
说到 long Adder,不得不提的就是AtomicLong。AtomicLong是JDK1.5开始出现的,里面主要使用了一个long类型的value作为成员变量。然后使用循环的CAS操作去操作value的值。
优化思想
LongAdder是JDK1.8开始出现的,所提供的API基本上可以替换掉原先的AtomicLong。LongAdder所使用的思想就是热点分离,这一点可以类比一下ConcurrentHashMap的设计思想。就是将value值分离成一个数组,当多线程访问时,通过hash算法映射到其中的一个数字进行计数。而最终的结果,就是这些数组的求和累加。这样一来,就减小了锁的粒度。如下图所示:
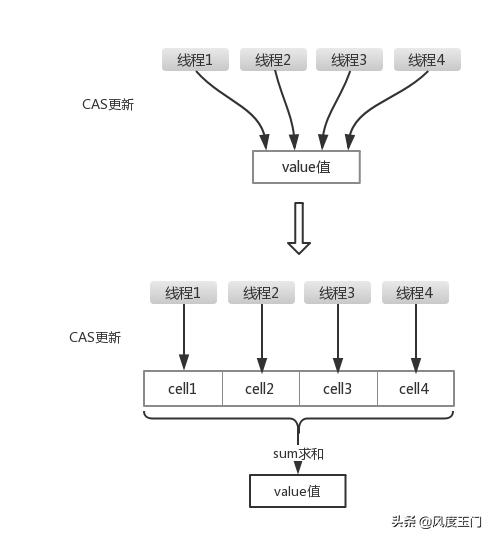
在实现的代码中, Long Adder一开始并不会直接使用Cell[]存储。而是先使用一个long类型的base存储,当casBase()出现失败时,则会创建Cell[]。此时,如果在单个Cell上面出现了cell更新冲突,那么会尝试创建新的Cell,或者将Cell[]扩容为2倍。代码如下:
void increment() {
add(1L);
}
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
if ((as = cells) != null || !casBase(b = base, b + x)) {// 如cells不为空,直接对cells操作;否则casBase
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x))) // CAS cell
long accumulate (x, null, uncontended); // 创建新的Cell或者扩容
}
}
对比测试
下面给出一段LongAdder和Atomic的对比测试代码:
public class CompareTest {
public static final int THREAD_COUNT = 1000;
static ExecutorService pool = Executors.newFixedThreadPool(THREAD_COUNT);
static CompletionService<Long> completionService = new ExecutorCompletionService<Long>(pool);
static final AtomicLong atomicLong = new AtomicLong(0L);
static final LongAdder longAdder = new LongAdder();
public static void main(String[] args) throws InterruptedException, ExecutionException {
long start = System.currentTimeMillis();
for(int i = 0; i < THREAD_COUNT; i++) {
completionService.submit(new Callable<Long>() {
@Override
public Long call() throws Exception {
for(int j = 0; j < 100000; j++) {
// atomicLong.incrementAndGet();
longAdder.increment();
}
return 1L;
}
});
}
for(int i = 0; i < THREAD_COUNT; i++) {
future <Long> future = completionService.take();
future.get();
}
System.out.println("耗时:" + (System.currentTimeMillis() - start));
pool.shutdown();
}
}
测试结果对比图如下:
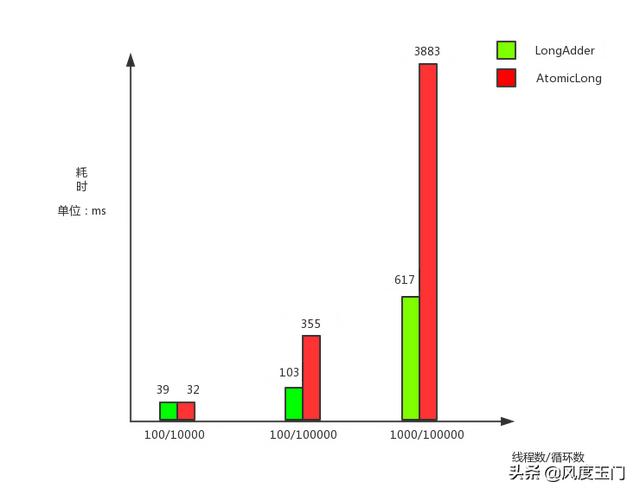
从上结果图可以看出,在并发比较低的时候,LongAdder和AtomicLong的效果非常接近。但是当并发较高时,两者的差距会越来越大。上图中在线程数为1000,每个线程循环数为100000时,LongAdder的效率是AtomicLong的6倍左右。
LongAccumulator 介绍
LongAccumulator是LongAdder的功能增强版。LongAdder的API只有对数值的加减,而LongAccumulator提供了自定义的函数操作。其 构造函数 如下:
// accumulator function :需要执行的 二元函数 (接收2个long作为形参,并返回1个long);identity:初始值 public LongAccumulator(LongBinaryOperator accumulatorFunction, long identity) { this.function = accumulatorFunction; base = this.identity = identity; }
上面构造函数,accumulatorFunction:需要执行的二元函数(接收2个long作为形参,并返回1个long);identity:初始值。下面看一个Demo:
public class LongAccumulatorDemo {
// 找出最大值
public static void main(String[] args) throws InterruptedException {
LongAccumulator accumulator = new LongAccumulator(Long::max, Long.MIN_VALUE);
Thread[] ts = new Thread[1000];
for (int i = 0; i < 1000; i++) {
ts[i] = new Thread(() -> {
Random random = new Random();
long value = random.nextLong();
accumulator.accumulate(value); // 比较value和上一次的比较值,然后存储较大者
});
ts[i].start();
}
for (int i = 0; i < 1000; i++) {
ts[i].join();
}
System.out.println(accumulator.longValue());
}
}
从上面代码可以看出,accumulate(value) 传入的值会与上一次的比较值对比,然后保留较大者,最后打印出最大值。
参考:《 Java 高并发程序设计》


