本次实验,在 Hadoop 平台上,使用 Mapreduce 实现了数据的全局排序。本文将详细阐述实现所需环境及过程。
- 分布式系统与实践 – 使用 MapReduce 实现数据全局排序
环境配置
使用阿里云服务器安装, OS: Ubuntu20.04 LTS . 本来尝试使用 WSL2,尝试无果。
Install JDK
首先安装 JDK.
sudo apt-get install openjdk-11-jdk Install Hadoop
下面根据 Hadoop 的 官方文档 来安装。
首先检查有没有 ssh 和 pdsh , 没有的话依次安装。
sudo apt-get install ssh
sudo apt-get install pdsh 然后前往 Apache Download Mirrors 寻找合适的 hadoop 版本,然后用 wget 下载.
# 下载链接根据自己的情况替换
wget 解压之。
tar -zxvf hadoop-3.3.1.tar.gz 配置 环境变量 .
# 编辑这个文件,并追加
vim etc/hadoop/hadoop-env.sh
# 路径根据自己的安装路径设置,一般 openjdk 都在 /usr/lib/jvm/<your version>
export Java _HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64
export hdfs _NAMENODE_USER= root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARY NameNode _USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# 根据自己文件夹的位置配置
export HADOOP_HOME=~/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop 尝试运行。
bin/hadoop 如果显示了 Hadoop 的使用文档,就安装成功了。
配置伪 Hadoop 集群
Hadoop 支持用三种模式启动:单机模式、伪分布式模式、分布式集群模式。集群模式我们没有足够的机器,单机模式很难体现出分布式的优势,所以我们选用伪分布式。
Hadoop 可以在单节点上以所谓的伪分布式模式运行,此时每一个 Hadoop 守护进程都作为一个独立的 Java 进程运行。
下面开始配置。
检查无密码 SSH localhost
检查自己能否无密码 ssh localhost . 如果不行的话,就不行。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
sudo service ssh restart Hadoop XML 配置
vim etc/hadoop/core-site.xml:
< Configuration >
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
vim etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration> 注意不能使用 zsh ,如果你跟我一样用的是 zsh ,将默认 shell 改回 bash .
chsh -s /bin/bash 执行官方 Demo 测试
下面看一下官方给的消息 WordCount Demo 测试安装是否成功。
- 初始化分布式文件系统
- bin/hdfs namenode – format
- 启动 NameNode 和 DataNode
- sbin/ start -dfs.sh
- 此时若遇到报错 connection refused , 如下图。
- 如果确认 ssh localhost 可以成功,那么一般是 pdsh 造成的。在 stackoverflow 上找到这样一个 解决办法 。
- 编辑文件 libexec/hadoop-functions.sh ,将这一行:
- if [[ -e ‘/usr/bin/pdsh’ ]] ; then
- 替换为:
- if [[ ! -e ‘/usr/bin/pdsh’ ]] ; then
- 再重新尝试。答主给了两种解决方案,此种方案解决了我的问题。
- 浏览 NameNode 的 Web 界面,默认地址:
- http : //localhost:9870/
- 效果见下图。
- 此时 NameNode 启动成功。
- 配置 HDFS 目录
- bin/hdfs dfs -mkdir / user bin/hdfs dfs -mkdir / user / user # 此处是你执行 NameNode 的 username
- 将 Input 文件复制到 HDFS 中
- 事先准备一个单词文件,例如 input/abc.txt . 将其复制到 HDFS 中。
- bin/hdfs dfs – mkdir wc_input bin/hdfs dfs – put input / abc .txt wc_input
- 执行 Hadoop WordCount 程序
- bin /hadoop jar share/ hadoop / Map reduce/ hadoop-mapreduce-examples- 3.3 . 1 .jar wordcount wc_input wc_output2
- 查看结果
- bin /hdfs dfs -cat wc_output2/ *
- 或者
- bin/hdfs dfs – get wc_output2 wc_output2 cat wc_output2/*
- 如图所示。
具体实现
对每一批文本文档中数字进行排序。并将结果存放于不同的输出文件中,输出文件之间依然保证有序。
存放于 HDFS 上面的一批文本文档。每个文档有 10000 行,文档的每一行是一个数字,每个数字都来自于区间[0, 100000)。
读取数据并排序
Map 端读取文件中的数字,输出中间结果:
static class TotalSortMapper extends Mapper<LongWritable, Text, LongWritable, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IO Exception , InterruptedException {
String line = value.toString().trim();
if (!"".equals(line))
context.write(new LongWritable(Long.parseLong(line)), new LongWritable(1));
}
} Reduce 端输出排序结果:
static class TotalSortReducer extends Reducer<LongWritable, LongWritable, LongWritable, LongWritable> {
static Long idx = 0L;
@Override
protected void reduce(LongWritable key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
for (LongWritable value : values) {
idx += value.get();
context.write(new LongWritable(idx), key);
}
}
} 主函数中,创建相应任务:
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 省略配置行...
job.setJobName("TotalSort");
job.setJarByClass(TotalSort.class);
job.setMapperClass(TotalSortMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(LongWritable.class);
job.setReducerClass(TotalSortReducer.class);
job.setNumReduceTasks(2);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(LongWritable.class);
File InputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
} 执行任务后,由于设置的 Reduce 个数为 2,所以在输出目录中出现两个文件。查看这两个文件的内容可以看到,文件内部的确是按照数字的升序进行排列,但是文件与文件间却不是有序的。
我们知道,MapReduce 过程中,键值对被分配到哪一个分区上是由 Partitioner 决定,默认的 Partitioner 是按照 Key 的 hashcode 对 Reduce 个数取模得到。那如何使输出文件间也保持有序呢?这里提供两个方案:
- 方案一:人工指定分区。
- 方案二:使用 TotalOrderPartitioner 完成分区。
人工指定分区
人工指定分区相对比较简单,即集成 Partitioner 类,完成自定义分区:
static class TotalSortPartitioner extends Partitioner<LongWritable, LongWritable> {
@Override
public int getPartition(LongWritable longWritable, LongWritable longWritable2, int i) {
if (i == 2)
return longWritable.get() > 10000 ? 0 : 1;
return 0;
}
} 这样就可以将大于 10000 的数字分到分区 0,将小于 10000 的数字分到分区 1。但是这样会出现一些严重的问题。
- 数据倾斜
若大部分数据分散在某个区间,会导致任务量向某个 Reduce 倾斜,拉低系统性能,无法很好的利用分布式资源。 - 内存不足
在数据倾斜过于严重时,可能出现 OOM。
使用 TotalOrderPartitioner 完成分区
我们可以使用 Hadoop 提供的自实现 TotalOrderPartitioner 分区器来进行分区采样,避免上述问题。
- 在开始 Map 之前,Mapreduce 首先执行 InputSampler 对样本抽样,并生成 partition files 写入 HDFS。InputSampler 对输入 split 进行抽样,并使用 sortComparator 对抽样结果进行排序。常用 抽样方法 有:
- RandomSampler:按照给定频次,进行 随机抽样 。
- Interval Sampler:按照给定间隔,进行定间隔抽样。
- split Sampler:取每个 split 的前 n 个样本进行抽样。
- InputSampler 在 HDFS 上写入一个 partition file (sequence file),决定不同分区的 key 边界。对于 n 个 Reducer,partition file 有 n-1 个边界数据。Map 的 output 按照 partition file 的边界不同,分别写入对应的分区。
- Mapper 使用 TotalOrderPartitioner 类读取 partition file ,获得每个 Mapper 使用 TotalOrderPartitioner 类。这个类读取 partition file ,确定每个分区的边界。
- 在 shuffle 阶段,每个 Reducer 会拉取对应分区中已排序的 (key, value)。由于每个分区已按照 partition file 设置边界,这样分区 1 中的数据都比分区 2 小,分区 2 数据都比分区 3 小(假设升序排列)。
- Reducer 处理对应分区数据并写入 HDFS 后,输出数据也保持全局有序。
/***
* Map 过程
*/public class TotalSortMap extends Mapper<Text, Text, Text, IntWritable> {
@Override
protected void map(Text key, Text value,
Context context) throws IOException, InterruptedException {
context.write(key, new IntWritable(Integer.parseInt(key.toString())));
}
}
/***
* Reduce 过程
*/public class TotalSortReduce extends Reducer<Text, IntWritable, IntWritable, NullWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
for (IntWritable value : values)
context.write(value, NullWritable.get());
}
}
/***
* 入口函数
*/public class TotalSort extends Configured implements Tool {
//实现一个Kye比较器,用于比较两个key的大小,将key由 字符串 转化为 Integer ,然后进行比较。
public static class KeyComparator extends WritableComparator {
protected KeyComparator() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable writableComparable1, WritableComparable writableComparable2) {
int num1 = Integer.parseInt(writableComparable1.toString());
int num2 = Integer.parseInt(writableComparable2.toString());
return num1 - num2;
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.totalorderpartitioner.naturalorder", "false");
Job job = Job. getInstance (conf, "Total Sort app");
job.setJarByClass(TotalSort.class);
//设置读取文件的路径,都是从 HDFS 中读取。读取文件路径从脚本文件中传进来
FileInputFormat.addInputPath(job,new Path(args[0]));
//设置mapreduce程序的输出路径,MapReduce的结果都是输入到文件中
FileOutputFormat.setOutputPath(job,new Path(args[1]));
job.setInputFormatClass(KeyValueTextInputFormat.class);
//设置比较器,用于比较数据的大小,然后按顺序排序,该例子主要用于比较两个 key 的大小
job.setSortComparatorClass(KeyComparator.class);
job.setNumReduceTasks(3);//设置 reduce 数量
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
//设置保存partitions文件的路径
TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), new Path(args[2]));
//key值采样,0.01是采样率,
InputSampler.Sampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.01, 1000, 100);
//将采样数据写入到分区文件中
InputSampler.writePartitionFile(job, sampler);
job.setMapperClass(TotalSortMap.class);
job.setReducerClass(TotalSortReduce.class);
//设置分区类。
job.setPartitionerClass(TotalOrderPartitioner.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args)throws Exception{
int exitCode = ToolRunner.run(new TotalSort(), args);
System.exit(exitCode);
}
} 打包并执行
通过 Maven 将我们写好的 MapReduce 函数打成 Jar 包。首先配置 main/java/META-INF/MANIFEST.MF .
Manifest-Version: 1.0
Main-Class: TotalSort 通过 Maven 打包。
mvn clean
mvn package 上传到服务器,并准备好测试数据,根据前面的步骤,将数据上传到 HDFS。
hdfs://localhost:9000/user/root/sort-in
hdfs://localhost:9000/user/root/sort-out
hdfs://localhost:9000/user/root/total_sort_partitions
执行我们写好的 MapReduce 函数。
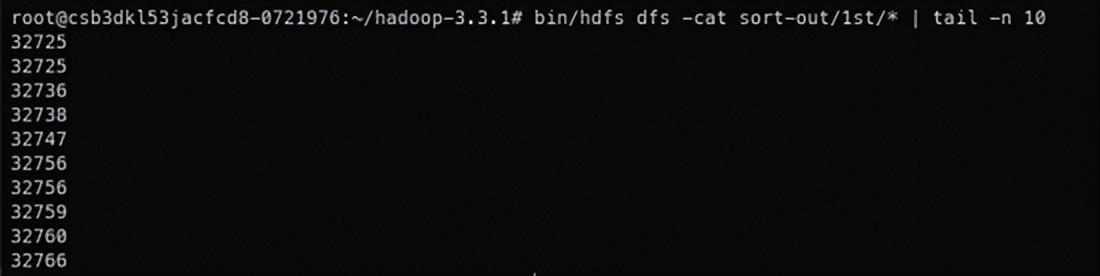
bin/hadoop jar globalsort.jar sort-in sort-out total_sort_partitions 检查排序结果。
bin/hdfs dfs -cat sort-out/*
# 文件太长了,只显示最后十行
bin/hdfs dfs -cat sort-out/* | tail -n 10 部分结果如下图所示。可见数据排序完毕。