MD5 (Message-Digest Algorithm),想必大家都再熟悉不过了吧。通常我们调用第三方支付接口的时候都会遇到这种算法或者 SHA 等等类似的算法来做签名验证,由于其是不可逆的算法,对应破解难度也很大。
底层原理
MD5算法的过程分为四步:处理原文,设置初始值,循环加工,拼接结果。
处理原文
首先,我们计算出原文长度(bit)对512求余的结果,如果不等于448,就需要填充原文使得原文对512求余的结果等于448。填充的方法是第一位填充1,其余位填充0。填充完后,信息的长度就是512*N+448。
之后,用剩余的位置(512-448=64位)记录原文的真正长度,把长度的二进制值补在最后。这样处理后的信息长度就是512*(N+1)。
设置初始值
MD5的哈希结果长度为128位,按每32位分成一组共4组。这4组结果是由4个初始值A、B、C、D经过不断演变得到。MD5的官方实现中,A、B、C、D的初始值如下(16进制):
A=0x01234567
B=0x89ABCDEF
C=0xFEDCBA98
D=0x76543210
循环加工
这一步是最复杂的一步,我们看看下面这张图,此图代表了单次A,B,C,D值演变的流程。
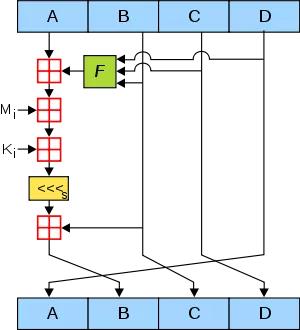
单次子循环过程
图中,A,B,C,D就是哈希值的四个分组。每一次循环都会让旧的ABCD产生新的ABCD。一共进行多少次循环呢?由处理后的原文长度决定。
假设处理后的原文长度是M
主循环次数 = M / 512
每个主循环中包含 512 / 32 * 4 = 64 次 子循环。
1.绿色F
图中的绿色F,代表非线性函数。官方MD5所用到的函数有四种:
F(X, Y, Z) =(X&Y) | ((~X) & Z)
G(X, Y, Z) =(X&Z) | (Y & (~Z))
H(X, Y, Z) =X^Y^Z
I(X, Y, Z)=Y^(X|(~Z))
在主循环下面64次子循环中,F、G、H、I 交替使用,第一个16次使用F,第二个16次使用G,第三个16次使用H,第四个16次使用I。
2.红色“田”字
很简单,红色的田字代表相加的意思。
3.Mi
Mi是第一步处理后的原文。在第一步中,处理后原文的长度是512的整数倍。把原文的每512位再分成16等份,命名为M0~M15,每一等份长度32。在64次子循环中,每16次循环,都会交替用到M1~M16(命名+1)之一。
4.Ki
一个常量,在64次子循环中,每一次用到的常量都是不同的。
5.黄色的<<<S
循环左移S位,S的值也是常量。
“流水线”的最后,让计算的结果和B相加,取代原先的B。新ABCD的产生可以归纳为:
新A = 原d
新B = b+((a+F(b,c,d)+Mj+Ki)<<<s)
新C = 原b
新D = 原c
总结一下主循环中的64次子循环,可以归纳为下面的四部分:
拼接结果
一步就很简单了,把循环加工最终产生的A,B,C,D四个值拼接在一起,转换成 字符串 即可
整个过程及其复杂和繁琐,也促使它在一定程度上保证了 hash 值的均匀分布和安全性。
关于MD5破解的方法
即使MD5的加密如此复杂,但也并非不可破解的。但总体来说,所有的破解方法都采用“碰撞”方式,类似于不同字符的hash值可能相同的原理,即hash(A)==hash(B),尽管大多数的时候在内存中A!=B,但是MD5加密后的值是相同的。
那么怎么实现MD5的摘要碰撞呢?
MD5的破解方法及其多,像暴力枚举,字典, 彩虹表 等方法。
1.暴力 枚举法
简单暴力的枚举出原文,并计算他们的hash值,看是否与摘要信息一致来达到破解目的。此方法时间复杂度极高,仅仅8位的密码,只考虑Base64中的字符,就会有64^8中可能,如果只是单机破解,可能需要几十年。当然,也可以取巧,例如考虑生日或者电话号码等等,缩小穷举范围。
2.字典法
既然暴力破解这么费时,典型的以时间换空间,那么就有人采用了相反的方式,即字典法,拿空间换时间。
原理就是记录尽可能多的原文和对应的hash值,破解的时候,拿到摘要去找查找对应的原文,即可快速的碰撞摘要信息从而达到破解的目的。
那么,对应的8位密码,按照Base64可打印字符排列组合,大概需要多大的空间呢?
即(128+64)*64^8=6PB的空间,假设一台计算器的内存为1TB,则需要6144台计算机存储所有的数据。而这对应的只是一个8位数的密码,越长,存储的成本也就成指数增长。
3.彩虹表法(比较烧脑,不感兴趣的可以绕开)
了解彩虹表之前,先了解两个函数:H(X),R(X)
H(X) :生成信息摘要的哈希函数,比如MD5,比如SHA256。
R(X) :从信息摘要转换成另一个字符串的衰减函数(Reduce)。其中R(X)的 定义域 是H(X)的 值域 ,R(X)的值域是H(X)的定义域。但要注意的是,R(X)并非H(X)的反函数。
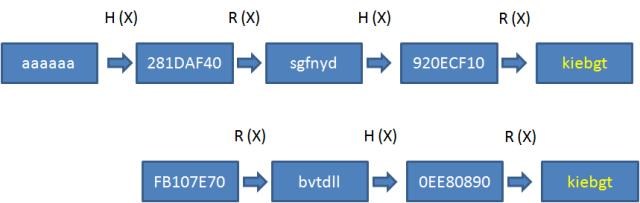
通过交替运算H和R若干次,可以形成一个原文和哈希值的链条。假设原文是aaaaaa,哈希值长度32bit,那么哈希 链表 就是下面的样子

这个链条有多长呢?假设H(X)和R(X)的交替重复K次,那么链条长度就是2K+1。同时,我们只需把链表的首段和末端存入 哈希表 中:

下面举例说明:
给定信息摘要:920ECF10
如何得到原文呢?只需进行R(X)运算:
R(920ECF10) = kiebgt
查询哈希表可以找到末端kiebgt对应的首端是aaaaaa,因此摘要920ECF10的原文“极有可能”在aaaaaa到kiebgt的这个链条当中。
接下来从aaaaaa开始,重新交替运算R(X)与H(X),看一看摘要值920ECF10是否是其中一次H(X)的结果。从链条看来,答案是肯定的,因此920ECF10的原文就是920ECF10的前置节点sgfnyd。

需要补充的是,如果给定的摘要值经过一次R(X)运算,结果在哈希表中找不到,可以继续交替H(X)R(X)直到第K次为止
其实,每个hash链表维护了一组映射关系,每组包括k个映射,但只需存储首位两个字符串。假设K=10,那么其需要的存储空间则为全量字典的1/10,效率也就提高了10倍。
即使如此,彩虹表的衰减函数R(X)依然存在致命弱点,即使R(X)设计的hash分布再均衡,依然存在hash碰撞的可能。
示例:
给定信息摘要:FB107E70
经过多次R(X),H(X)运算,得到结果kiebgt
通过哈希表查找末端kiebgt,可以找出首端aaaaaa
但是,FB107E70并不在aaaaaa到kiebgt的哈希链条当中,这就是R(X)的碰撞造成的。
这个问题看似没什么影响,既然找不到就重新生成一组首尾映射即可。但是想象一下,当K值较大的时候,哈希链很长,一旦两条不同的哈希链在某个节点出现碰撞,后面所有的明文和哈希值全都变成了一毛一样的值。
这样造成的后果就是冗余存储。原本两条哈希链可以存储 2K个映射,由于重复,真正存储的映射数量不足2K。
这个时候,彩虹表出现了,嗯,现在才是真正的彩虹表原理部分:
彩虹表对链表进行了改进,把原来的R(X)分割成R(1)….R(K)个衰减函数,这样也可能发生碰撞,但最多同一级的碰撞,即R1和R1,R2和R2碰撞,大大避免了数据重复存储的可能。
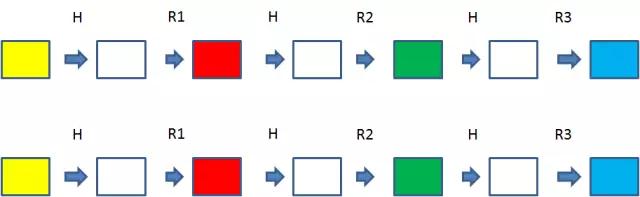
彩虹表示例
至于比彩虹表更厉害的方法,只能求助于中国的工程师了:
2004年,王小云教授提出了非常高效的MD5碰撞方法。
2009年,冯登国、谢涛利用差分攻击,将MD5的碰撞算法复杂度进一步降低。
对于单机来说,暴力枚举法的时间成本很高,字典法的空间成本很高。但是利用分布式计算和分布式存储,仍然可以有效破解MD5算法。因此这两种方法同样被黑客们广泛使用。
Java 中MD5好用的工具
在java.security.MessageDigest下提供了获取MD5示例和加密的方法

结果:4QrcOUm6Wau+VuBX8g+IPg==
为了方便大家阅读,代码使用了Base64对加密的结果进行了处理。
MD5/SHA到底是不是 加密算法
网上看到大家讨论MD5/SHA到底算不算加密算法,百度百科将其列为不可逆加密算法,我觉得既然传输的内容并进行了哈希计算,并且内容不可知且难以破解,原则上算是一种加密算法,但本人觉得没必要在这上面浪费时间进行讨论,面试官也绝不会因为这个问题决定是否聘用你,你只要搞清楚其中原理就好了。
关于这个问题,本人不再回复,谢谢!!


