前言
- SOFA Registry 源码|数据分片之核心-路由表 SlotTable 剖析

背景
在很多开源中间件中都会用到这种设计,比如redis slot槽,会将数据拆分然后分布到不同槽,这样提高了数据的横向扩展能力。SofaRegistry在储存数据的时候,也采用了这种设计,这样可以采用集群的方式来部署中间件,数据通过一定规则散落在各个节点,整体扩展性上来了。
数据扩展性
一般分为 横向扩展、纵向扩展 ,纵向就是加配置,比如买辆汽车,开个天窗,配置个高档音响,配置拉满,同样服务器还有数据库也能将配置拉满。横向扩展加上一辆车不够,两辆,加到满足需求为止
横向扩展,如果说我们把数据都放在一张表,那么它的横向扩展肯定是不行的,这时我们想到分库分表,sharing jdbc ,其实就是把某个字段进行一定的算法计算之后,决定它命中哪张表,哪个库,这样通过数据拆分,我们可以通过增加表的数量,数据库的数量来提高数据的存储量。
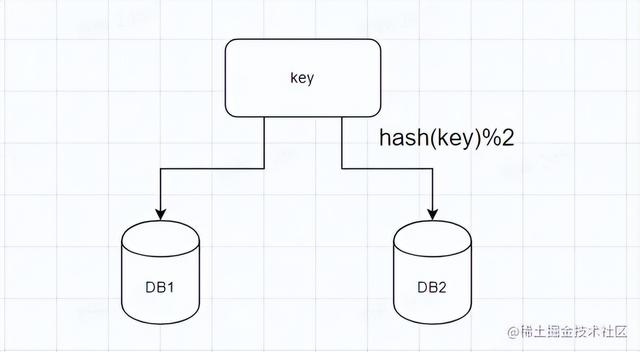
通过特定key,然后一定的算法计算,整除节点次数,这样数据就分配到这些节点
整除算法缺陷
虽然整除算法可以实现数据拆分效果,但是对于节点增加、减少的情况,会导致所有数据得重新分配,这样无疑成本就提高了。针对这种情况,一致性 Hash 算法就出现了。
一致性 hash 算法
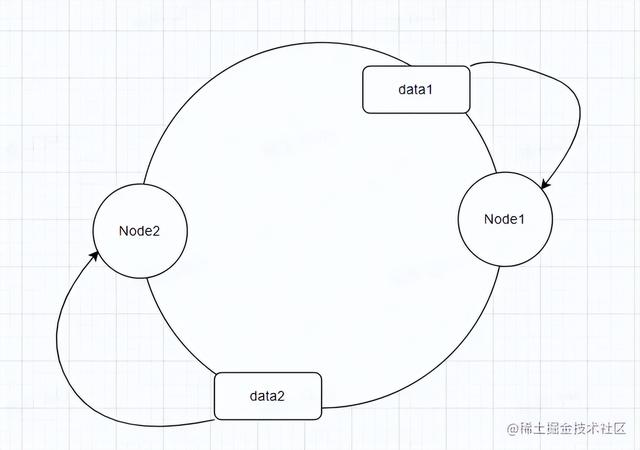
首先这个算法会将所有值储存在一个环里头,比如说data1的位置,只要落在上面这片区域属于Node1,下面区域是属于Node2,所以data2落在Node2进行储存。
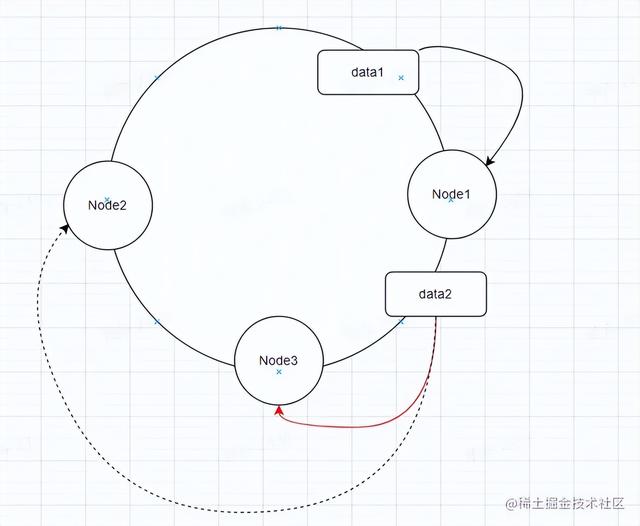
新增节点情况
比如说现在增加节点Node3,data1数据不会变,只是data2的数据从原本Node2迁移到Node3去。这样只会影响一部分数据。
减少节点情况
这时如果把Node2干掉,那么我们只需要将data2迁移到Node1,不会影响之前Node1的数据。
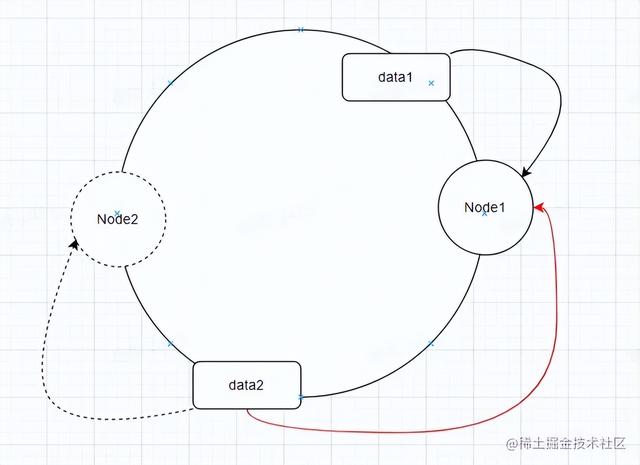
总结
从上面情况来看,一致性hash算法对于新增、删除节点,只是会影响部分数据。
数据倾斜问题
当我们节点分配不好的时候,就会出现某个节点数据贼多,这样会导致大部分请求都跑去某个节点,该节点压力会很多,其他节点又没有流量。那这个时候解决方案就是 增加虚拟节点 。
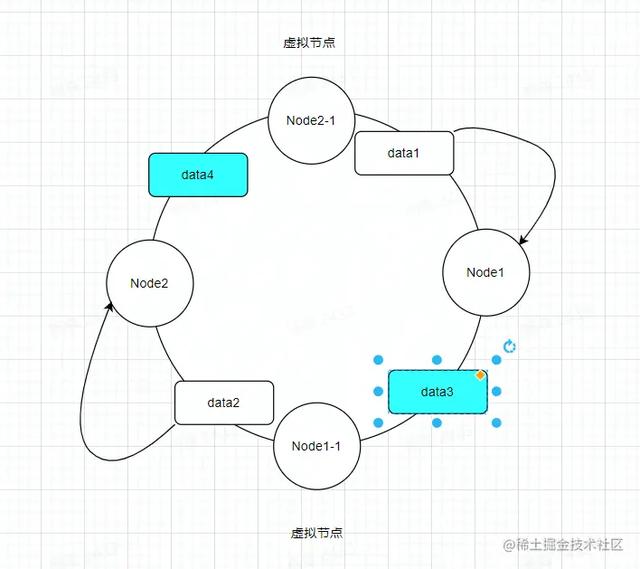
新增了Node1-1、Node2-1虚拟节点,这样数据就不会因为划分不均匀导致数据倾斜。
实践
我尝试的是带有虚拟节点的方案
//总节点数据,包括实际上节点,还有虚拟节点
static NavigableMap<Integer, List<String>> map = new TreeMap<>();
//收集实际上节点对应哪些虚拟节点
static Map<String, List< Integer >> map1 = new HashMap<>();
public static void main(String[] args) {
int a = 0;
while (a < 4) {
String ip = "172.29.3." + a;
map.put( hashcode (ip), new ArrayList<>());
map1.put(ip, new ArrayList<>(List.of(hashcode(ip))));
for (int b = 0; b < 150; b++) {
int number = hashcode(ip + "#" + random Util.randomInt(5));
map.put(number, new ArrayList<>());
List<Integer> list = map1.get(ip);
if (CollectionUtil.isEmpty(list)) {
map1.put(ip, new ArrayList<>(List.of(number)));
} else {
map1.get(ip).add(number);
}
}
a++;
}
int i = 0;
while (i < 8000000) {
String msg = RandomUtil.randomString(20);
get(map, msg, map1).add(msg);
i++;
}
map1.forEach((k, v) -> {
System.out.println(k + " " + map.get(hashcode(k)).size());
});
}
private static void remove(String ip) {
List<Integer> idList = map1.get(ip);
map1.remove(ip);
idList.forEach(id->map.remove(id));
}
//使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
private static int hashcode(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
private static List<String> get(NavigableMap<Integer, List<String>> map, String msg, Map<String, List<Integer>> map1) {
Map.Entry<Integer, List<String>> entry = map. ceiling Entry(hashcode(msg));
AtomicReference<List<String>> list = new AtomicReference<>();
if (entry == null ) {
map1.forEach((k, v) -> {
if (v.contains(map.firstEntry().getKey())) {
list.set(map.get(hashcode(k)));
}
});
} else {
map1.forEach((k, v) -> {
if (v.contains(entry.getKey())) {
list.set(map.get(hashcode(k)));
}
});
}
return list.get();
}
复制代码 - 有两个map,一个储存实际节点+虚拟节点数据的map,另一个是收集实际节点对应哪些虚拟节点
//总节点数据,包括实际上节点,还有虚拟节点
static NavigableMap<Integer, List<String>> map = new TreeMap<>();
//收集实际上节点对应哪些虚拟节点
static Map<String, List<Integer>> map1 = new HashMap<>();
复制代码 - 造了4个节点,我是以ip+”#”+随机数5位来作为值,但是ip呢经过实验,如果不是临近的话,数据分配还是不理想,我们可以这样做实际ip映射为172.29.3.xx,172.29.3.xx作为一个key去储存。
这里是往刚刚两个map储存数据
int a = 0;
while (a < 4) {
String ip = "172.29.3." + a;
map.put(hashcode(ip), new ArrayList<>());
map1.put(ip, new ArrayList<>(List.of(hashcode(ip))));
for (int b = 0; b < 150; b++) {
int number = hashcode(ip + "#" + RandomUtil.randomInt(5));
map.put(number, new ArrayList<>());
List<Integer> list = map1.get(ip);
if (CollectionUtil.isEmpty(list)) {
map1.put(ip, new ArrayList<>(List.of(number)));
} else {
map1.get(ip).add(number);
}
}
a++;
}
复制代码 - 这个是一致性hash算法的一部分了,ceilingEntry找到当前key比它大的节点,如果不存在则拿第一个节点。
private static List<String> get(NavigableMap<Integer, List<String>> map, String msg, Map<String, List<Integer>> map1) {
Map.Entry<Integer, List<String>> entry = map.ceilingEntry(hashcode(msg));
AtomicReference<List<String>> list = new AtomicReference<>();
if (entry == null) {
map1.forEach((k, v) -> {
if (v.contains(map.firstEntry().getKey())) {
list.set(map.get(hashcode(k)));
}
});
} else {
map1.forEach((k, v) -> {
if (v.contains(entry.getKey())) {
list.set(map.get(hashcode(k)));
}
});
}
return list.get();
}
复制代码 - hash算法
//使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
private static int hashcode(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
复制代码 - 跑下程序
172.29.3.3 1834587
172.29.3.2 1805299
172.29.3.1 1892821
172.29.3.0 2467293
复制代码 我们可以看到数据蛮均匀的分配的。
实战
上面的例子,比如说删除节点,里面数据没有做迁移的,这个纠结需不需要迁移呢?
需要迁移的,大家可以自行了解下redis slots槽的设计,如果集群里面新增节点,需要人工去手动将slot移动到新的节点,减少也是一样的操作。


