
1.es简介
1.1 起源
,es的起源,是因为程序员Shay Banon在使用Apache Lucene发现不太好用,然后手动改造升级的过程中发展起来的。(程序员就是需要有这种动力~)实际上es也是一个java应用,跑在jvm里面的
1.2 与关系型数据库的区别

1.3 为什么这么快
索引 方式的区别,es主要是利用倒排索引(inverted index),这个翻译可能会让初次接触的人产生误解,误以为是倒着排序?其实不是这样,一般关系型数据库索引是把某个字段建立起一张索引表,传入这个字段的某个值,再去索引中判断是否有这个值,从而找到这个值所在数据(id)的位置。而倒排索引则是把这个值所在的文档id记录下来,当输入这个值的时候,直接查询出这个值所匹配的文档id,再取出id。所以我们在建立es索引的时候,有分词的概念,相当于可以把filed字段内容拆分,然后索引记录下来。例如“我爱中国”,可以拆分成“我”,“爱”,“中国”,“我爱中国”这五个词,同时记录下来这几个关键词的对应文档数据id是1,当我们查询“我”,“中国”时,都能查出这条数据。而如果使用关系型数据库去查包含“中国”这个关键字的数据的时候,则需要like前后通配全表扫描,无法快速找到关键词所在的数据行。
1.4 下载安装
在这个地址里面下载最新版本,目前是7.10.2(拖了一个月写完,我下载的时候是7.9.3- -!)
Windows版是一个压缩包文件,解压后(进入bin点开bat)即可使用。Linux版由于是直接在k8s里拉的镜像,这里就不做赘述。

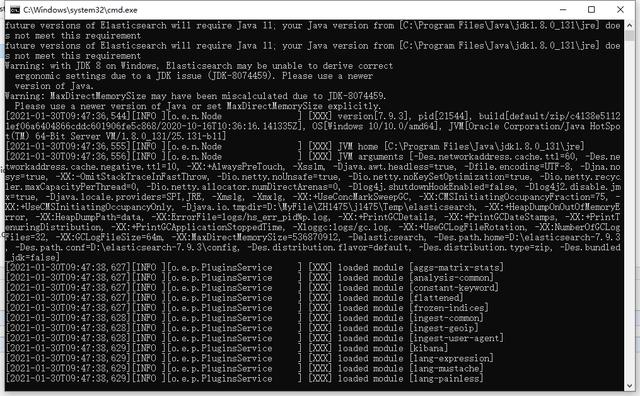
启动完成之后访问:,看见如下页面:You Know, for Search,就算启动成功啦。
1.5 安装可视化软件
像数据库一样,可视化界面有Navicat,SQLyog, MySql 自带的Workbench。es也是需要一个可视化ui界面来方便我们操作的。这里选择的也是官方的的kibana:
:

请注意需要选择与es匹配的版本,如果版本不匹配,则会提示你:

或者是其他类似版本不匹配的错误。
安装完成后就可以打开kibana玩耍啦,由于我本地没有数据,拿的是7.6.2版本搭建的elk中kibana界面:
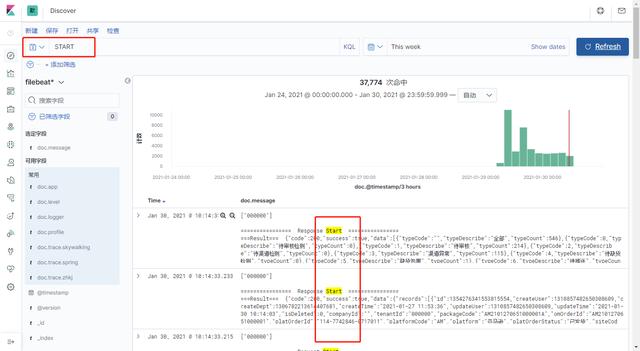
如果需要连接环境上的es,则可以在这里配置用户名和密码:
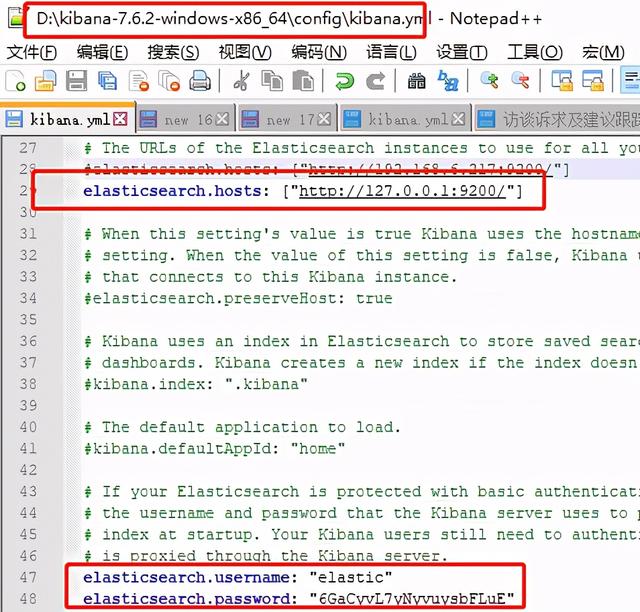
这个工具的搜索很方便,不需要指定查哪个字段的哪个值,直接在输入框搜索想要查询的字段即可。如果想看他对应的查询语句,点开F12打开控制台即可研究:

es的查询条件还是比较复杂的,但是在业务查询当中,一些比较简单的查询就可以满足大多数的通用分页查询了,除非是要开发报表查询,会复杂一些。
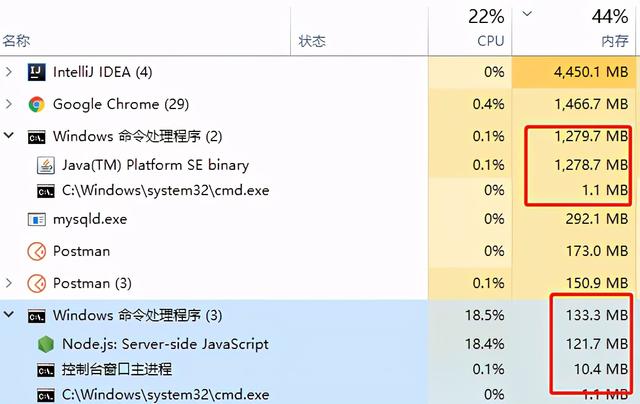
1.6 机器要求
本地跑demo的话还是很容易的,这两个应用默认占用内存都不大,有需求可以自行调小一点:
2.Java中使用Elasticsearch
2.1 使用spring-data提供的封装
2.1.1 maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
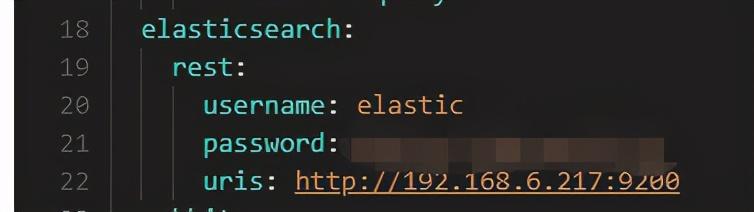
2.1.2 yml参数
2.1.3 代码中映射索引实体
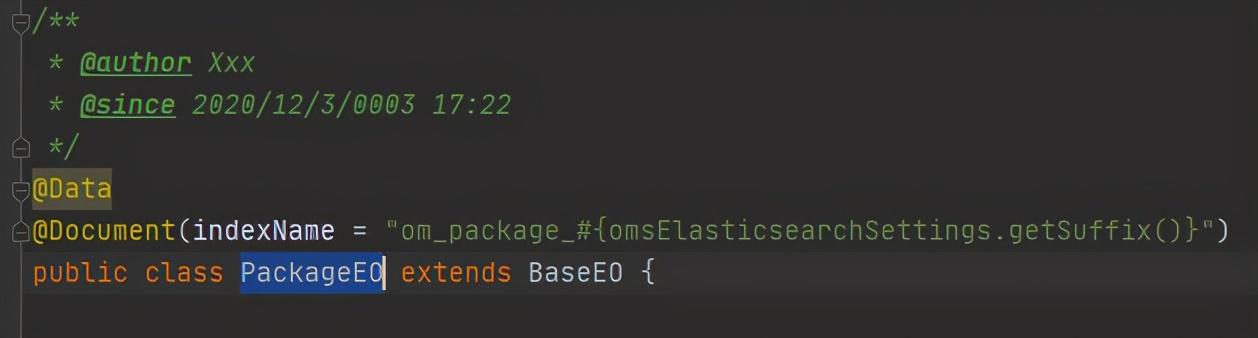
其中“omsElasticsearchSettings”这一段的意思是像mybatis那样解析表达式,找到omsElasticsearchSettings这个bean的getSuffix方法获取前后缀。这样就可以实现动态的根据环境生成映射对应的索引
1 @Configuration
2 @AllArgsConstructor
3 public class ElasticsearchConfig {
5 private final Environment env;
7 @Bean
8 public ElasticsearchSettings omsElasticsearchSettings(){
9 return new ElasticsearchSettings().setSuffix(env.getActiveProfiles()[0]);
10 }
12 }
13
16 @Data
17 @Accessors(chain = true)
18 public class ElasticsearchSettings {
20 public String suffix;
22 }
2.1.4 索引mapping生成
在启动项目的时候,SpringData会检测配置中的es里是否存在对应索引,如不存在,则会根据@Document实体中配置的@Field字段来生成mapping文件:
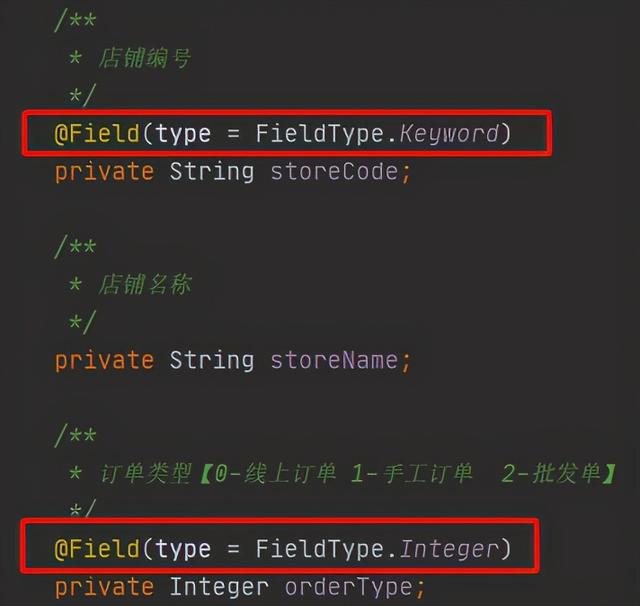
生成的Mapping Demo如下:
PUT om_package_dev/?pretty
{
"settings": {
"number_of_shards" :1,
"number_of_replicas" : 1
},
"mappings": {
"properties": {
"_class": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"actualFreightCost": {
"type": "double"
},
"actualPackageCost": {
"type": "double"
}
}
}
}
2.1.5 增删改
建立一个@Repository像mybatis一样来做增删改查的映射封装:
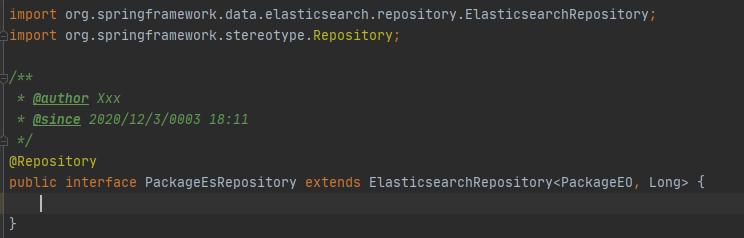
底层是SpringData提供封装的统一方法:
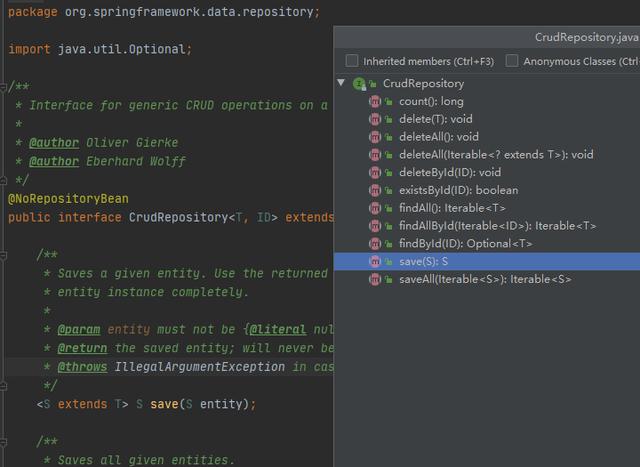
保存数据的时候直接调用即可:

一般来说订单这些重要数据不会删除,要删除也是逻辑删除,所以删除接口基本不调用。直接更新逻辑删除值就好。更新也是调用这个:save/saveAll
2.1.6 查
查是Es的重头戏,我们打开org.elasticsearch.index.query.AbstractQueryBuilder查看实现类可以发现,继承这个抽象类的各种查询类有四五十个之多,不得不让人感叹es的查询强大,(与反人类,学习成本太高了)。
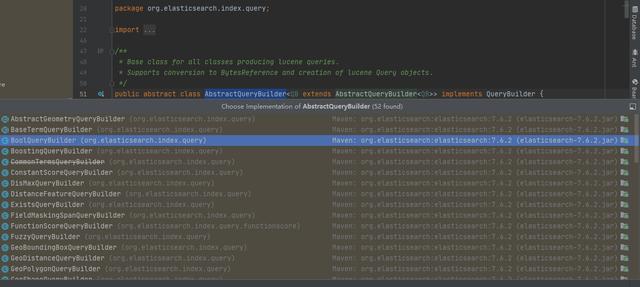
好消息是,如果业务场景不复杂,仅仅是想在分页查询上提高速度,那么只需要掌握一下几个类的用法即可:
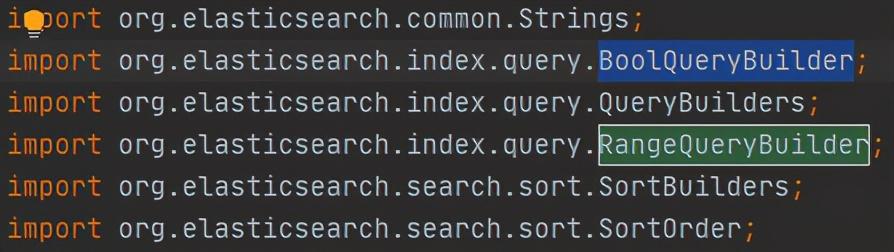
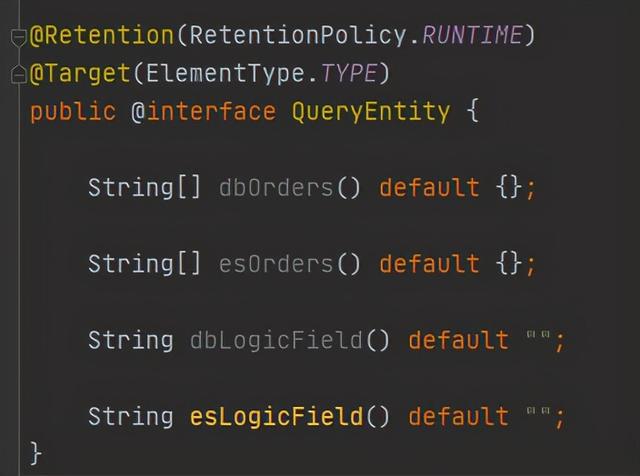
我们封装了两个查询枚举,一个用来定义该实体是es查询条件实体@interface QueryEntity:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
public @interface QueryEntity {
String[] dbOrders() default {};
String[] esOrders() default {};
String dbLogicField() default "";
String esLogicField() default "";
}
另外一个是用来定义字段,即使用es的哪个条件去查询@interface QueryField:

@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
public @interface QueryField {
String esField() default "";
String dbField() default "";
boolean like() default false;
boolean range() default false;
boolean require() default false;
boolean match() default false;
boolean commaSupported() default false;
boolean isBigDecimal() default false;
Class<?> searchTypeEnum() default void.class;
Class<?> sortTypeEnum() default void.class;
}
对应到实体上的用法demo就是:
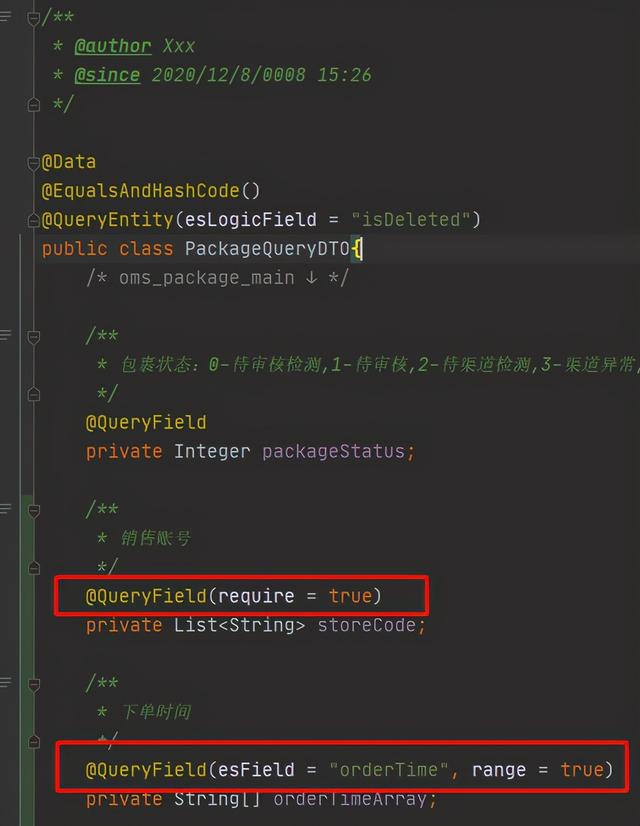
这样可以支持区间查询,字段类型,对应es字段,从设计上规避了根据每个字段,调用每个拼接语句的上百个if/else噩梦。通过一个通用的查询工具类,来封装拼接这些查询条件QueryUtils:
@Slf4j
public class QueryUtils {
private static Concurrent HashMap <Class<?>, HashMap<String, Field>> classFieldMap = new ConcurrentHashMap<>();
/**
* 构建查询
*
* @param obj
* @return 若为 null 说明该查询必定不会返回结果,无需查询 ES
*/
public static BoolQueryBuilder boolQuery(Object obj) {
if (obj == null) {
return null;
}
BoolQueryBuilder root = QueryBuilders.boolQuery();
if (!classFieldMap.containsKey(obj.getClass())) {
HashMap<String, Field> filedNameMap = new HashMap<>(obj.getClass().getDeclaredFields().length);
for (Field field : obj.getClass().getDeclaredFields()) {
filedNameMap.put(field.getName(), field);
}
classFieldMap.put(obj.getClass(), filedNameMap);
}
HashMap<String, Field> filedNameMap = classFieldMap.get(obj.getClass());
QueryEntity entitySetting = obj.getClass().getAnnotation(QueryEntity.class);
for (Field field : filedNameMap.values()) {
QueryField fieldSetting;
if ((fieldSetting = field.getAnnotation(QueryField.class)) == null) {
continue;
}
Object value = ReflectionUtil.getValue(field, obj);
if (isNullOrEmpty(value)) {
if (!fieldSetting.require()) {
continue;
}
return null;
}
String fieldName = getEsQueryFieldName(field, fieldSetting);
if (fieldSetting.range()) {
BoolQueryBuilder bool = QueryBuilders.boolQuery();
String[] arr = (String[]) value;
RangeQueryBuilder range = QueryBuilders.rangeQuery(fieldName);
if (arr.length != 2 || (StringUtils.isEmpty(arr[0]) && StringUtils.isEmpty(arr[1]))) {
continue;
}
if (!StringUtils.isEmpty(arr[0]) && StringUtils.isEmpty(arr[1])) {
bool.must(range.from(
fieldSetting.isBigDecimal() ? new BigDecimal(arr[0]) : DateUtil.parseAndGetTimestamp(arr[0])));
} else if (StringUtils.isEmpty(arr[0]) && !StringUtils.isEmpty(arr[1])) {
bool.must(range.to(fieldSetting.isBigDecimal() ? new BigDecimal(arr[1]) : DateUtil.parseAndGetTimestamp(arr[1])));
} else {
bool.must(range.from(fieldSetting.isBigDecimal() ? new BigDecimal(arr[0]) : DateUtil.parseAndGetTimestamp(arr[0])).
to(fieldSetting.isBigDecimal() ? new BigDecimal(arr[1]) : DateUtil.parseAndGetTimestamp(arr[1])));
}
root.must(bool);
} else if (field.getType() == List.class) {
assert value instanceof List<?>;
List<?> list = (List<?>) value;
if (CollectionUtils.isEmpty(list)) {
if (fieldSetting.require()) {
return null;
}
continue;
}
if (list.get(0) instanceof StoreListBO) {
BoolQueryBuilder bool1 = QueryBuilders.boolQuery();
for (Object store : list) {
StoreListBO bo = (StoreListBO) store;
BoolQueryBuilder bool2 = QueryBuilders.boolQuery();
if (!bo.getFlagAll()) {
bool2.must(QueryBuilders.termQuery("platformCode", bo.getPlatformCode()));
bool2.must(QueryBuilders.termsQuery("storeCode", bo.getStoreCodeList()));
}
bool1.should(bool2);
}
root.must(bool1);
} else {
root.must(QueryBuilders.termsQuery(fieldName, (List<?>) value));
}
} else if (fieldSetting.like()) {
root.must(QueryBuilders.wildcardQuery(fieldName, String.format("*%s*", value)));
} else if (fieldSetting.commaSupported()) {
root.must(QueryBuilders.termsQuery(fieldName, StringUtility.splitCommaString((String) value)));
} else if (fieldSetting.match()) {
if (fieldSetting.commaSupported()) {
root.must(QueryBuilders.multiMatchQuery(fieldName, StringUtility.splitCommaString((String) value)));
} else {
root.must(QueryBuilders.matchQuery(fieldName, value));
}
} else if (fieldSetting.searchTypeEnum().isEnum()) {
try {
Object[] objects = fieldSetting.searchTypeEnum().getEnumConstants();
if (objects[0] instanceof IEsSearchTypeEnum) {
IEsSearchTypeEnum searchTypeEnum = (IEsSearchTypeEnum) objects[0];
fieldName = searchTypeEnum.getFiledName((Integer) value);
Field filed = filedNameMap.get(IEsSearchTypeEnum.searchContent);
filed.setAccessible(true);
String searchContent = (String) ReflectUtil.getField(filed, obj);
if (!StringUtils.isEmpty(fieldName) && !StringUtils.isEmpty(searchContent)) {
root.must(QueryBuilders.termsQuery(fieldName, searchContent.split(",")));
}
}
} catch (Exception e) {
e.printStackTrace();
log.error("拼接搜索类型有误:", e.getMessage());
}
} else if (fieldSetting.sortTypeEnum().isEnum()) {
continue;
} else {
root.must(QueryBuilders.termQuery(fieldName, value));
}
}
if (entitySetting != null) {
if (!StringUtils.isEmpty(entitySetting.esLogicField())) {
root.must(QueryBuilders.termQuery(entitySetting.esLogicField(), LogicValueConstants.NORMAL));
}
}
root.must(QueryBuilders.termQuery("tenantId", AuthUtil.getTenantId()));
log.info("query : {}", Strings. toString (root));
return root;
}
private static boolean isNullOrEmpty(Object value) {
return Objects.isNull(value) || isEmptyString(value) || isEmptyCollection(value);
}
private static String getEsQueryFieldName(Field field, QueryField fieldSetting) {
return StringUtils.isEmpty(fieldSetting.esField()) ?
field.getName() : fieldSetting.esField();
}
private static boolean isEmptyCollection(Object value) {
return (value instanceof Collection) && CollectionUtils.isEmpty((Collection<?>) value);
}
private static boolean isEmptyString(Object value) {
return (value instanceof String) && StringUtils.isEmpty(value);
}
public static void handlePageable(Object obj, NativeSearchQueryBuilder builder) {
if (obj instanceof PageDTO) {
PageDTO pageDTO = (PageDTO) obj;
builder.withPageable(PageRequest.of(pageDTO.currForEsPaging(), pageDTO.size()));
}
}
public static void dealSort(Object obj, NativeSearchQueryBuilder builder) {
// 默认按最后更新时间倒序
String fieldName = null;
Boolean isAsc = false;
Boolean asc2Desc;
try {
HashMap<String, Field> fieldNameMap = classFieldMap.get(obj.getClass());
Field sortTypeField = fieldNameMap.get(IEsSortTypeEnum.SORT_TYPE);
if (sortTypeField != null) {
QueryField fieldSetting = sortTypeField.getAnnotation(QueryField.class);
if (fieldSetting != null && fieldSetting.sortTypeEnum().isEnum()) {
Object[] objects = fieldSetting.sortTypeEnum().getEnumConstants();
if (objects[0] instanceof IEsSortTypeEnum) {
IEsSortTypeEnum sortTypeEnum = (IEsSortTypeEnum) objects[0];
fieldName = sortTypeEnum.getFiledName((Integer) sortTypeField.get(obj));
asc2Desc = sortTypeEnum.getAsc2Desc((Integer) sortTypeField.get(obj));
Field filed = ReflectUtil.getField(obj.getClass(), IEsSortTypeEnum.SORT_ASC);
filed.setAccessible(true);
isAsc = (Boolean) ReflectUtil.getField(filed, obj);
if (isAsc != null) {
isAsc = asc2Desc ? !isAsc : isAsc;
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
log.error("拼接排序类型有误:", e);
}
builder.withSort(SortBuilders.fieldSort(fieldName == null ? IEsSortTypeEnum.DEFAULT_SORT_FILED : fieldName).order(isAsc == null ? SortOrder.DESC :
isAsc ? SortOrder.ASC : SortOrder.DESC));
log.info("es 排序参数" + Strings.toString(builder.build().getElasticsearchSorts().get(0)));
}
支持排序拼接、count统计类型拼接、时间区间拼接,金额拼接、list集合查询拼接,输入多个单号的时候,通过分隔符分隔拼接
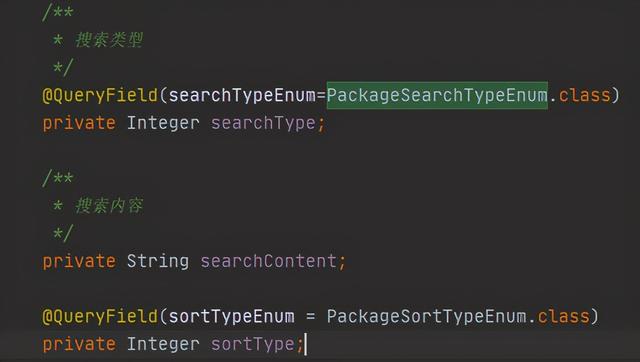
实体搜索类型

(PS:1.8新增了枚举类可以实现接口,这样枚举用起来也很舒服了)
这两个枚举类的作用主要是适配按照不同的搜索条件以及排序条件排序
3.千万级数据测试
3.1数据准备
标题写的那么夸张,千万级数据,哈哈,其实就是老套路搞了个存储过程往数据库塞一千万数据,然后同步到es测试啦
DROP PROCEDURE IF EXISTS test;
DELIMITER $$
CREATE PROCEDURE test()
BEGIN
DECLARE v_i INT UNSIGNED DEFAULT 10000001;
WHILE v_i < 10000894 DO
INSERT INTO ‘test’ VALUES('v_i')
SET v_i = v_i+1;
END WHILE;
END $$
DELIMITER ;
CALL test();
言归正传,测试的目的有两个,一个是后台任务的同步代码情况,验证数据库与es的数据一致性,同时估算性能,做到上线时迁移数据心中有数。二是模拟es在大数据量的情况下会不会有什么影响。
最终es结果如下:
- 后台任务分页查数据库,每页五千条,加上其他关联表查询,5000条差不多1~2秒。机器性能i7 9700 32g,10000000 / 5000 * 2s / 3600s = 大概一个小时左右同步完成。一千万数据大概占用1.3gb空间,要根据mapping字段多少来看。仅供参考
- 分页这边需要调整参数:

要不然es默认只能查出最大10000条。同时也需要调整es的参数:
PUT om_package_dev/_settings
{
"index" : {"max_result_window" : 10000000}
}
其实这个地方可以从业务角度思考一下,es默认10000也不是没有道理。对于大数据量,精准点击第666666页的人都是像我这样吃饱了没事干的。点到那页去干嘛?点之前你也不知道那页有啥呀。。。并且es分页效率也很低,选最后一页很慢。大数据量如果需要查询,一般根据条件精准查询。目前这点数据量查询还是非常快的。
4.小结
4.1 数据一致性
目前我们的方案主要是靠代码层面实现。当数据有变动时,发送一条消息给mq,由mq异步去同步es。同时,有一个后台任务一直在跑三分钟(根据数据量决定)以内的数据,以防mq失效有一个兜底任务。当然还有其他方案,比如通过MySQL的binlog写到es里面去,这种方案对性能要求高,同时需要引入第三方组件。最终我们选择了代码层面自己比较可控的一种方案。
4.2 elasticsearch-sql
从开始看见拼es查询条件,就在想如果能直接把sql转化成es就好了。后来搜了一下,果然有这种好东西,是中国自然语言处理开源组织提供的插件。但是已经写完了通用查询,就没有去研究这个插件怎么用。有兴趣的小伙伴可以试试。 另外:kibana的工具控制台也可以直接发送sql请求
POST _sql/translate
{
"query": """
SELECT doc.message FROM "filebeat-7.6.2-2021.01.30"
""",
"fetch_size": 100
}
4.3 Connection Rest By Peer
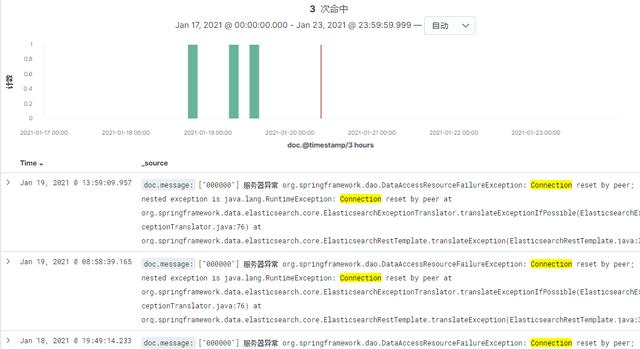
测试发现,有些时候:早上刚来、中午刚起床、晚上准备下班。也就是很久没人点了,第一次点击的时候会报这个错误。(我们的测试真敬业- -)
出现Connection Rest By Peer的问题,一般是一端关闭了连接,而另一端还以为对方在呢,然后傻乎乎的发请求过去,发现对方已经不跟它玩了。查看了es所在机器的k8s keepalive设置:

可以看见默认的keepalive连接超时时间是7200s,也就是两小时。吻合了测试发现的报错时间点,也符合日志中记录的时间。而es客户端这边如果不指定keepalive的话,默认取的是ConnectionKeepAliveStrategy里面的-1。所以java客户端这边-1不会断开连接,而Linux那边两小时就会断开,从而造成了Connection Rest By Peer。研究了一下SpringData配置es参数的地方,发现Spring配置除了获取配置中的url和密码之外,没有可以配置keepalive的地方。只有重写RestClientBuilder的构建逻辑,实际上SpringData底层也是用的es提供的客户端,只不过在上层再封装了一下:
package com.zhkj.oms.config;
import org.apache.http.HeaderElement;
import org.apache.http.HeaderElementIterator;
import org.apache.http.HttpHost;
import org.apache.http.HttpResponse;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.conn.ConnectionKeepAliveStrategy;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.message.BasicHeaderElementIterator;
import org.apache.http.protocol.HTTP;
import org.apache.http.protocol.HttpContext;
import org.apache.http.util.Args;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.boot.autoconfigure.elasticsearch.ElasticsearchRestClientProperties;
import org.springframework.boot.autoconfigure.elasticsearch.RestClientBuilderCustomizer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author Xxx
* @since 2021/1/19/0019 11:04
*
* 0.运维那边没有改keepalive,linux默认7200s 我们这边默认-1无限制
* 1.SpringData里面没有设置keepalive的地方,只有重写RestClientBuilder的构建
* 2.再重新实现HttpAsyncClientBuilder里面的ConnectionKeepAliveStrategy获取keepalive的方法
*/
@Configuration
public class EsRestClientBuilderConfig {
@Bean
RestClientBuilder elasticsearchRestClientBuilder(ElasticsearchRestClientProperties properties,
ObjectProvider<RestClientBuilderCustomizer> builderCustomizers) {
HttpHost[] hosts = properties.getUris().stream().map(this::createHttpHost).toArray(HttpHost[]::new);
RestClientBuilder builder = RestClient.builder(hosts);
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials(properties.getUsername(), properties.getPassword()));
builder.setHttpClientConfigCallback((httpClientBuilder) -> {
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(httpClientBuilder));
httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);
httpClientBuilder.setKeepAliveStrategy(new ConnectionKeepAliveStrategy() {
@Override
public long getKeepAliveDuration(HttpResponse response, HttpContext context) {
Args.notNull(response, "HTTP response");
final HeaderElementIterator it = new BasicHeaderElementIterator(
response.headerIterator(HTTP.CONN_KEEP_ALIVE));
while (it.hasNext()) {
final HeaderElement he = it.nextElement();
final String param = he.getName();
final String value = he.getValue();
if (value != null && param.equalsIgnoreCase("timeout")) {
try {
return Long.parseLong(value) * 1000;
} catch (final NumberFormatException ignore) {
}
}
}
// 三分钟
return 1 * 60 * 1 * 1000;
}});
return httpClientBuilder;
});
builder.setRequestConfigCallback((requestConfigBuilder) -> {
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(requestConfigBuilder));
return requestConfigBuilder;
});
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(builder));
return builder;
}
private HttpHost createHttpHost(String uri) {
try {
return createHttpHost(URI.create(uri));
}
catch (IllegalArgumentException ex) {
return HttpHost.create(uri);
}
}
private HttpHost createHttpHost(URI uri) {
if (!StringUtils.hasLength(uri.getUserInfo())) {
return HttpHost.create(uri.toString());
}
try {
return HttpHost.create(new URI(uri.getScheme(), null, uri.getHost(), uri.getPort(), uri.getPath(),
uri.getQuery(), uri.getFragment()).toString());
}
catch (URISyntaxException ex) {
throw new IllegalStateException(ex);
}
}
}
看完三件事❤️
如果你觉得这篇内容对你还蛮有帮助,我想邀请你帮我三个小忙:
- 点赞,转发,有你们的 『点赞和评论』,才是我创造的动力。
- 关注头条号 『 JAVA后端架构 』,不定期分享原创知识。
- 同时可以期待后续文章ing
- 关注作者后台私信【 888 】有惊喜相送



