时间序列数据库的高级概述,以比较特征、功能、成熟度和性能
黄一泰 -11分钟阅读
照片:Tech Daily on Unsplash
我们正生活在数据库的黄金时代,因为资金正以历史性的速度流入该行业(例如,Snowflake、MongoDB、Cockroach Labs、Neo4j)。如果说关系型与非关系型或在线分析处理( OLAP )与在线交易处理(OLTP)之间的争论统治了过去十年,那么一种新类型的数据库一直在稳步增长。根据DB-Engines(一个收集和展示数据库管理系统信息的倡议),自2020年以来,时间序列数据库是增长最快的领域。
时间序列数据库(TSDB)是为摄取、处理和存储有时间戳的数据而优化的数据库。这些数据可能包括来自服务器和应用程序的指标,来自 物联网传感器 的读数,用户在网站或应用程序上的互动,或金融市场的交易活动。时间序列工作负载通常具有以下特点。
- 每个数据点都包括一个时间戳,可用于索引、聚合和采样。这种数据也可以是多维的和相关的。
- 高写入速度(摄取)是首选,以便在高频率下捕获数据。
- 数据的汇总视图(例如,下采样或汇总视图,趋势线)可能比单一数据点提供更多的洞察力。例如,考虑到网络的不可靠或传感器读数的异常值,我们可以在一段时间内某些平均值超过阈值时设置警报,而不是在单个数据点上这样做。
- 分析数据通常需要在某个时间窗口内访问它(例如,给我过去一周的点击率数据)。
虽然其他数据库也能在一定程度上处理时间序列数据,但TSDB的设计考虑到了上述特性,以更有效地处理数据的摄入、压缩和按时间聚合。那么,随着云计算、物联网和机器学习的发展,对时间序列数据的需求不断爆发,架构师应该如何选择TSDB?在这篇文章中,我们将比较一些流行的TSDB以及市场上的新玩家,以帮助你做出决定。
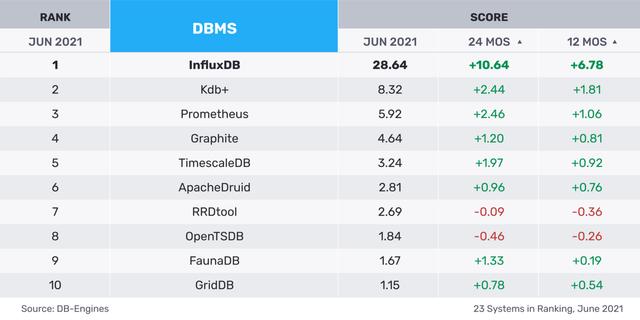
InfluxDB
InfluxDB于2013年首次发布,现在是TSDB领域当之无愧的市场领导者,超过了之前的Graphite和OpenTSDB。与许多开放源码数据库公司一样,InfluxDB以MIT许可的方式授权给单节点,InfluxDB云和InfluxDB企业的付费计划则提供了集群和其他生产就绪的功能。
图片来源:influxdata, (MIT)
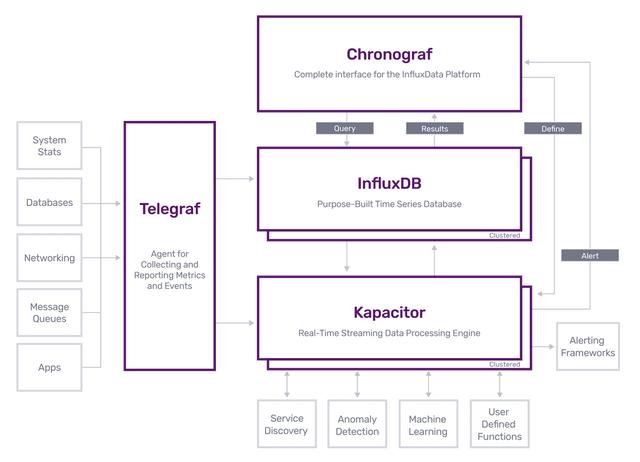
在2019年InfluxDB 2.x发布之前,InfluxDB平台由TICK栈组成。Telegraf(收集和报告指标的代理)、InfluxDB、Chronograf(从InfluxDB查询数据的接口)和Kapacitor(实时流数据处理引擎)。如下图所示,InfluxDB 1.x主要专注于来自服务器和网络应用的时间序列数据。在Prometheus出现并抢占这一领域的市场份额之前,InfluxDB拥有最大的社区和集成,可以收集、存储和查看应用程序的指标。
图片来源:influxdata, (MIT)
InfluxDB 2.x在很大程度上简化了架构,将TICK堆栈捆绑到一个单一的二进制文件中,并引入了新的功能,使收集(如本地Prometheus插件)、组织(如组织和桶)和可视化(如数据浏览器)数据与它的Flux语言。
为了理解InfluxDB的工作原理,我们需要掌握以下关键概念。
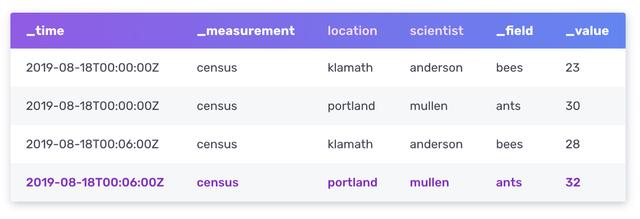
- 数据模型(标签集模型) 。除了时间戳字段外,每个数据元素由各种标签(可选、可索引的元数据字段)、字段(键和值)和测量(标签、字段和时间戳的容器)组成。下面的例子采取了蜜蜂和蚂蚁的普查数据,由科学家Anderson和Mullen在Klamath和Portland收集。这里 位置 和 科学家 是标签,属于蜜蜂和蚂蚁的普查测量,有字段/值对。
图片来源:influxdata, (MIT)
- 数据模式(TSM和 TSI ) :数据元素存储在时间结构的合并树(TSM)和时间序列索引(TSI)文件中。TSM可以被认为是一个LSM树,有写头日志(WAL)和类似于SSTables的只读文件,这些文件是经过排序和压缩的。TSI是InfluxDB内存映射在磁盘上的文件的索引,以利用操作系统的最小最近使用( LRU )内存。这是为了帮助处理具有高cardinality(即集合中的大元素)的数据集。
- Flux脚本语言: 由InfluxDB开发的特定领域语言,帮助查询数据。Flux有一个sql包,也可以帮助从SQL数据源查询。
最值得注意的是,InfluxDB在输入数据之前不强制执行模式。相反,模式是由输入数据自动创建的,从标签和字段中推断出来。这种类似NoSQL的体验既是InfluxDB的优势,也是它的劣势。对于自然适合这种标签集模型的相对较低的数据集(例如,大多数基础设施和应用指标,一些物联网数据,一些金融数据),InfluxDB非常容易上手,而不必担心设计模式或索引的问题。在目标是创建物理资产的数字模型的用例中,它也大放异彩。例如,在物联网中,人们可能需要创建一个数字孪生体来表示 传感器 的集合,并以一种有组织的方式摄取数据。

图片来源:TimescaleDB, (Apache)
另一方面,当数据集需要对连续字段进行索引(即InfluxDB不支持数字,因为标签必须是字符串)或数据验证时,”无模式 “可能是一个不利因素。另外,由于标签是有索引的,如果标签经常变化(例如,元数据在最初摄入后可能发生变化的用例),依靠InfluxDB来推断模式可能是昂贵的。
最后,InfluxDB决定创建自己的自定义功能数据脚本语言(Flux),为掌握这个生态系统带来了另一层复杂性。InfluxDB的团队指出,从类似SQL的InfluxQL转向Flux有两个动机。
- 时间序列数据符合基于流程的功能处理模型,其中数据流从一个输出转化到下一个。SQL支持的关系代数模型并不能很好地处理这种操作和函数的连锁关系。
- InfluxDB希望对时间序列数据的常见操作(如指数移动平均)提供一流的支持,而这并不是SQL标准的一部分。
Flux的语法肯定需要一些努力来适应,特别是如果你正在寻找简单的SQL查询或不希望学习另一种新的语言。但考虑到InfluxDB的大型社区和集成,Flux的一些优势开始显现,特别是当与内置的仪表盘相结合时。
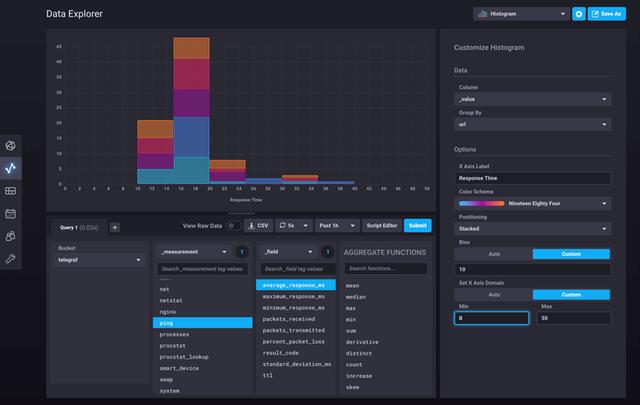
图片来源:influxdata, (MIT)
总的来说,如果时间序列数据与标签集模型非常吻合,InfluxDB是一个不错的选择。主要的用例似乎是面向基础设施/应用监控,但作为这一领域明显的市场领导者,InfluxDB也与流行的数据源无缝集成。
- 优点 :无模式的摄取,巨大的社区,与流行工具的集成。
- 缺点 :高基数的数据集,自定义查询/处理语言
TimeScale数据库
InfluxDB选择了从头开始建立一个新的数据库和自定义语言,而另一端是TimescaleDB。TimescaleDB建立在PostgreSQL之上,并增加了一个称为 hypertable 的中间层,将数据分块到多个底层表格,同时将其抽象为一个单一的大表格,以便与数据进行交互。

图片来源:TimescaleDB, (Apache)
PostgreSQL 的兼容性是TimescaleDB的最大卖点。TimescaleDB完全支持所有的SQL功能(如连接,二级和部分索引),以及流行的扩展,如PostGIS。更重要的是,TimescaleDB继承了几十年来运行SQL查询的开发人员以及大规模运行PostgreSQL的数据库和系统管理员的知识。由于TimescaleDB可以被视为PostgreSQL的扩展,除了TimescaleDB自己的管理产品外,云管理选项(如 Azure Database for PostgreSQL,Aiven)也是现成的,更不用说虚拟机或容器上的无数自我管理选项。
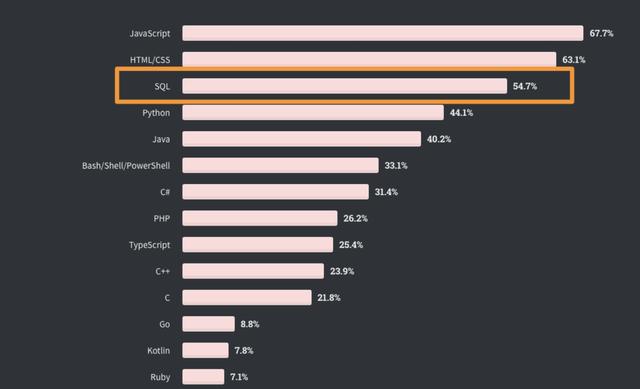
图片来源:2020年Stack Overflow开发者调查,(ODbL)。
因为TimescaleDB一开始是作为一个物联网平台,他们一开始实际上是用InfluxDB来存储他们的传感器数据,它的功能对物联网时间序列数据来说是个好兆头,这些数据往往是突发的,由于网络不可靠而经常失序,并且具有高基数的特点。
- 超量表。 TimescaleDB根据时间列以及其他”空间 “值(如设备UID、位置标识符或股票符号)将其超量表划分为若干块。”空间 “值(如这些块可以被配置为在内存中保存最新的数据,按时间列异步压缩和重新排序数据到磁盘(而不是摄取时间),并在节点间进行复制或迁移。
- 连续聚合。 TimescaleDB还支持数据的连续聚合,以使计算关键指标,如每小时的平均值、最小值和最大值变得快速。物联网数据通常在聚合时更有用(例如,给我下午3点和4点之间的平均温度与下午3点的确切温度),所以不需要在每个聚合查询中扫描大量数据,可以帮助创建高性能的仪表板或分析。
- 数据保留。 在传统的 关系型数据库 中,大量的删除是一个昂贵的操作。然而,由于TimescaleDB将数据存储在块中,它提供了 drop_chunks 功能来快速删除旧数据,而没有同样的开销。由于旧数据的相关性随着时间的推移而减少,TimescaleDB可以与长期存储(如OLAP或blob存储)一起使用,移动旧数据以节省磁盘空间,并保持新数据的高性能。
至于性能,TimescaleDB有一个全面的帖子,详细介绍了使用时间序列基准套件(TSBS)比较TimescaleDB 1.7.1版本和InfluxDB 1.8.0(都是OSS版本)的插入和读取延迟指标。这两个数据库现在都有2.x版本,所以这个分析可能有点过时了,但结果显示,随着数据cardinality的增长,TimescaleDB的性能更优越(约3.5倍的性能)。
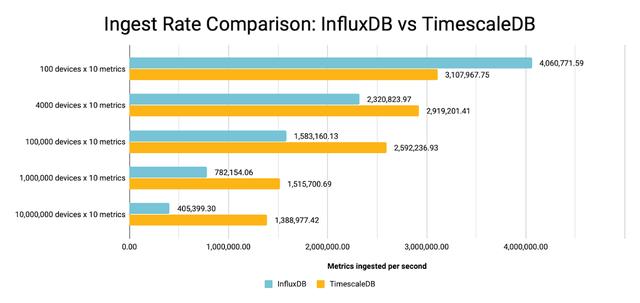
图片来源:TimescaleDB, (Apache)
TimescaleDB团队指出,InfluxDB的基于日志结构的合并树系统(TSI)与TimescaleDB的B树索引方法相比,是根本原因。然而,这里的启示不一定是TimescaleDB在性能上优于InfluxDB。性能基准是有意见的,而且受数据模型、硬件和配置的影响很大。相反,这个结果表明,TimescaleDB可能更适合于物联网的使用案例,在那里数据基数很高(例如,给我1000万台设备中的X设备的平均用电量)。
总的来说,TimescaleDB非常适合那些正在寻找一个巨大的性能提升而不需要重构的团队,以迁移出他们现有的 SQL数据库 。尽管TimescaleDB仍然相对较新(2017年首次发布),但在PostgreSQL基础上构建的决定已经提升了其采用数量,达到了前5名的TSDB。从轶事来看,我之前的物联网创业公司也使用TimescaleDB作为中间数据存储,以快速提取跨越几个月的聚合指标,并将旧数据转移到长期存储。由于我们已经在Kubernetes集群上运行PostgreSQL,安装TimescaleDB和迁移我们的工作负载,是一个简单的任务。
- 优点 。与PostgreSQL兼容,能很好地扩展数据量,有多种部署模式可供选择。
- 缺点 :固定的模式(增加了一点复杂性,而且在摄入前需要进行数据转换)。
QuestDB
对于那些希望利用InfluxDB线路协议的灵活性和PostgreSQL的熟悉性的人来说,一个较新的时间序列数据库可能会满足这两个要求而不牺牲性能。QuestDB(YC S20)是一个用Java和C++编写的开源TSDB,虽然它推出不到一年,但现在已经排名前15位。在引擎下,QuestDB利用内存映射文件,在数据提交到磁盘之前支持快速读写。
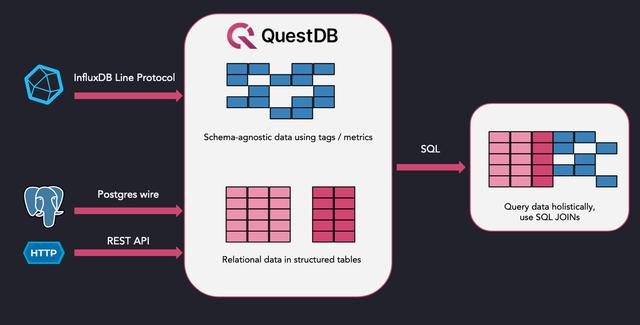
图片来源。QuestDB, (Apache)
通过用Java和C++从头开始建立数据库,QuestDB团队专注于三件事。
- 性能。 解决摄取的瓶颈,特别是在高cardinality数据集周围。它还支持快速数据检索,方法是始终按顺序存储时间分区数据(通过在内存中洗牌),并且只分析所请求的列/分区而不是整个表。最后,QuestDB应用SIMD指令来并行化操作。
- 兼容性。 QuestDB支持InfluxDB线协议、PostgreSQL线、REST API和CSV上传,以摄入数据。习惯于使用其他TSDB的用户可以很容易地移植他们现有的应用程序,而不需要大幅重写。
- 通过SQL进行查询。 尽管支持多种摄取机制,QuestDB使用SQL作为查询语言,因此不需要学习像Flux这样的特定领域语言。
在性能方面,QuestDB最近发布了一篇博文,显示了基准测试结果,实现了每秒140万行的写入速度。QuestDB团队使用TSBS基准,在AWS的m5.8xlarge实例上使用多达14个工程的cpu-only用例( 注意:140万的数字来自使用AMD Ryzen5处理器 )。

图片来源。QuestDB, (Apache)
对于具有高基数(>1000万)的数据集,QuestDB的表现也优于其他TSDB,其峰值摄取吞吐量为904k行/秒,在使用英特尔至强CPU的m5.8xlarge实例上使用4个线程,在1000万设备上维持约640k行/秒。当在AMD Ryzen 3970X上运行相同的基准时,QuestDB显示出超过一百万行/秒的摄取吞吐量。
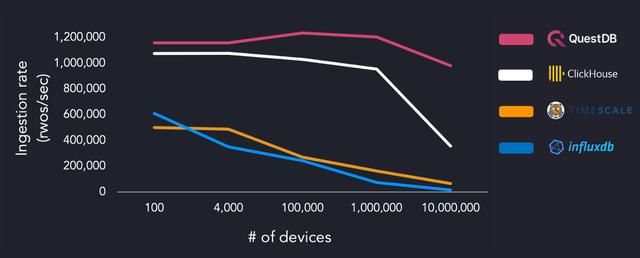
图片来源。QuestDB, (Apache)
基于数据模型和数据库的调整,性能基准可以是主观的,但它还是为QuestDB描绘了一个引人注目的比较点。由于InfluxDB和TimescaleDB都支持TSBS开箱即用的这些用例,看看结果如何,将会很有趣。
QuestDB的另一个有趣的组成部分是支持InfluxDB内联协议和PostgreSQL线程的摄取。对于现有的InfluxDB用户,你可以简单地配置Telegraf以指向QuestDB’的地址和端口。同样,对于PostgreSQL用户,使用现有的客户端库或 JDBC 将数据写入QuestDB中。无论采用哪种摄取方法,都可以使用标准SQL进行数据查询,但API参考页上列出了一些明显的例外。
作为这个领域的新进入者,QuestDB最明显的缺点是缺乏对基础设施功能的支持(如复制、自动备份/恢复)。它确实已经与一些最流行的工具(如PostgreSQL、Grafana、Kafka、Telegraf、Tableau)集成,但它需要一些时间才能达到上述其他TSDB的水平。
尽管如此,QuestDB仍是一个很有前途的项目,可以平衡InfluxDB和TimescaleDB的积极因素。
- 优点 :快速摄取(特别是对于高cardinality的数据集),支持InfluxDB协议和PostgreSQL线,通过标准SQL进行查询
- 缺点 :社区规模较小,可用的集成,生产准备就绪。
总结
随着对时间序列数据的需求不断增长,专门处理这些数据的TSDB将被大量采用,同时也将面临激烈的竞争。除了本文涉及的三个开源TSDB,还有来自AWS(AWS Timestream)和Azure(Azure Series Insights)的公共云产品。
与所有数据库一样,选择 “完美 “的TSDB主要取决于你的业务需求、数据模型和使用情况。如果你的数据符合taget模型,InfluxDB就能很好地工作,并且有一个丰富的集成生态系统可以使用。TimescaleDB是现有PostgreSQL用户的自然选择。最后,如果性能是主要关注点,QuestDB是一个有前途的项目,正在快速增长。


