正文开始前,分享一份非常不错的干货 《 Java 核心知识体系&面试资料.pdf》!
分享一份非常不错的 Java 进阶干货 《Java 核心知识体系&面试资料.pdf》 , 内容覆盖很广,Java 核心基础、Java 多线程、高并发、Spring、微服务、Netty 与 RPC、Zookeeper、Kafka、RabbitMQ、Habase、设计模式、负载均衡、分布式缓存、Hadoop、Spark、Storm、云计算等。
获取方式:【 关注 + 转发 】后, 私信 我,回复关键字【 资源 】,即可免费无套路获取哦~
以下是资源的部分目录以及内容截图:







重要的事再说一遍,获取方式:【 关注 + 转发 】后, 私信 我,回复关键字【 资源 】,即可免费无套路获取哦~
正文开始
JMH,即Java Microbenchmark Harness,这是专门用于进行代码的微基准测试的一套工具API。
JMH 由 OpenJDK/Oracle 里面那群开发了 Java 编译器的大牛们所开发 。何谓 Micro Benchmark 呢? 简单地说就是在 method 层面上的 benchmark,精度可以精确到微秒级。
Java的基准测试需要注意的几个点:
- 测试前需要预热。
- 防止无用代码进入测试方法中。
- 并发测试。
- 测试结果呈现。
比较典型的使用场景:
- 当你已经找出了热点函数,而需要对热点函数进行进一步的优化时,就可以使用 JMH 对优化的效果进行定量的分析。
- 想定量地知道某个函数需要执行多长时间,以及执行时间和输入 n 的相关性
- 一个函数有两种不同实现(例如JSON序列化/反序列化有Jackson和Gson实现),不知道哪种实现性能更好
尽管 JMH 是一个相当不错的 Micro Benchmark Framework,但很无奈的是网上能够找到的文档比较少,而官方也没有提供比较详细的文档,对使用造成了一定的障碍。 但是有个好消息是官方的 Code Sample 写得非常浅显易懂, 推荐在需要详细了解 JMH 的用法时可以通读一遍——本文则会介绍 JMH 最典型的用法和部分常用选项。
第一个例子
添加maven依赖
如果使用maven项目,只需要添加如下依赖:
<!-- JMH-->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
<scope>provided</scope>
</dependency>
编写性能测试
接下来我写一个比较字符串连接操作的时候,直接使用字符串相加和使用 StringBuilder 的append方式的性能比较测试:
/**
* 比较字符串直接相加和StringBuilder的效率
*
* @author XiongNeng
* @version 1.0
* @since 2018/1/7
*/
@BenchmarkMode(Mode. Throughput )
@Warmup(iterations = 3)
@Measurement(iterations = 10, time = 5, timeUnit = TimeUnit.SECONDS)
@Threads(8)
@Fork(2)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class StringBuilderBenchmark {
@Benchmark
public void testStringAdd() {
String a = "";
for (int i = 0; i < 10; i++) {
a += i;
}
print(a);
}
@Benchmark
public void testStringBuilderAdd() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10; i++) {
sb.append(i);
}
print(sb.toString());
}
private void print(String a) {
}
}
执行方式
这个代码里面有好多注解,你第一次见可能不知道什么意思。先不用管,我待会一一介绍。
我们来运行这个测试,运行JMH基准测试有多种方式,一个是生成jar文件执行, 一个是直接写main函数或写单元测试执行。
一般对于大型的测试,需要测试时间比较久,线程比较多的话,就需要去写好了丢到linux程序里执行, 不然本机执行很久时间什么都干不了了。
mvn clean package java -jar target/benchmarks.jar
先编译打包之后,然后执行就可以了。当然在执行的时候可以输入-h参数来看帮助。
另外如果对于一些小的测试,比如我写的上面这个小例子,在IDE里面就可以完成了,丢到linux上去太麻烦。 这时候可以在里面添加一个main函数如下:
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(StringBuilderBenchmark.class.getSimpleName())
.output("E:/Benchmark.log")
.build();
new Runner(options).run();
}
这里其实也比较简单,new个Options,然后传入要运行哪个测试,选择基准测试报告输出文件地址,然后通过Runner的run方法就可以跑起来了。
报告结果
我们跑一下这个基准测试,完成后打开 E:/Benchmark.log,结果如下:
# JMH version: 1.20 # VM version: JDK 1.8.0_131, VM 25.131-b11 # VM invoker: C:Program FilesJavajdk1.8.0_131 jre bin java. exe # VM options: -javaagent:E:Program FilesJetBrainsIntelliJ IDEA 2017.3libidea_rt.jar=62744:E:Program FilesJetBrainsIntelliJ IDEA 2017.3bin -Dfile. encoding =UTF-8 # Warmup: 3 iterations, 1 s each # Measurement: 10 iterations, 5 s each # Timeout: 10 min per iteration # Threads: 16 threads, will synchronize iterations # Benchmark mode: Throughput, ops /time # Benchmark: com.xncoding.benchmark.string.StringBuilderBenchmark.testStringAdd # Run progress: 0.00% complete , ETA 00:03:32 # Fork: 1 of 2 # Warmup Iteration 1: 7332.410 ops/ms # Warmup Iteration 2: 8758.506 ops/ms # Warmup Iteration 3: 9078.783 ops/ms Iteration 1: 8824.713 ops/ms Iteration 2: 9084.977 ops/ms Iteration 3: 9412.712 ops/ms Iteration 4: 8843.631 ops/ms Iteration 5: 9030.556 ops/ms Iteration 6: 9090.677 ops/ms Iteration 7: 9493.148 ops/ms Iteration 8: 8664.593 ops/ms Iteration 9: 8835.227 ops/ms Iteration 10: 8570.212 ops/ms # Run progress: 25.00% complete, ETA 00:03:15 # Fork: 2 of 2 # Warmup Iteration 1: 5350.686 ops/ms # Warmup Iteration 2: 8862.238 ops/ms # Warmup Iteration 3: 8086.594 ops/ms Iteration 1: 9105.306 ops/ms Iteration 2: 8288.588 ops/ms Iteration 3: 9307.902 ops/ms Iteration 4: 9195.150 ops/ms Iteration 5: 8715.555 ops/ms Iteration 6: 9075.069 ops/ms Iteration 7: 9041.037 ops/ms Iteration 8: 9187.099 ops/ms Iteration 9: 9145.134 ops/ms Iteration 10: 9124.229 ops/ms Result "com.xncoding.benchmark.string.StringBuilderBenchmark.testStringAdd": 9001.776 ±(99.9%) 253.496 ops/ms [Average] (min, avg, max) = (8288.588, 9001.776, 9493.148), stdev = 291.926 CI (99.9%): [8748.280, 9255.272] (assumes normal distribution) # JMH version: 1.20 # VM version: JDK 1.8.0_131, VM 25.131-b11 # VM invoker: C:Program FilesJavajdk1.8.0_131jrebinjava.exe # VM options: -javaagent:E:Program FilesJetBrainsIntelliJ IDEA 2017.3libidea_rt.jar=62744:E:Program FilesJetBrainsIntelliJ IDEA 2017.3bin -Dfile.encoding=UTF-8 # Warmup: 3 iterations, 1 s each # Measurement: 10 iterations, 5 s each # Timeout: 10 min per iteration # Threads: 16 threads, will synchronize iterations # Benchmark mode: Throughput, ops/time # Benchmark: com.xncoding.benchmark.string.StringBuilderBenchmark.testStringBuilderAdd # Run progress: 50.00% complete, ETA 00:02:07 # Fork: 1 of 2 # Warmup Iteration 1: 27202.528 ops/ms # Warmup Iteration 2: 26500.586 ops/ms # Warmup Iteration 3: 27190.346 ops/ms Iteration 1: 27891.257 ops/ms Iteration 2: 28704.541 ops/ms Iteration 3: 27785.951 ops/ms Iteration 4: 26841.454 ops/ms Iteration 5: 26024.288 ops/ms Iteration 6: 25592.494 ops/ms Iteration 7: 25626.875 ops/ms Iteration 8: 25302.248 ops/ms Iteration 9: 25519.780 ops/ms Iteration 10: 25275.334 ops/ms # Run progress: 75.00% complete, ETA 00:01:02 # Fork: 2 of 2 # Warmup Iteration 1: 30376.008 ops/ms # Warmup Iteration 2: 25131.064 ops/ms # Warmup Iteration 3: 25622.342 ops/ms Iteration 1: 25386.845 ops/ms Iteration 2: 25825.139 ops/ms Iteration 3: 26029.607 ops/ms Iteration 4: 25531.748 ops/ms Iteration 5: 25374.934 ops/ms Iteration 6: 25204.530 ops/ms Iteration 7: 22934.211 ops/ms Iteration 8: 23907.677 ops/ms Iteration 9: 24337.963 ops/ms Iteration 10: 24660.626 ops/ms Result "com.xncoding.benchmark.string.StringBuilderBenchmark.testStringBuilderAdd": 25687.875 ±(99.9%) 1167.955 ops/ms [Average] (min, avg, max) = (22934.211, 25687.875, 28704.541), stdev = 1345.019 CI (99.9%): [24519.920, 26855.830] (assumes normal distribution) # Run complete. Total time: 00:04:08 Benchmark Mode Cnt Score Error Units StringBuilderBenchmark.testStringAdd thrpt 20 9001.776 ± 253.496 ops/ms StringBuilderBenchmark.testStringBuilderAdd thrpt 20 25687.875 ± 1167.955 ops/ms
仔细看,三大部分,第一部分是字符串用加号连接执行的结果,第二部分是StringBuilder执行的结果,第三部分就是两个的简单结果比较。这里注意我们forks传的2,所以每个测试有两个fork结果。
前两部分是一样的,简单说下。首先会写出每部分的一些参数设置,然后是预热迭代执行(Warmup Iteration), 然后是正常的迭代执行(Iteration),最后是结果(Result)。这些看看就好,我们最关注的就是第三部分, 其实也就是最终的结论。千万别看歪了,他输出的也确实很不爽,error那列其实没有内容,score的结果是xxx ± xxx,单位是每毫秒多少个操作。可以看到,StringBuilder的速度还确实是要比String进行文字叠加的效率好太多。
注解介绍
好了,当你对JMH有了一个基本认识后,现在来详细解释一下前面代码中的各个注解含义。
@BenchmarkMode
基准测试类型。这里选择的是Throughput也就是吞吐量。根据源码点进去,每种类型后面都有对应的解释,比较好理解,吞吐量会得到单位时间内可以进行的操作数。
- Throughput: 整体吞吐量,例如“1秒内可以执行多少次调用”。
- AverageTime: 调用的平均时间,例如“每次调用平均耗时xxx毫秒”。
- SampleTime: 随机取样,最后输出取样结果的分布,例如“99%的调用在xxx毫秒以内,99.99%的调用在xxx毫秒以内”
- SingleShotTime: 以上模式都是默认一次 iteration 是 1s,唯有 SingleShotTime 是只运行一次。往往同时把 warmup 次数设为0,用于测试冷启动时的性能。
- All(“all”, “All benchmark modes”);
@Warmup
上面我们提到了,进行基准测试前需要进行预热。一般我们前几次进行程序测试的时候都会比较慢, 所以要让程序进行几轮预热,保证测试的准确性。其中的参数iterations也就非常好理解了,就是预热轮数。
为什么需要预热?因为 JVM 的 JIT 机制的存在,如果某个函数被调用多次之后,JVM 会尝试将其编译成为机器码从而提高执行速度。所以为了让 benchmark 的结果更加接近真实情况就需要进行预热。
@Measurement
度量,其实就是一些基本的测试参数。
- iterations 进行测试的轮次
- time 每轮进行的时长
- timeUnit 时长单位
都是一些基本的参数,可以根据具体情况调整。一般比较重的东西可以进行大量的测试,放到服务器上运行。
@Threads
每个进程中的测试线程,这个非常好理解,根据具体情况选择,一般为cpu乘以2。
@Fork
进行 fork 的次数。如果 fork 数是2的话,则 JMH 会 fork 出两个进程来进行测试。
@OutputTimeUnit
这个比较简单了,基准测试结果的时间类型。一般选择秒、毫秒、微秒。
@Benchmark
方法级注解,表示该方法是需要进行 benchmark 的对象,用法和 JUnit 的 @Test 类似。
@Param
属性级注解,@Param 可以用来指定某项参数的多种情况。特别适合用来测试一个函数在不同的参数输入的情况下的性能。
@Setup
方法级注解,这个注解的作用就是我们需要在测试之前进行一些准备工作,比如对一些数据的初始化之类的。
@TearDown
方法级注解,这个注解的作用就是我们需要在测试之后进行一些结束工作,比如关闭线程池,数据库连接等的,主要用于资源的回收等。
@State
当使用@Setup参数的时候,必须在类上加这个参数,不然会提示无法运行。
State 用于声明某个类是一个“状态”,然后接受一个 Scope 参数用来表示该状态的共享范围。 因为很多 benchmark 会需要一些表示状态的类,JMH 允许你把这些类以依赖注入的方式注入到 benchmark 函数里。Scope 主要分为三种。
- Thread: 该状态为每个线程独享。
- Group: 该状态为同一个组里面所有线程共享。
- Benchmark: 该状态在所有线程间共享。
关于State的用法,官方的 code sample 里有比较好的例子。
第二个例子
再来看一个更常规一点性能测试的例子,
计算 1 ~ n 之和,比较串行算法和并行算法的效率,看 n 在大约多少时并行算法开始超越串行算法
首先定义一个表示这两种实现的接口:
/**
* Calculator
*
* @author XiongNeng
* @version 1.0
* @since 2018/1/7
*/
public interface Calculator {
/**
* calculate sum of an integer array
*
* @param numbers
* @return
*/
public long sum(int[] numbers);
/**
* shutdown pool or reclaim any related resources
*/
public void shutdown();
}
具体的两种实现代码我就不贴了,主要说明一下串行算法和并行算法实现原理:
- 串行算法:使用 for-loop 来计算 n 个正整数之和。
- 并行算法:将所需要计算的 n 个正整数分成 m 份,交给 m 个线程分别计算出和以后,再把它们的结果相加。
进行 benchmark 的代码如下:
/**
* 自然数求和的串行和并行算法性能测试
*
* @author XiongNeng
* @version 1.0
* @since 2018/1/7
*/
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@State(Scope.Benchmark)
public class SecondBenchmark {
@Param({"10000", "100000", "1000000"})
private int length;
private int[] numbers;
private Calculator singleThreadCalc;
private Calculator multiThreadCalc;
public static void main(String[] args) throws Exception {
Options opt = new OptionsBuilder()
.include(SecondBenchmark.class.getSimpleName())
.forks(1)
.warmupIterations(5)
.measurementIterations(2)
.build();
Collection<RunResult> results = new Runner(opt).run();
ResultExporter.exportResult("单线程与多线程求和性能", results, "length", "微秒");
}
@Benchmark
public long singleThreadBench() {
return singleThreadCalc.sum(numbers);
}
@Benchmark
public long multiThreadBench() {
return multiThreadCalc.sum(numbers);
}
@Setup
public void prepare() {
numbers = IntStream.rangeClosed(1, length).toArray();
singleThreadCalc = new SinglethreadCalculator();
multiThreadCalc = new MultithreadCalculator(Runtime.getRuntime().availableProcessors());
}
@TearDown
public void shutdown() {
singleThreadCalc.shutdown();
multiThreadCalc.shutdown();
}
}
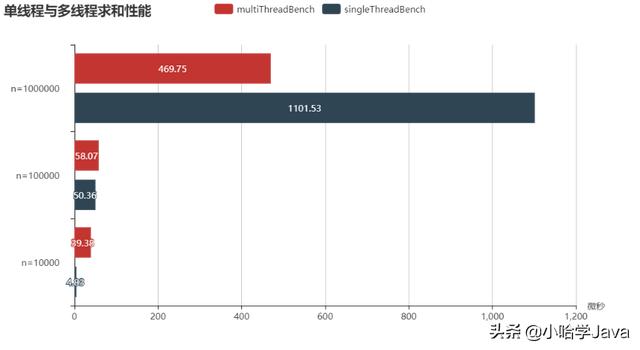
我在自己的笔记本电脑上跑下来的结果,总数在10000时并行算法不如串行算法, 总数达到100000时并行算法开始和串行算法接近,总数达到1000000时并行算法所耗时间约是串行算法的一半左右。
来源:


