先从经典的双重检查锁代码谈起,如图:

众所周知,这种单例处理在多线程环境下是不安全的,因为一个对象的创建会有多条指令,大概步骤:
1.分配内存
2.虚拟机将分配到的空间初始化为默认值(字段默认值)
3.设置对象头,执行init方法,初始化实例数据
4.指针引用赋值
其中 步骤3,4允许重排序,同时步骤2初始化默认值,为程序提供最小安全保证,即成员域要么为0,null或false
步骤3,4允许重排序导致另一个线程会获取还未初始化实例数据的对象
那对象创建后,其内存结构是怎么样的呢 ?
Java 对象由如下三部分组成:
1. 对象头:Mark word和klasspointer两部分组成,如果是数组,还包括数组长度
2. 实例数据
3. 对齐填充
Java对象占用空间是8字节对齐的,即所有Java对象占用字节数必须是8的倍数,这个特点也是可以实现压缩指针的基础
这里具体的代码验证,可以看上一篇:
这里具体谈谈对内存布局的优化,优化主要是节省内存空间,主要体现在对象实例字段的排布及压缩指针上。
在创建对象初始化字段域的时候,为节省空间:
1:重排序, JVM在Heap中给对象布局时,会对 field 进行重排序,以节省空间
2:子类和父类的 field 不会混合在一起,并且父类的 field 分配完之后才会给子类的 field 分配空间
参数值 -XX:+/-CompactFields,允许子类变量插入父类变量的空隙中,以节省空间,否则严格按照顺序策略排布
排序策略有三种:
0 :先放入oops(普通对象引用指针),然后再是基本变量类型
field 分配的优先依次顺序是: double > long > int > float > char > short > byte > boolean
1 :先放入基本变量类型,然后放入oops(普通对象引用指针)
2 :父类oops和子类oops尾首相连存储
有个参数 -XX:FieldsAllocationStyle=1 (JDK 8下默认值为‘1’)

改变这个的参数可以改变实例对象中有效信息的存储顺序
但是不管以何种策略 顺序,任何域都不能跨8字节布局(可以理解为8字节一段一段固定大小填充数据),不足可以凑字节 对齐(Alignment), 变量重排减少 内存对齐 机制对内存空间的浪费
为什么要填满8字节,下面会说明原因
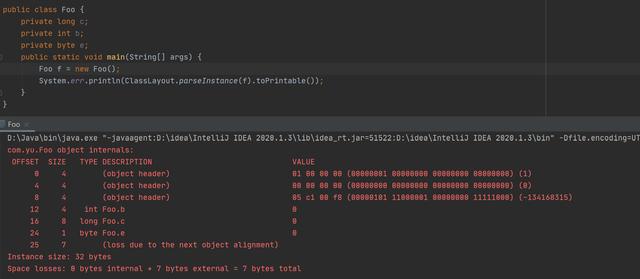
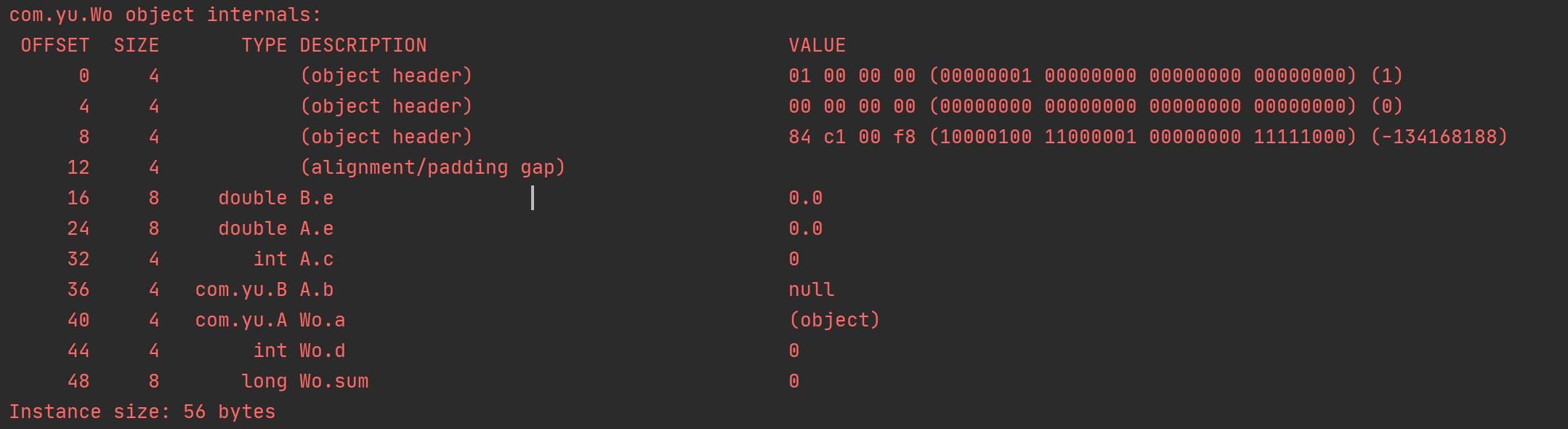
如上图:默认 FieldsAllocationStyle=1 的排序策略下,但 int b却是排在long c前面,这个因为对象头大小占12byte,而数据的填充不能跨8字节的整数倍,已偏移12字节,离16字节还差4字节正好是int类型 大小,
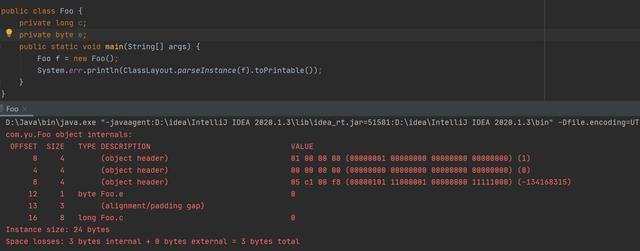
如上图:偏移12字节 + byte 1字节 =13字节, 离16字节还差3字节但没有小字节类型数据,故填充 3 (alignment/padding gap),假如没有排序处理,对象的分布如下:
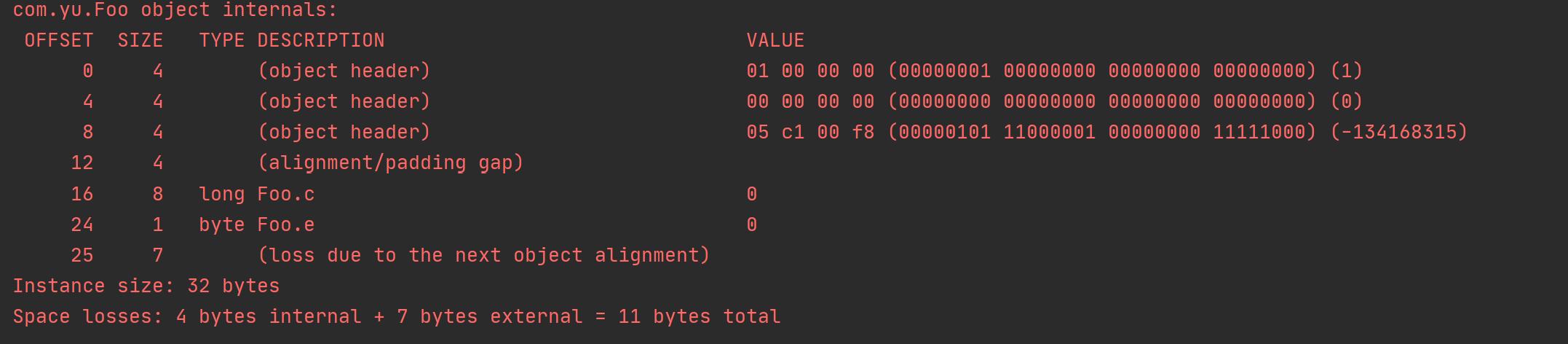
明显可以看出,重排序节省了 8字节。
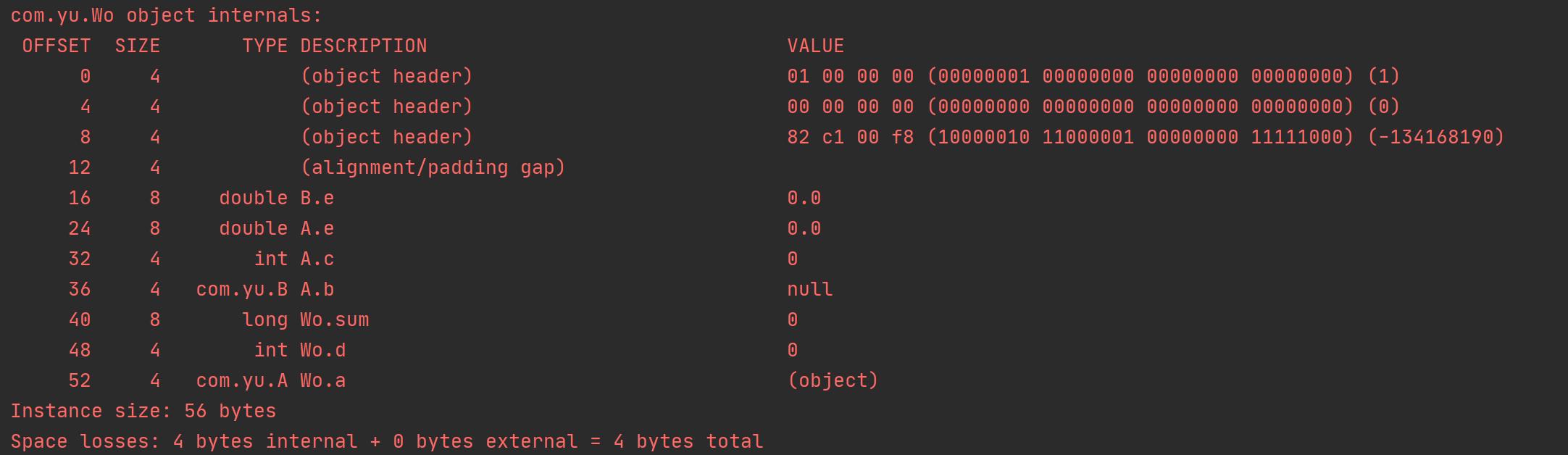
-XX:+CompactFields -XX:FieldsAllocationStyle=1
-XX:+CompactFields -XX:FieldsAllocationStyle=2
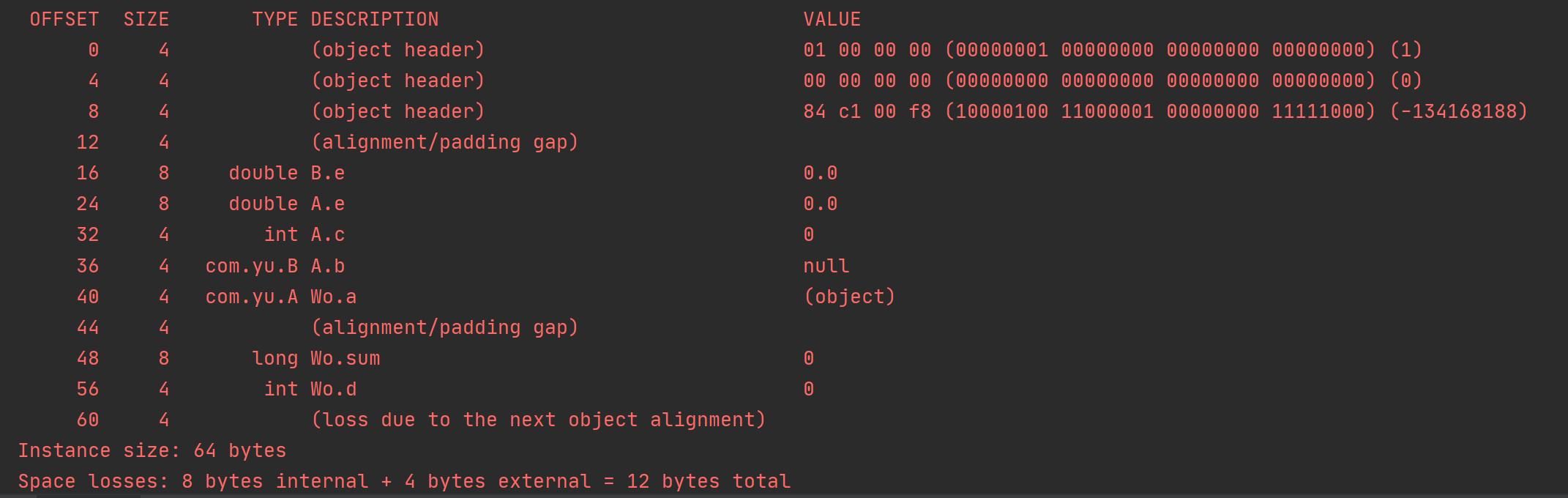
-XX:-CompactFields -XX:FieldsAllocationStyle=2
看上图可知:偏移位置为44时,因为开启了CompactFields,用Wo类 d字段填充以节省空间,而关闭时,严格按照策略顺序排布, 凑字节 对齐。
FieldsAllocationStyle=2时,父类A的B引用b与子类Wo的A引用相连。
当allocation_style的值为2时,父子oop的布局会连续在一起,这样至少有2个好处:
- 减少OopMapBlock的数量。由于GC收集时要扫描存活的对象,所以必须知道对象中引用的内存位置。原始类型不需要扫描。
- 连续的对象区域使得缓存行的使用效率更高。试想如果父对象和子对象的对象引用区域不连续,而中间插入了原始类型字段的话,那么在做GC对象扫描时,很可能需要跨缓存行读取才能完成扫描
压缩指针
有一些参数能影响java对象内存布局,首先是压缩指针,
启动参数增加-XX:-UseCompressedOops关闭指针压缩(默认开启),看到引用的内存占用变成8byte,对象头由12byte变成16byte。
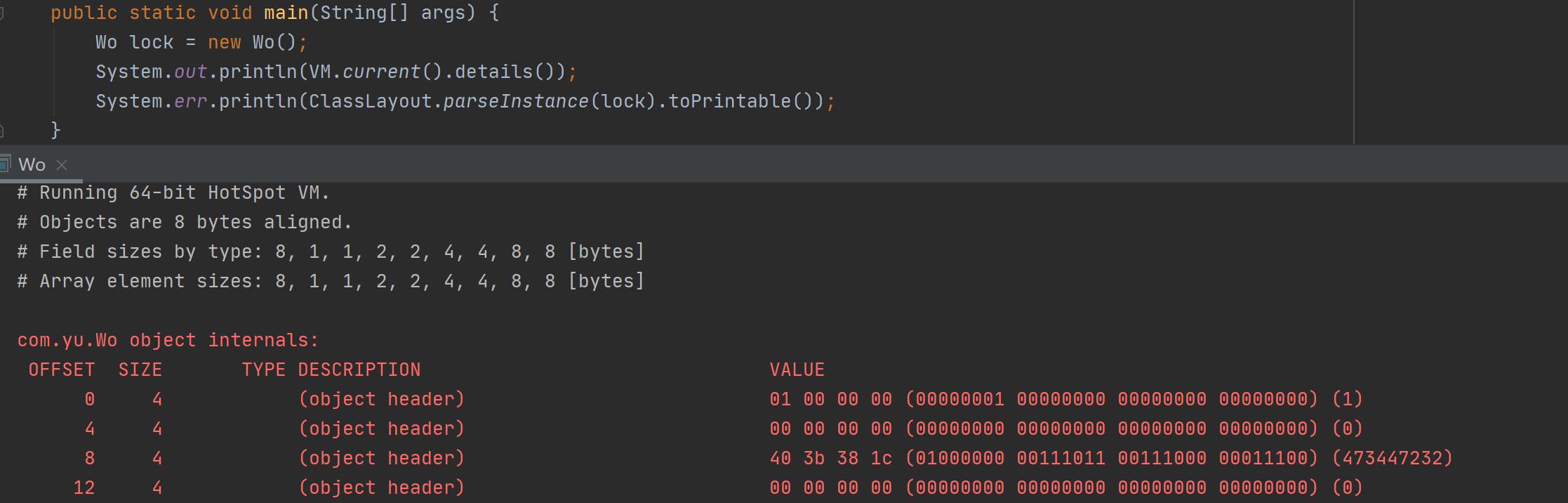
-XX:-UseCompressedOops
为什么要压缩指针
不开启指针压缩的情况下,采用8字节(64位)存储真实内存地址(起始 偏移地址 ),比之前采用4字节(32位)压缩存储地址带来的问题
- 增加了GC开销:64位对象引用需要占用更多的堆空间,留给其他数据的空间将会减少,
从而加快了GC的发生,更频繁的进行GC。 - 降低 CPU缓存 命中率:64位对象引用增大了,CPU能缓存的oop将会更少,从而降低了CPU缓存的效率。
实现压缩指针的原理
主要是利用Java对象8字节对齐特性,每个对象的起始偏移为
00000000 00000000 00000000 00000000 A对象共16字节
00000000 00000000 00000000 00010000 B对象共24字节
00000000 00000000 00000000 00101000
注定后三位都为0,
所以在存储引用的时候统一抹去低位3个零向右移三位,变成
00000000 00000000 00000000 00000000 A对象32位(4字节)起始偏移地址
00000000 00000000 00000000 00000010 B对象32位(4字节)起始偏移地址
00000000 00000000 00000000 00000101
就像用1K代表1000,2K代表2000一样的道理
然后在操作数栈操作的时候,再向左移三位,得到真实地址
000 00000000 00000000 00000000 00000000
000 00000000 00000000 00000000 00010000
000 00000000 00000000 00000000 00101000
所以用32位引用可映射表示35位所表达的数据量,而 2 35 次方等于32G,代表其可以寻址到的最大内存,在此之外的偏移地址寻址不到,其实最大也不是32G,
其111 11111111 11111111 11111111 11111000,表示最大地址, 后三位为0,有8个地址寻址不到,故实际能寻址到的内存为32G-8=31.9G
为什么堆内存大于32G时会失效
通过实现压缩指针的原理可以得知,35位所能表达地址有限,故当堆内存大于32G时,压缩指针将自动失效
压缩指针的关闭及类型
类指针(class pointer):-XX:+/- UseCompressedClassPointers控制
指针指向的 Metaspace空间被称作“Compressed Class Space”。默认大小是1G,但可以通过“CompressedClassSpaceSize”调整,JVM规定这个参数不准大于 3G
-XX:+UseCompressedClassPointers 需要 -XX:+UseCompressedOops 开启的(默认同时开启),所以堆大小要是大于 32G,CompressedOops 自动关闭,CompressedClassPointers 也会关闭的,关闭了就没有 Compressed Class Space 了
普通对象指针( ordinary object pointer ): -XX:+/-UseCompressedOops控制
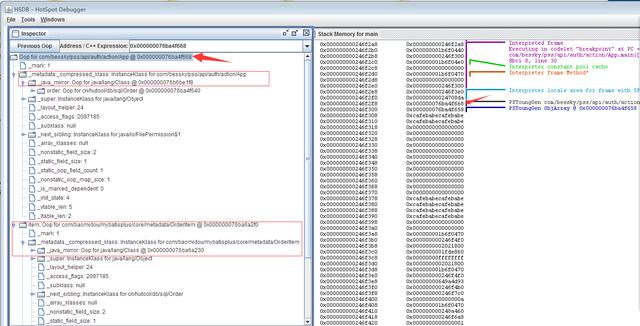
压缩指针在JVM内部只影响klass对象和oop对象的引用
1. the klass field of every object
2. every oop instance field
3. every element of an oop array (objArray)
32位HotSpot VM是不支持UseCompressedOops参数的,只有64位HotSpot VM才支持
压缩指针的副作用
1.增加了OOM异常 java.lang.OutOfMemoryError: Compressed class space
2.影响 java对象内存布局
对象及字段域8个字节倍数对齐的好处
现代计算机中内存的存储理论上都是按照 byte 大小来存储的,但实际上是按照 字长(word size) 为单位存储的。
CPU 为了更快 的 执行代码。于是当从内存中读取数据时,并不是只读自己想要的部分。而是读取足够的字节来填入 高速缓存 行。根据不同的 CPU ,高速缓存行大小不同。如 X86 是 32bytes ,而 ALPHA 是 64bytes 。并且始终在第 32 个字节或第 64 个字节处对齐。这样,当 CPU 访问相邻的数据时,就不必每次都从内存中读取,提高了速度。 因为访问内存要比访问高速缓存用的时间多得多。这个缓存是CPU内部自己的缓存,内部的缓存单位是行,叫做缓存行,同时 字段域8个字节倍数对齐,避免了一个字段被填充到两个缓存行中
减少CPU访问内存的次数,加大CPU访问内存的吞吐量,以空间换时间
伪共享
伪共享是指在一个缓存行内的不同变量,频繁的被两个线程同时修改,造成双方缓存行频繁失效,最终影响数据处理效率。处于伪共享状态的两个变量,操作开销与竞争处理同一个变量相同。
具体原理可以看
处理方式
1:因为64位系统的缓存行是64bytes,要想两个变量互不影响,可以追加变量追加字节的方式填满缓存行,不过,在Java 7 下会淘汰或重新排列无用字段而不生效
2: hotspot在jdk8里提供Contended注解,被该注解标记的变量会在变量前后保持一个 ContendedPaddingWidth 的空白,使得该变量不会和非同一竞争组的变量共享一个缓存行,注解默认只给jdk内部使用,使用 -XX:-RestrictContended 去除限制。
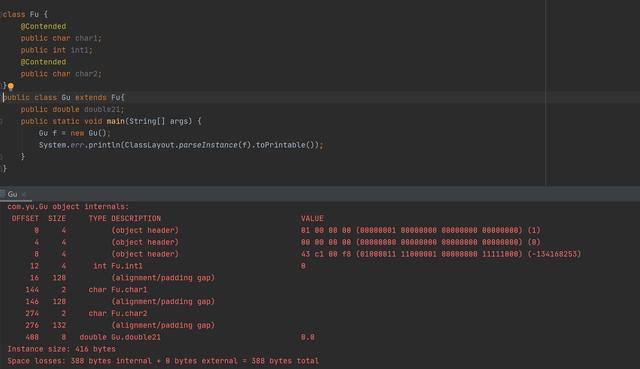
不同缓存行
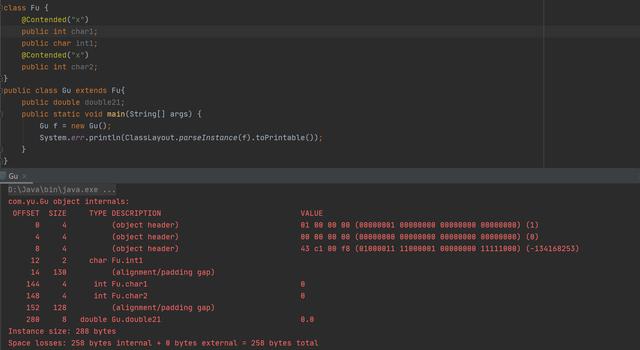
同一竞争缓存行


