Hadoop 附带一个名为 HDFS ( HADOOP分布式文件系统 )的 分布式文件系统, 基于HADOOP的应用程序利用HDFS。HDFS设计用于存储在商用硬件集群上运行的非常大的数据文件。它具有容错性,可扩展性,并且扩展极其简单。
当数据超过单个物理机器上的存储容量时,必须将其划分为多台独立的计算机。管理跨机器网络的存储特定操作的 文件系统 称为 分布式文件系统 。
- 读操作
- 写操作
- 使用 Java API访问HDFS
- 使用命令行接口访问HDFS
HDFS集群主要由 管理文件系统 元数据 的 NameNode 和 存储 实际数据 的 DataNode组成 。
- NameNode: NameNode可以视为系统的主节点。它维护文件系统树以及系统中存在的所有文件和目录的元数据。两个文件的 “命名空间图像” 和 “编辑日志” 用于存储元数据信息。Namenode了解包含给定文件的数据块的所有数据节点,但是它不会持久存储块位置。系统启动时,每次从数据节点重建此信息。
- DataNode: DataNode是驻留在集群中每台计算机上的从属服务器,提供实际存储。它负责为客户提供服务,读写请求。
HDFS中的读/写操作在块级操作。HDFS中的数据文件被分成块大小的块,这些块作为独立单元存储。默认块大小为64 MB。
HDFS基于数据复制的概念运行,其中创建数据块的多个副本并将其分布在整个集群中的节点上,以在节点发生故障时实现数据的高可用性。
HDFS中的文件小于单个块,不会占用块的完整存储空间。
在HDFS中读取操作
数据读取请求由HDFS,NameNode和DataNode提供。让我们称读者为“客户”。下图描绘了Hadoop中的文件读取操作。
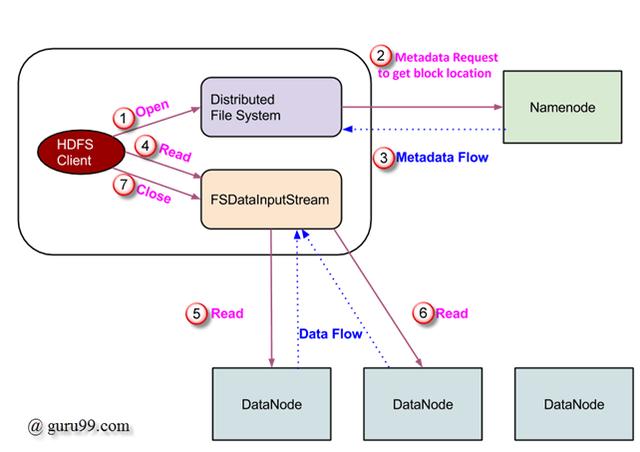
- 客户端通过调用 FileSystem对象的 ‘open()’ 方法来启动读取请求 ; 它是 DistributedFileSystem 类型的对象 。
- 此对象使用 RPC 连接到namenode,并获取元数据信息,例如文件块的位置。请注意,这些地址是前几个文件块。
- 响应于该元数据请求,返回具有该块的副本的DataNode的地址。
- 一旦接收到DataNode的地址,就会将类型为 FSDataInputStream 的对象 返回给客户端。 FSDataInputStream 包含 DFSInputStream ,它负责与DataNode和NameNode的交互。在上图所示的步骤4中,客户端调用 ‘read()’ 方法,该方法使 DFSInputStream 与第一个DataNode与第一个文件块建立连接。
- 以流的形式读取数据,其中客户端 重复调用 ‘read()’ 方法。 read() 操作的这个过程 一直持续到块结束。
- 到达块结束后,DFSInputStream关闭连接并继续查找下一个块的下一个DataNode
- 一旦客户端完成了读取操作,它就会调用 close() 方法。
在HDFS中写入操作
在本节中,我们将了解如何通过文件将数据写入HDFS。
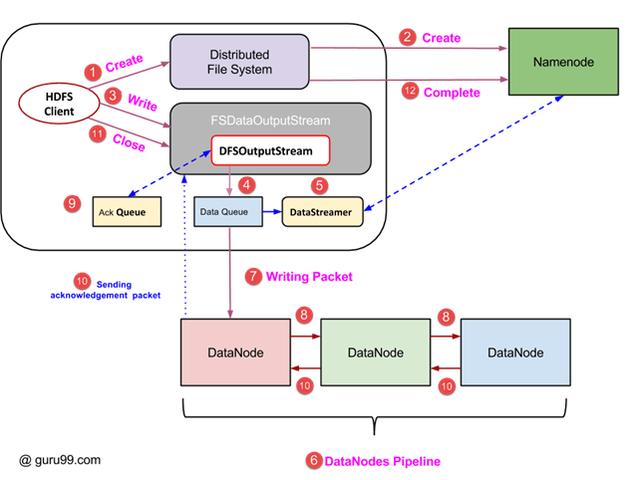
- 客户端通过调用DistributedFileSystem对象的’create()’方法启动写操作,该方法创建一个新文件 – 步骤号。上图中的1。
- DistributedFileSystem对象使用RPC调用连接到NameNode并启动新文件创建。但是,此文件创建操作不会将任何块与文件关联。NameNode负责验证文件(正在创建)是否已经存在,并且客户端具有创建新文件的正确权限。如果文件已存在或客户端没有足够的权限来创建新文件,则会 向客户端抛出 IOException 。否则,操作成功,NameNode将创建该文件的新记录。
- 一旦创建了NameNode中的新记录,就会将类型为FSDataOutputStream的对象返回给客户端。客户端使用它将数据写入HDFS。调用数据写入方法(图中的步骤3)。
- FSDataOutputStream包含DFSOutputStream对象,该对象负责与DataNodes和NameNode的通信。当客户端继续写入数据时, DFSOutputStream 继续使用此数据创建数据包。这些数据包被排入队列,称为 DataQueue 。
- 还有一个名为 DataStreamer的 组件使用 此 DataQueue 。DataStreamer还要求NameNode分配新块,从而选择用于复制的理想DataNode。
- 现在,复制过程从使用DataNodes创建管道开始。在我们的例子中,我们选择了3的复制级别,因此管道中有3个DataNode。
- DataStreamer将数据包注入管道中的第一个DataNode。
- 管道中的每个DataNode都存储由它接收的数据包,并将其转发到管道中的第二个DataNode。
- 另一个队列“Ack Queue”由DFSOutputStream维护,用于存储等待DataNode确认的数据包。
- 一旦从管道中的所有DataNode收到对队列中的数据包的确认,就会从“Ack队列”中删除它。如果任何DataNode发生故障,来自此队列的数据包将用于重新启动操作。
- 在客户端完成写入数据后,它调用close()方法(图中的步骤9)调用close(),结果将剩余的数据包刷新到管道,然后等待确认。
- 收到最终确认后,将联系NameNode告诉它文件写入操作已完成。
使用JAVA API访问HDFS
在本节中,我们尝试了解用于访问Hadoop文件系统的Java接口。
为了以编程方式与Hadoop的文件系统进行交互,Hadoop提供了多个JAVA类。名为org.apache.hadoop.fs的包中包含用于处理Hadoop文件系统中的文件的类。这些操作包括打开,读取,写入和关闭。实际上,Hadoop的文件API是通用的,可以扩展为与HDFS以外的其他文件系统进行交互。
以编程方式从HDFS读取文件
Object java.net.URL 用于读取文件的内容。首先,我们需要让Java识别Hadoop的hdfs URL方案。这是通过 在URL对象上调用 setURLStreamHandlerFactory 方法并将 FsUrlStreamHandlerFactory 的实例传递给它来完成的。此方法每个JVM只需执行一次,因此它包含在静态块中。
一个示例代码是 –
公共类URLCat {
静态的 {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String [] args)throws Exception {
InputStream in = null;
尝试{
in = new URL(args [0])。openStream();
IOUtils.copyBytes(in,System.out,4096,false);
} finally {
IOUtils.closeStream(IN);
}
}
}
此代码打开并读取文件的内容。HDFS上此文件的路径作为命令行参数传递给程序。
使用命令行接口访问HDFS
这是与HDFS交互的最简单方法之一。命令行界面支持文件系统操作,如读取文件,创建目录,移动文件,删除数据和列出目录。
我们可以运行 ‘$ HADOOP_HOME / bin / hdfs dfs -help’ 来获取每个命令的详细帮助。这里, ‘dfs’ 是HDFS的shell命令,它支持多个子命令。
下面列出了一些广泛使用的命令以及每个命令的一些细节。
1.将文件从本地文件系统复制到HDFS
$ HADOOP_HOME / bin / hdfs dfs -copyFromLocal temp .txt /
此命令将文件temp.txt从本地文件系统复制到HDFS。
2.我们可以使用 -ls 列出目录中的文件
$ HADOOP_HOME / bin / hdfs dfs -ls /

我们可以看到 ‘/’ 目录 下列出的文件 ‘temp.txt’ (先前复制过) 。
3.从HDFS将文件复制到本地文件系统的命令
$ HADOOP_HOME / bin / hdfs dfs -copyToLocal /temp.txt

我们可以看到 temp.txt被 复制到本地文件系统。
4.用于创建新目录的命令
$ HADOOP_HOME / bin / hdfs dfs -mkdir / mydirectory
检查目录是否已创建。


