大多数情况下,这种做法不仅不会带来帮助,甚至还会带来负面作用。)
功力不足,并不能看出垃圾回收中堆是如何变化的。待补充
//大对象
class Big {
double[] data = new double[100000]; }void testLeak() throws InterruptedException {
BoundedBuffer<Big> bb = new BoundedBuffer<Big>(CAPACITY);
//使用前堆大小快照,这里可以调用第三方堆追踪(heap-profiling)工具来记录。堆追踪工具会强制进行垃圾回收,然后记录下堆大小和内存用量信息
int heapSize1 = /* snapshot heap */ ;
for (int i = 0; i < CAPACITY; i++)
bb.put(new Big());
for (int i = 0; i < CAPACITY; i++)
bb.take();
int heapSize2 = /* snapshot heap */ ;
assertTrue(Math.abs(heapSize1-heapSize2) < THRESHOLD);}
使用回调
在构造测试案例时,对客户提供的代码进行回调是非常有帮助的。回调函数的执行通常是在对象生命周期的一些已知位置上,并且在这些位置上非常适合判断不变性条件是否被破坏。例如,在ThreadPoolExecutor中将调用任务的Runnable和ThreadFactory。
通过使用自定义的线程工厂,可以对线程的创建过程进行控制。下面程序TestingThreadFactory中将记录已创建线程的数量。这样,在测试过程中,测试方案可以验证已创建线程的数量。 我们还可以对TestingThreadFactory进行扩展,使其返回一个自定义的Thread,并且该对象可以记录自己在何时结束,从而在测试方案中验证线程在被回收时是否与执行策略一致。
class TestingThreadFactory implements ThreadFactory {
public final AtomicInteger numCreated = new AtomicInteger();//记录已创建的工作线程数
private final ThreadFactory factory
= Executors.defaultThreadFactory();
public Thread newThread(Runnable r) {
//Executor框架在创建工作线程时回调此方法
numCreated.incrementAndGet();
return factory.newThread(r);
}
} 如果线程池的基本大小小于最大大小,那么线程池会根据执行需求相应增长。当把一些运行时间较长的任务提交给线程池时,线程池中的任务数量在长时间内都不会变化,这就可以进行一些判断,例如测试线程池是否能按照预期的方式扩展,如下程序:
public class TestThreadPool extends TestCase {
private final TestingThreadFactory threadFactory = new TestingThreadFactory();
public void testPoolExpansion() throws InterruptedException {
int MAX_SIZE = 10;
ExecutorService exec = Executors.newFixedThreadPool(MAX_SIZE);
for (int i = 0; i < 10 * MAX_SIZE; i++)
exec.execute(new Runnable() {
public void run() {
try {
Thread.sleep(Long.MAX_VALUE);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
for (int i = 0;
i < 20 && threadFactory.numCreated.get() < MAX_SIZE;
i++)
Thread.sleep(100);
assertEquals(threadFactory.numCreated.get(), MAX_SIZE);
exec.shutdownNow();
}
} 使用Thread.yield产生更多的交替操作
由于并发代码中的大多数错误都是一些低概率事件,因此在测试并发错误时需要反复地执行许多次,但有些方法可以提高发现这些错误的概率。有一种有用的方法可以提高交替操作的数量,以便能有效地搜索程序的状态空间:在访问共享状态的操作中,使用Thread.yield将产生更多的上下文切换。(这项技术的有效性与具体的平台相关,因为JVM可以将Thread.yield作用一个空操作。如果使用一个睡眠时间较短的sleep,那么虽然慢些,但却更可靠。)
下面程序中的方法在两个账户之间执行转账操作,在两次更新操作之间,像”所有账户的总和应等于零“这样的一些不变性条件可能会被破坏。当代码在访问状态时没有使用足够的同步,将存在一些对执行时序敏感的错误,通过在某个操作的执行过程中调用yield方法,可以将这些错误暴露出来。这种方法需要在测试中添加一些调用并且在正式产品中删除这些调用,这将给开发人员带来不便,通过使用面向方面编程(AOP)的工具,可以降低这种不便性。
使用Thread.yield,让线程从Thread.yield调用点切换到另一线程,有助于发现Bug,该方法只适合用于测试环境中 。下面使用该方法在取出与存入间切换到另一线程:
public synchronized void transferCredits(Account from, Account to,int amount){
from.setBalance(from.getBalance()-amount);
if(random.nextInt(1000)>THRESHOLD)
Thread.yield();//切换到另一线程
to.setBalance(to.getBalance()+amount);
}
性能测试
使用CyclicBarrier测量并发执行时间与吞吐率
以上面的PutTakeTest,给它加上时间测量特性。测试性能时的时间最好取多个线程的平均消耗时间,这样会精确一些。在PutTakeTest中我们已经使用了CyclicBarrier去同时启动和结束工作者线程了,所以我们只要使用一个关卡动作(在所有线程都达关卡点后开始执行的动作)来记录启动和结束时间,就完成了对并发执行时间的测试。下面是扩展后的PutTakeTest,:
public class TimedPutTakeTest extends PutTakeTest {
private BarrierTimer timer = new BarrierTimer();
public TimedPutTakeTest(int cap, int pairs, int trials) {
super(cap, pairs, trials);
barrier = new CyclicBarrier(nPairs * 2 + 1, timer);
}
public void test() {
try {
timer.clear();
for (int i = 0; i < nPairs; i++) {
pool.execute(new PutTakeTest.Producer());
pool.execute(new PutTakeTest.Consumer());
}
barrier.await();//等待所有线程都准备好后开始往下执行
barrier.await();//等待所有线都执行完后开始往下执行
//每个元素完成处理所需要的时间
long nsPerItem = timer.getTime() / (nPairs * (long) nTrials);
System.out.print("Throughput: " + nsPerItem + " ns/item");
assertEquals(putSum.get(), takeSum.get());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static void main(String[] args) throws Exception {
int tpt = 100000; // 每对线程(生产-消费)需处理的元素个数
//测试缓存容量分别为1、10、100、1000的情况
for (int cap = 1; cap <= 1000; cap *= 10) {
System.out.println("Capacity: " + cap);
//测试工作线程数1、2、4、8、16、32、64、128的情况
for (int pairs = 1; pairs <= 128; pairs *= 2) {
TimedPutTakeTest t = new TimedPutTakeTest(cap, pairs, tpt);
System.out.print("Pairs: " + pairs + "t");
//测试两次
t.test();//第一次
System.out.print("t");
Thread.sleep(1000);
t.test();//第二次
System.out.println();
Thread.sleep(1000);
}
}
PutTakeTest.pool.shutdown();
}
//关卡动作,在最后一个线程达到后执行。在该测试中会执行两次:
//一次是执行任务前,二是所有任务都执行完后
static class BarrierTimer implements Runnable {
private boolean started;//是否是第一次执行关卡活动
private long startTime, endTime;
public synchronized void run() {
long t = System.nanoTime();
if (!started) {
//第一次关卡活动走该分支
started = true;
startTime = t;
} else
//第二次关卡活动走该分支
endTime = t;
}
public synchronized void clear() {
started = false;
}
public synchronized long getTime() {
//任务所耗时间
return endTime - startTime;
}
}
} 运行结果:
Capacity: 1
Pairs: 1 Throughput: 9440 ns/item Throughput: 9308 ns/item
Pairs: 2 Throughput: 12159 ns/item Throughput: 12111 ns/item
Pairs: 4 Throughput: 12198 ns/item Throughput: 12234 ns/item
Pairs: 8 Throughput: 13001 ns/item Throughput: 13432 ns/item
Pairs: 16 Throughput: 12672 ns/item Throughput: 12930 ns/item
Pairs: 32 Throughput: 12409 ns/item Throughput: 14012 ns/item
Pairs: 64 Throughput: 12551 ns/item Throughput: 12619 ns/item
Pairs: 128 Throughput: 11897 ns/item Throughput: 11806 ns/item
Capacity: 10
Pairs: 1 Throughput: 1444 ns/item Throughput: 1231 ns/item
Pairs: 2 Throughput: 1190 ns/item Throughput: 1186 ns/item
Pairs: 4 Throughput: 1283 ns/item Throughput: 1283 ns/item
Pairs: 8 Throughput: 1251 ns/item Throughput: 1263 ns/item
Pairs: 16 Throughput: 1227 ns/item Throughput: 1236 ns/item
Pairs: 32 Throughput: 1216 ns/item Throughput: 1221 ns/item
Pairs: 64 Throughput: 1208 ns/item Throughput: 1282 ns/item
Pairs: 128 Throughput: 1265 ns/item Throughput: 1227 ns/item
Capacity: 100
Pairs: 1 Throughput: 519 ns/item Throughput: 473 ns/item
Pairs: 2 Throughput: 374 ns/item Throughput: 370 ns/item
Pairs: 4 Throughput: 302 ns/item Throughput: 289 ns/item
Pairs: 8 Throughput: 286 ns/item Throughput: 286 ns/item
Pairs: 16 Throughput: 306 ns/item Throughput: 311 ns/item
Pairs: 32 Throughput: 310 ns/item Throughput: 316 ns/item
Pairs: 64 Throughput: 322 ns/item Throughput: 321 ns/item
Pairs: 128 Throughput: 324 ns/item Throughput: 323 ns/item
Capacity: 1000
Pairs: 1 Throughput: 393 ns/item Throughput: 484 ns/item
Pairs: 2 Throughput: 267 ns/item Throughput: 315 ns/item
Pairs: 4 Throughput: 192 ns/item Throughput: 278 ns/item
Pairs: 8 Throughput: 277 ns/item Throughput: 212 ns/item
Pairs: 16 Throughput: 218 ns/item Throughput: 226 ns/item
Pairs: 32 Throughput: 214 ns/item Throughput: 242 ns/item
Pairs: 64 Throughput: 245 ns/item Throughput: 251 ns/item
Pairs: 128 Throughput: 261 ns/item Throughput: 260 ns/item
分析:
缓存size为1时,即cap为1时,BoundedBuffer的Capacity为1时,BoundedBuffer中的Semaphore限定了每次只能1个线程访问队列,每个线程在阻塞等待前一个使用有界缓存队列的线程,当缓存提高至10,吞吐量得到了极大的提高,从上面的运行结果也可看出,并发执行时间极大的缩小。但是线程增加时,吞吐率却有所下降,运行时间不见得有很大的降低,原因在于虽然有许多线程,但却没有足够多的计算量,大多数的时间都消耗在线程的阻塞与解除阻塞操作上。图中,吞吐率已归一化,size为缓存大小。
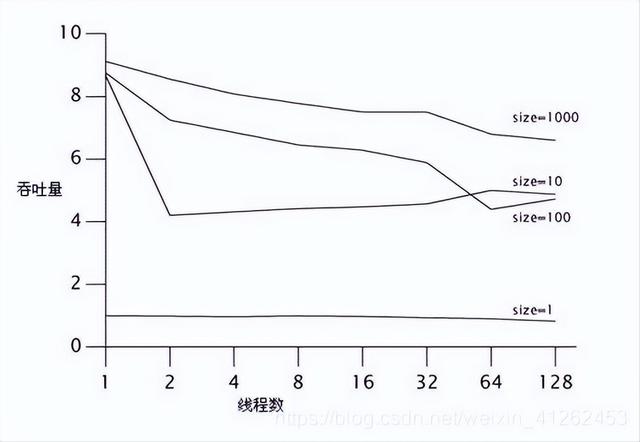
不同缓存队列性能测试比较
虽然上面的BoundedBuffer是一种相当可靠的实现,它的运行机制也非常合理,但是它还不足以和ArrayBlockingQueue 与LinkedBlockingQueue相提并论,这也解释了为什么这种缓存算法没有被选入类库中。并发类库中的算法已经被选择并调整到最佳性能状态了。BoundedBuffer性能不高的主要原因:put和take操作分别都有多个操作可能遇到竞争——获取一个信号量,获取一个锁、释放信号量。
在测试的过程中发现LinkedBlockingQueue的伸缩性好于ArrayBlockingQueue,这主要是因为链表队列的put和take操作允许有比基于数组的队列更好的并发访问,好的链表队列算法允许队列的头和尾彼此独立地更新。由于内存分配操作通常是线程本地的,因此如果算法能通过执行一些内存分配操作来降低竞争程度,那么这种算法通常具有更高的可伸缩性。这种情况再次证明了,基于传统的性能调优直觉与提升可伸缩性的实际需求是背道而驰的。
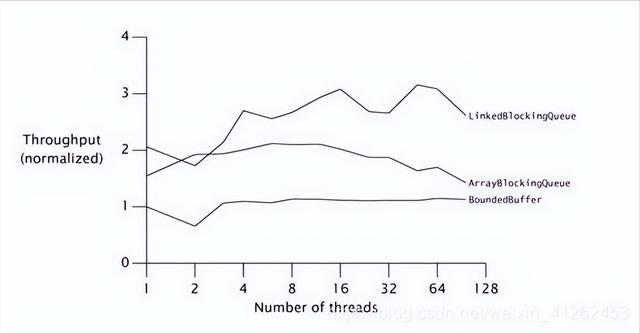
Throughput表示吞吐率
响应性衡量
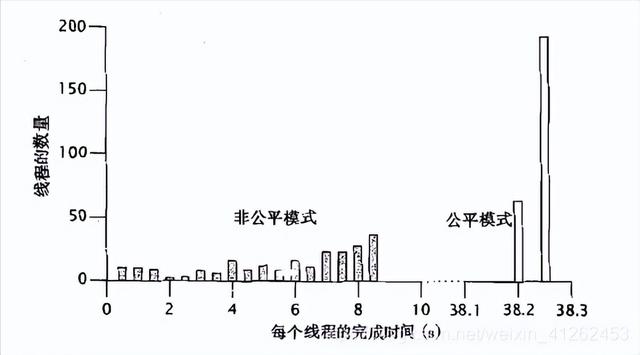
响应性通过任务完成的时间来衡量。除非线程由于密集的同步需求而被持续的阻塞,否则非公平的信号量通常能实现更好的吞吐量,而公平的信号量则实现更低的变动性(公平性开销主要由于线程阻塞所引起)。下图为TimePutTakeTest中使用1000个缓存,256个并发任务中每个任务完成时间,其中每个任务都是用非公平信号量(隐蔽栅栏,Shaded Bars)和公平的信号量(开放栅栏,open bars)来迭代1000个元素,其中非公平信号量完成时间从104毫秒到8714毫米,相差80倍。若采用同步控制实现更高的公平性,能缩小任务完成时间变动范围(变动性),但是会极大的降低吞吐率。
避免性能测试的陷阱
以下的几种编码陷阱是性能测试变得毫无意义。
垃圾回收
垃圾回收的执行时序是无法预测的,可能发生在任何时刻,如果在测试程序时,恰巧触发的垃圾回收操作,那么在最终测试的时间上会带来很大但虚假的影响。
两种策略方式垃圾回收操作对测试结果产生偏差:
一:保证垃圾回收在执行测试程序期间不被执行,可通过调用JVM时指定-verbose:gc查看是否有垃圾回收信息。
二:保证垃圾回收在执行测试程序期间执行多次,可以充分反映出运行期间的内存分配和垃圾回收等开销。
通常而言,第二种更好,更能反映实际环境下的性能。
动态编译
相比静态的编译语言(C或者C++),java动态编译语言的性能基准测试变得困难的多。在JVM中将字节码的解释和动态编译结合起来。当某个类第一次被加载,JVM会通过解释字节码方式执行它,然而某个时刻,如果某个方法运行测试足够多,那么动态编译器会将其编译为机器代码,某个方法的执行方法从解释执行变成直接执行。这种编译的执行实际无法预测,如果编译器可以在测试期间运行,那么将在两个方面给测试结果带来偏差:
一:编译过程消耗CPU资源
二:测量的代码中既包含解释执行代码,又包含编译执行代码,测试结果是混合代码的性能指标没有太大的意义。
解决办法:
一:可以让测试程序运行足够长时间,防止动态编译对测试结果产生的偏差。
二:在HotSpot运行程序时设置-xx:+PrintCompilation,在动态编译时输出一条信息,可以通过这条消息验证动态编译是测试运行前,而不是运行过程中执行
对代码路径的不真实采样
动态编译可能会让不同地方调用的同一方法编译出的代码不同。
测试程序不仅要大致判断某个典型应用程序的使用模式,还要尽量覆盖在该应用程序中将执行的代码路径集合
访问共享数据竞争程度影响吞吐量
并发程序交替执行两种类型的工作:访问共享数据(例如从共享工作队列取出下一个任务)和执行线程本地的计算(例如:执行任务)。如果任务是计算密集型,即任务执行时间较长,那么这种情况下几乎不存在竞争,吞吐量受限于CPU资源可用性。然而,如果任务生命周期较慢,那么在工作队列上存在严重的竞争,吞吐量受限于同步的开销。例如TimePutTakeTest由于消费者没有执行太多工作,吞吐量受限于线程的协调开销。
无用代码的消除
无论是何种语言编写优秀的基准测试程序,一个需要面对的挑战是:优化编译能找出并消除那些对输出结果不会产生任何影响的无用代码。由于基准测试代码通常不会执行任何技术,因此很容易在编译器的优化过程中被消除,因此测试的内容变得更少。在动态编译语言java中,要检测编译器是否消除了测试基准是很困难的。
解决办法,就是告诉优化器不要将基准测试代码当成无用代码而优化掉,这就要求在程序中对每个计算结果都通过某种方法使用,这种方法不需要大量的计算。例如在PutTakeTest中,我们计算了在队列中添加删除了所有元素的校验和,如果在程序中没有用到这个校验和,那么计算校验和操作很有可能被优化掉,但是幸好 assertEquals(putSum.get(), takeSum.get());在程序中使用了校验和来验证算法的正确性。
上诉中要尽量采用某种方法使用计算结果避免被优化掉,有个简单的方法可不会引入过高的开销,将计算结果与System.nanoTime比较,若相等输出一个无用的消息即可。
if(计算结果== System.nanoTime())
System.out.print(” “);
总结
要测试并发程序的正确性可能非常困难,因为并发程序的许多故障模式都是一些低概率事件,它们对于执行时序、负载情况以及其他难以重现的条件都非常敏感。而且,在测试程序中还会引入额外的同步或执行时序限制,这些因素将掩盖被测试代码中的一些并发问题。要测试并发程序的性能同样非常困难,与使用静态编译语言(例如C)编写的程序相比,用Java编写的程序在测试起来更加困难,因为动态编译、垃圾回收以及自动化等操作都会影响与时间相关的测试结果。
要想尽可能地发现潜在的错误以及避免它们在正式产品中暴露出来,我们需要将传统的测试技术(要谨慎地避免在这里讨论的各种陷阱)与代码审查和自动化分析工具结合起来,每项技术都可以找出其他技术忽略的问题。
四. 异步任务池
Java中的线程池设计得非常巧妙,可以高效并发执行多个任务,但是在某些场景下需要对线程池进行扩展才能更好地服务于系统。例如,如果一个任务仍进线程池之后,运行线程池的程序重启了,那么线程池里的任务就会丢失。另外,线程池只能处理本机的任务,在集群环境下不能有效地调度所有机器的任务。所以,需要结合线程池开发一个异步任务处理池。图11-2 为异步任务池设计图。

异步任务池设计图
任务池的主要处理流程是,每台机器会启动一个任务池,每个任务池里有多个线程池,当某台机器将一个任务交给任务池后,任务池会先将这个任务保存到数据中,然后某台机器上的任务池会从数据库中获取待执行的任务,再执行这个任务。
每个任务有几种状态,分别是创建(NEW)、执行中(EXECUTING)、RETRY(重试)、挂起
(SUSPEND)、中止(TEMINER)和执行完成(FINISH)。
- 创建:提交给任务池之后的状态。
- 执行中:任务池从数据库中拿到任务执行时的状态。
- 重试:当执行任务时出现错误,程序显式地告诉任务池这个任务需要重试,并设置下一次
执行时间。
- 挂起:当一个任务的执行依赖于其他任务完成时,可以将这个任务挂起,当收到消息后, 再开始执行。
- 中止:任务执行失败,让任务池停止执行这个任务,并设置错误消息告诉调用端。
- 执行完成:任务执行结束。
任务池的任务隔离 。异步任务有很多种类型,比如抓取网页任务、同步数据任务等,不同类型的任务优先级不一样,但是系统资源是有限的,如果低优先级的任务非常多,高优先级的任务就可能得不到执行,所以必须对任务进行隔离执行。使用不同的线程池处理不同的任务, 或者不同的线程池处理不同优先级的任务,如果任务类型非常少,建议用任务类型来隔离,如果任务类型非常多,比如几十个,建议采用优先级的方式来隔离。
任务池的重试策略 。根据不同的任务类型设置不同的重试策略,有的任务对实时性要求高,那么每次的重试间隔就会非常短,如果对实时性要求不高,可以采用默认的重试策略,重试间隔随着次数的增加,时间不断增长,比如间隔几秒、几分钟到几小时。每个任务类型可以设置执行该任务类型线程池的最小和最大线程数、最大重试次数。
使用任务池的注意事项 。任务必须无状态:任务不能在执行任务的机器中保存数据,比如某个任务是处理上传的文件,任务的属性里有文件的上传路径,如果文件上传到机器1,机器2 获取到了任务则会处理失败,所以上传的文件必须存在其他的集群里,比如OSS或SFTP。
异步任务的属性 。包括任务名称、下次执行时间、已执行次数、任务类型、任务优先级和
执行时的报错信息(用于快速定位问题)。


