★★★ 建议 星标 我们 ★★★

![]()
2020年 Java 原创面试题库连载中
【000期】Java最全面试题库思维导图
【020期】JavaSE系列面试题汇总(共18篇)
【028期】JavaWeb系列面试题汇总(共10篇)
【042期】JavaEE系列面试题汇总(共13篇)
【049期】数据库系列面试题汇总(共6篇)
【053期】中间件系列面试题汇总(共3篇)
【065期】数据结构与算法面试题汇总(共11篇)
【076期】分布式面试题汇总(共10篇)
【100期】综合面试题系列汇总(共23篇)
【151期】100-150期汇总(共50篇)
【152期】如何应对高并发流量?
【153期】StringBuilder线程安全吗?为什么?
【154期】Redis的过期键删除策略有哪些?
【155期】Spring-Retry重试实现原理是什么?
【156期】数据库分库分表之后,如何解决事务问题?
【157期】为什么 SQL 语句不要过多的 join?
【158期】说说注册中心 zookeeper 和 eureka 中的CP和 AP
【159期】Java中的finally一定会被执行吗?
更多内容,点击上方名片查看 ![]()
RabbitMQ是目前非常热门的一款消息中间件,不管是互联网大厂还是中小企业都在大量使用。不管你是作为一名合格的开发同学还是运维同学,都有必要对RabbitMQ有所了解。但是本文并不是一篇rabbitmq入门文章,阅读需要有一定基础。

一、RabbitMQ简介

以熟悉的电商场景为例,如果商品服务和订单服务是两个不同的微服务,在下单的过程中订单服务需要调用商品服务进行扣库存操作。按照传统的方式,下单过程要等到调用完毕之后才能返回下单成功,如果网络产生波动等原因使得商品服务扣库存延迟或者失败,会带来较差的用户体验,如果在高并发的场景下,这样的处理显然是不合适的,那怎么进行优化呢?这就需要消息队列登场了。
消息队列提供一个异步通信机制,消息的发送者不必一直等待到消息被成功处理才返回,而是立即返回。消息中间件负责处理网络通信,如果网络连接不可用,消息被暂存于队列当中,当网络畅通的时候在将消息转发给相应的应用程序或者服务,当然前提是这些服务订阅了该队列。如果在商品服务和订单服务之间使用消息中间件,既可以提高并发量,又降低服务之间的耦合度。
RabbitMQ就是这样一款我们苦苦追寻的消息队列。RabbitMQ是一个开源的消息代理的队列服务器,用来通过普通协议在完全不同的应用之间共享数据。
RabbitMQ除了像兔子一样跑的很快以外,还有这些特点:
开源、性能优秀,稳定性保障提供可靠性消息投递模式、返回模式与Spring AMQP完美整合,API丰富集群模式丰富,表达式配置,HA模式,镜像队列模型保证数据不丢失的前提做到高可靠性、可用性
MQ典型应用场景:
异步处理:把消息放入消息中间件中,等到需要的时候再去处理。流量削峰:例如秒杀活动,在短时间内访问量急剧增加,使用消息队列,当消息队列满了就拒绝响应,跳转到错误页面,这样就可以使得系统不会因为超负载而崩溃。日志处理;应用解耦:假设某个服务A需要给许多个服务(B、C、D)发送消息,当某个服务(例如B)不需要发送消息了,服务A需要改代码再次部署;当新加入一个服务(服务E)需要服务A的消息的时候,也需要改代码重新部署;另外服务A也要考虑其他服务挂掉,没有收到消息怎么办?要不要重新发送呢?是不是很麻烦,使用MQ发布订阅模式,服务A只生产消息发送到MQ,B、C、D从MQ中读取消息,需要A的消息就订阅,不需要了就取消订阅,服务A不再操心其他的事情,使用这种方式可以降低服务或者系统之间的耦合。
二、rabbitmq集群部署
1、版本说明:
因为考虑到较早版本rabbitmq在k8s上的集群部署是使用autocluster插件去调用 Kubernetes apiserver来获取rabbitmq服务的endpoints,进而获取node节点信息,并自动加入集群,但是现在autocluster已不再更新了,并且只支持3.6.x版本,故而我们放弃了这种方式。
对于3.7.x或更新的版本,现在市场主流是使用 peer discovery subsystem来构建rabbitmq-cluster,官方github地址为:,本文版本我们选择rabbitmq3.8进行部署。
2、部署方式:
在Kubernetes上搭建RabbitMQ有4种部署方法,本文选用hostname模式
IP模式Pod 与server的DNSStatefulset 与 Headless Servicehostname模式
3、其他说明
后端存储使用ceph,大家也可根据需要对接使用nfsk8s: v1.18.3docker: 19.03.12centos: 7.7
4、rabbitmq集群部署-statefulset和持久化存储
---#创建命名空间test2apiVersion: v1kind: Namespacemetadata:name: test2---#RBAC 权限账号等apiVersion: v1kind: ServiceAccountmetadata:name: rabbitmqnamespace: test2---kind: RoleapiVersion: rbac.authorization.k8s.io/v1beta1metadata:name: endpoint-readernamespace: test2rules:- apiGroups: [""]resources: ["endpoints"]verbs: ["get"]---kind: RoleBindingapiVersion: rbac.authorization.k8s.io/v1beta1metadata:name: endpoint-readernamespace: test2subjects:- kind: ServiceAccountname: rabbitmqroleRef:apiGroup: rbac.authorization.k8s.iokind: Rolename: endpoint-reader---#service创建kind: ServiceapiVersion: v1metadata:name: rabbitmq-headlessnamespace: test2spec:clusterIP: NonepublishNotReadyAddresses: trueports:- name: amqpport: 5672- name: httpport: 15672selector:app: rabbitmq---kind: ServiceapiVersion: v1metadata:namespace: test2name: rabbitmq-servicespec:ports:- name: httpprotocol: TCPport: 15672targetPort: 15672- name: amqpprotocol: TCPport: 5672targetPort: 5672selector:app: rabbitmqtype: NodePort---#Configmap创建 rabbitmq配置文件apiVersion: v1kind: ConfigMapmetadata:name: rabbitmq-confignamespace: test2data:enabled_plugins: |[rabbitmq_management,rabbitmq_peer_discovery_k8s].#启用插件rabbitmq_management和rabbitmq_peer_discovery_k8srabbitmq.conf: |cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8scluster_formation.k8s.host = kubernetes.default.svc.cluster.localcluster_formation.k8s.address_type = hostnamecluster_formation.node_cleanup.interval = 30cluster_formation.node_cleanup.only_log_warning = truecluster_partition_handling = autohealqueue_master_locator=min-mastersloopback_users.guest = falsedefault_user=admindefault_pass=admindefault_vhost=loan# 必须设置service_name,否则Pod无法正常启动,这里设置后可以不设置statefulset下env中的K8S_SERVICE_NAME变量# cluster_formation.k8s.service_name = rabbitmq-headless# 必须设置hostname_suffix,否则节点不能成为集群# rabbitmq-headless.test2.svc.cluster.local中test2为namespace名称,按需修改cluster_formation.k8s.hostname_suffix = .rabbitmq-headless.test2.svc.cluster.localcluster_formation.randomized_startup_delay_range.min = 0cluster_formation.randomized_startup_delay_range.max = 2vm_memory_high_watermark. absolute = 1GBdisk_free_limit.absolute = 2GB---#statefulset创建(podAntiAffinity反亲和性)apiVersion: apps/v1kind: StatefulSetmetadata:name: rabbitmqnamespace: test2spec:serviceName: rabbitmq-headlessselector:matchLabels:app: rabbitmq #在apps/v1中,需与 .spec.template.metadata.label 相同,用于hostname传播访问podreplicas: 3 #副本数3,template:metadata:labels:app: rabbitmqannotations:scheduler.alpha.kubernetes.io/affinity: >{"podAntiAffinity": {"requiredDuringSchedulingIgnoredDuringExecution": [{"labelSelector": {"matchExpressions": [{"key": "app","operator": "In","values": ["rabbitmq"]}]},"topologyKey": "kubernetes.io/hostname"}]}}spec:serviceAccountName: rabbitmqterminationGracePeriodSeconds: 10containers:- name: rabbitmqimage: rabbitmq:3.8resources:limits:cpu: 2memory: 2Girequests:cpu: 1memory: 1GivolumeMounts:- name: config-volumemountPath: /etc/rabbitmq- name: rabbitmq-datamountPath: /var/lib/rabbitmq/mnesiaports:- name: httpprotocol: TCPcontainerPort: 15672- name: amqpprotocol: TCPcontainerPort: 5672livenessProbe:exec:command: ["rabbitmqctl", "status"]initialDelaySeconds: 60periodSeconds: 60timeoutSeconds: 5readinessProbe:exec:command: ["rabbitmqctl", "status"]initialDelaySeconds: 20periodSeconds: 60timeoutSeconds: 5imagePullPolicy: Alwaysenv:- name: HOSTNAMEvalueFrom:fieldRef:fieldPath: metadata.name- name: MY_POD_NAMESPACEvalueFrom:fieldRef:fieldPath: metadata.namespace- name: RABBITMQ_USE_LONGNAMEvalue: "true"- name: K8S_SERVICE_NAMEvalue: "rabbitmq-headless"- name: RABBITMQ_NODENAMEvalue: rabbit@$(HOSTNAME).$(K8S_SERVICE_NAME).$(MY_POD_NAMESPACE).svc.cluster.local- name: RABBITMQ_ERLANG_COOKIEvalue: "sccookie"volumes:- name: config-volumeconfigMap:name: rabbitmq-configitems:- key: rabbitmq.confpath: rabbitmq.conf- key: enabled_pluginspath: enabled_pluginsvolumeClaimTemplates:- metadata:name: rabbitmq-dataspec:storageClassName: "xsky-rbd"accessModes: [ "ReadWriteOnce" ]resources:requests:storage: 5Gi
[root@worker01 rmq]# kubectl apply -f rabbitmq-cluster.yamlnamespace/test1 unchangedserviceaccount/rabbitmq unchangedrole.rbac.authorization.k8s.io/endpoint-reader unchangedrolebinding.rbac.authorization.k8s.io/endpoint-reader unchangedservice/rabbitmq-headless unchangedservice/rabbitmq-service unchangedconfigmap/rabbitmq-config unchangedstatefulset.apps/rabbitmq configured
设置的web登录默认账号密码和vhost如下
default_user=admindefault_pass=admindefault_vhost=test
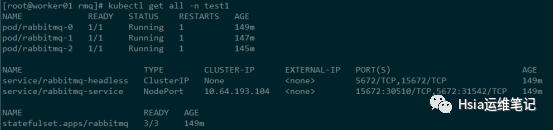
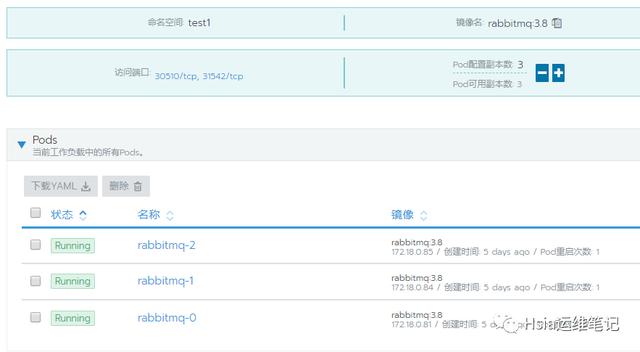
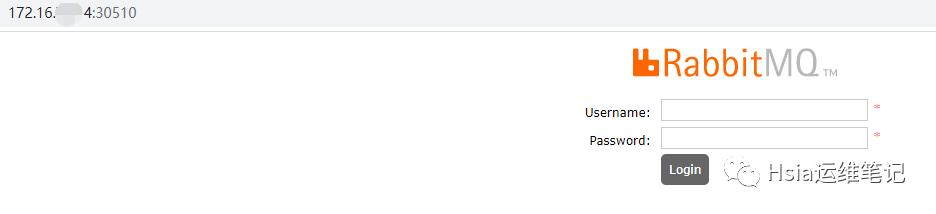
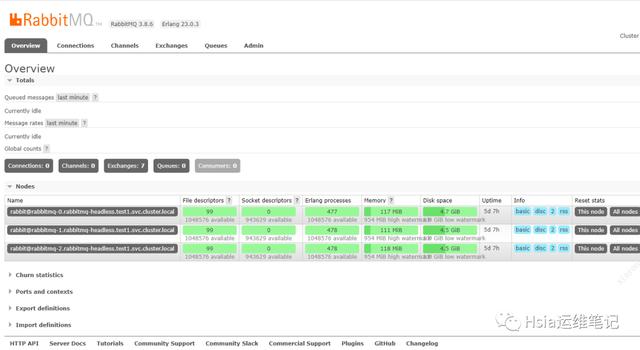
通过暴露的nodeport端口访问验证:,如下
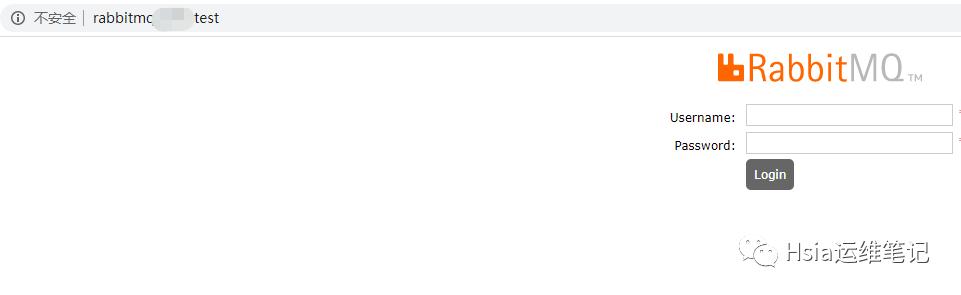
当然我们也可以创建ingress入口
apiVersion: extensions/v1beta1kind: Ingressmetadata:name: rabbitmqnamespace: test1spec:rules:- host: rabbitmq.domain.testhttp:paths:- backend:serviceName: rabbitmq-serviceservicePort: 15672
![]()
之前,给大家发过 三份Java 面试宝典,这次新增了一份,目前总共是 四份 面试宝典,相信在跳槽前一个月按照面试宝典准备准备,基本没大问题。
《java面试宝典5.0》 (初中级)
《350道Java面试题:整理自100+公司》 (中高级)
《资深java面试宝典-视频版》 (资深)
《Java[BAT]面试必备》 (资深)
分别适用于 初中级,中高级 , 资深 级工程师 的面试复习。
内容包含 java基础、javaweb、mysql性能优化、JVM、锁、百万并发、消息队列,高性能缓存、反射、Spring全家桶原理、微服务、Zookeeper、数据结构、限流熔断降级等等。

看到这里,证明有所收获


