哈希表 是java中的一个键 – 值对数据结构的实现。 您可以使用“key”存储和检索“vlaue”,它是存储值的标识符。 很明显,’key’应该是独一无二的。
java.util.Hashtable扩展Dictionary并实现Map。 具有非空值的对象可以用作键或值。 哈希表的键必须实现 hashCode ()和equals()方法。 在本文的最后,你会发现这种情况背后的原因。

通常,使用空 构造函数 Hashtable()创建java中的哈希表。 这是一个糟糕的决定和一个经常重复的错误。 哈希表有两个其他的构造函数
Hashtable(int initialCapacity) 和 Hashtable(int initialCapacity, float loadFactor)
初始容量是在Hashtable 实例化 时创建的桶的数量。 Bucket是Hashtable存储的逻辑空间。
散列和 散列表
在详细了解Java的哈希表之前,您应该了解一般的哈希表。 假设v是要存储的值,并且k是用于存储/检索的密钥,则h是散列函数,其中v存储在表格的h(k)处。 要检索一个计算值h(k),以便您可以直接获取v.so的位置,则在键值对表中,不需要按顺序扫描键以标识值。
h(k)是哈希函数,它用于查找存储相应值v的位置。h(k)无法计算到无限空间。 分配给Hashtable的存储在程序中是有限的。 所以,函数h(k)应该在分配的频谱(逻辑地址空间)内返回一个数字。
Java中的散列
Java的哈希用法使用key和value对象中的hashCode()方法进行计算。以下是哈希表中计算hashCode’h’的核心代码。你可以看到key和value的hashCode()方法都被调用。
h + = e.key.hashCode()^ e.value.hashCode();
在自定义对象中使用hashCode()方法会更好。字符串有自己的hashCode方法,它计算hashcode值如下:
s [0] * 31 ^(n-1)+ s [1] * 31 ^(n-2)+ … + s [n-1]
如果你没有hashCode()方法,那么它是从Object类派生的。以下是Object类中hashCode()方法的 javadoc 注释:
返回对象的哈希码值。这种方法支持散列表的好处,例如java.util.Hashtable提供的散列表。
如果您要编写自定义的hashCode(),请遵循以下条件:
hashCode的一般约定是:只要在Java应用程序的执行过程中多次调用同一对象时,hashCode方法必须始终返回相同的整数,前提是修改了在对象的等值比较中使用的任何信息。
以下是提高Hashtable的性能。
如果两个对象根据equals(Object)方法相等,则对这两个对象中的每个对象调用hashCode方法必须产生相同的整数结果。
hashCode()通过使用对象的内部地址来保证不同的整数。
在Hashtable中碰撞
当我们试图限制散列函数的输出在分配的地址分辨率极限内时,就有可能发生冲突。对于两个不同的密钥k1和k2,如果我们有h(k1)= h(k2),那么这在散列表中称为碰撞。这意味着什么呢,我们的哈希函数指示我们在同一个位置存储两个不同的值(键也是不同的)。
当我们发生碰撞时,有多种方法可用来解决它。为了说明一些散列表碰撞解决方法,“单独链接”,“开放寻址”,“罗宾哈希散列法”,“布谷鸟散列法”等。Java的散列表使用“单独链接”来解决散列表中的冲突问题。
java的Hashtable中的冲突解决
Java使用单独的链接来解决冲突。回想一下Hashtable在桶中存储元素的一点。在单独的链接中,每个存储桶都将存储对链接列表的引用。现在假设你已经在bucket 1中存储了一个元素。这意味着,在bucket 1中你将有一个对 链表 的引用,并且在这个链表中你将有两个单元格。在这两个单元格中,您将拥有密钥和相应的值。
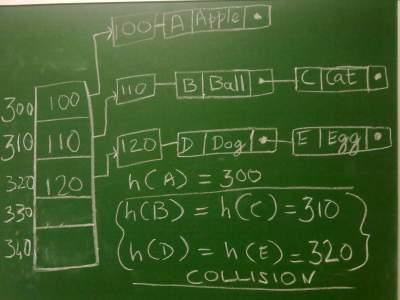
你为什么要存储key?
因为当发生冲突时,即当两个key导致相同的散列码并指向同一个存储桶(假定存储桶1)时,您希望将第二个元素也存储在同一个存储桶中。 将第二个元素添加到已创建的链接列表中作为相邻元素。
现在,当您检索一个值时,它将计算哈希码并将您引导至具有两个元素的存储桶。 您按顺序单独扫描这两个元素,并使用equals()方法比较这些键。 当按键学习时,您可以获得相应的值。 希望你已经明白了你的对象必须有hashCode()和equals()方法的原因。
Java在Hashtable中有一个私有静态类Entry。 它是一个列表的实现,你可以在那里看到,它存储了键和值。
散列表的性能
为了从你的Java Hashtable中获得更好的性能,你需要
1)使用initialCapacity和loadFactor参数
2)明智地使用它们
同时实例化一个Hashtable。
initialCapacitiy是在Hashtable实例化时要创建的存储区的数量。桶的数量和碰撞概率是成反比的。如果你有更多的桶数比需要,那么你碰撞的可能性较小。
例如,如果您要存储10个元素,并且您要将initialCapacity设为100,那么您将有100个存储桶。您将用100个桶的频谱计算hashCoe()10次。碰撞的可能性非常小。
但是如果你要为Hashtable提供initialCapacity为10,那么碰撞的可能性非常大。 loadFactor决定何时自动增加Hashtable的大小。 initialCapacity的默认大小是11,loadFactor是0.75。如果Hashtable的大小是3/4,那么Hashtable的大小会增加。
Java Hashtable中的新容量计算如下:
int newCapacity = oldCapacity * 2 + 1;
如果您给出较小的容量和负载因数,并且通常会执行rehash(),这会导致性能问题。因此,为了在Java中有效地提高Hashtable的性能,在实例化时,将initialCapacity设置为比需要的多25%,将loadFactor设置为0.75。


