
本文是“ Java 秒杀系统实战系列文章”的第七篇,在本文中我们将重点介绍 “在高并发,如秒杀的业务场景下如何生成全局唯一、趋势递增的订单编号”,我们将介绍两种方法,一种是传统的采用随机数生成的方式,另外一种是采用当前比较流行的“ 分布式 唯一ID生成算法-雪花算法”来实现。
在上一篇文章,我们完成了商品秒杀业务逻辑的代码实战,在该代码中,我们还实现了“当用户秒杀成功后,需要在数据库表中为其生成一笔秒杀成功的订单记录”的功能,其对应的代码如下所示:
//通用的方法-记录用户秒杀成功后生成的订单-并进行异步邮件消息的通知
private void commonRecordKillSuccessInfo(ItemKillkill, Integer userId) throws Exception{
//TODO:记录抢购成功后生成的秒杀订单记录
ItemKillSuccess entity=new ItemKillSuccess();
//此处为订单编号的生成逻辑
String orderNo=String.valueOf(snowFlake.nextId());
//entity.setCode(RandomUtil.generateOrderCode()); //传统时间戳+N位随机数
entity.setCode(orderNo);//雪花算法
entity.setItemId(kill.getItemId());
entity.setKillId(kill.getId());
entity.setUserId(userId.toString());
entity.setStatus(SysConstant.OrderStatus.SuccessNotPayed.getCode().byteValue());
entity.setCreateTime(DateTime.now().toDate());
//TODO:学以致用,举一反三 -> 仿照单例模式的双重检验锁写法
if (itemKillSuccessMapper.countByKillUserId(kill.getId(),userId)<= 0){
intres=itemKillSuccessMapper.insertSelective(entity);
//其他逻辑省略
}
}
在该实现逻辑中,其核心要点在于“在高并发的环境下,如何高效的生成订单编号”,那么如何才算是高效呢?Debug认为应该满足以下两点:
1、保证订单编号的生成逻辑要快、稳定,减少时延;
2、要保证生成的订单编号全局唯一、不重复、趋势递增、有时序性。
下面,我们采用两种方式来生成“订单编号”,并自己写一个 多线程 的程序模拟生成的订单编号是否满足条件。
值得一提的是,为了能直观的观察多线程并发生成的订单编号是否具有唯一性、趋势递增,在这里Debug借助了一张数据库表 random_code来存储生成的订单编号,其DDL如下所示:
CREATE TABLE `random_code` ( `id`int(11) NOT NULL AUTO_INCREMENT, `code`varchar(255) DEFAULT NULL, PRIMARY KEY(`id`), UNIQUE KEY`idx_code` (`code`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
从该数据库表数据结构定义语句中可以看出,我们设定了 订单编号字段code 为唯一!所以如果高并发多线程生成的订单编号出现重复,那么在插入数据库表的时候必然会出现错误。
下面,首先开始我们的第一种方式吧:基于随机数的方式生成订单编号。
(1)首先是建立一个Thread类,其run方法的执行逻辑为生成订单编号,并将生成的订单编号插入数据库表中,其代码如下所示:
/**
* 随机数生成的方式-Thread
* @Author:debug (SteadyJack)
* @Date:2019/7/11 10:30
**/public class CodeGenerateThread implementsRunnable{
private RandomCodeMapper randomCodeMapper;
public CodeGenerateThread(RandomCodeMapper randomCodeMapper) {
this.randomCodeMapper = randomCodeMapper;
}
@Override
public void run() {
//生成订单编号并插入数据库
RandomCode entity=new RandomCode();
entity.setCode(RandomUtil.generateOrderCode());
randomCodeMapper.insertSelective(entity);
}
}
其中,RandomUtil.generateOrderCode()的生成逻辑是借助ThreadLocalRandom来实现的,其完整的源代码如下所示:
/** * 随机数生成util
* @Author:debug (SteadyJack)
* @Date:2019/6/20 21:05
**/public class RandomUtil {
private static final SimpleDateFormat dateFormatOne=newSimpleDateFormat("yyyyMMddHHmmssSS");
private static final ThreadLocalRandom random=ThreadLocalRandom.current();
//生成订单编号-方式一
public static String generateOrderCode(){
//TODO:时间戳+N为随机数流水号
return dateFormatOne.format(DateTime.now().toDate()) + generateNumber(4);
}
//N为随机数流水号
public static String generateNumber(final int num){
StringBuffer sb=new StringBuffer();
for(int i=1;i<=num;i++){
sb.append(random.nextInt(9));
}
return sb.toString();
}
}
(2)紧接着是在 BaseController控制器 中开发一个请求方法,目的正是用来模拟前端高并发触发产生多 线程 并生成订单编号的逻辑,在这里我们暂且用1000个线程进行模拟,其源代码如下所示:
@Autowired
private RandomCodeMapper randomCodeMapper;
//测试在高并发下多线程生成订单编号-传统的随机数生成方法
@RequestMapping(value ="/code/generate/thread",method = RequestMethod.GET)
public BaseResponse codeThread(){
BaseResponse response=new BaseResponse(StatusCode.Success);
try {
ExecutorService executorService=Executors.newFixedThreadPool(10);
for (int i=0;i<1000;i++){
executorService.execute(new CodeGenerateThread(randomCodeMapper));
}
}catch(Exception e){
response=new BaseResponse(StatusCode.Fail.getCode(),e. getMessage ());
}
returnresponse;
}
(3)完了之后,就可以将整个项目、系统运行在外置的tomcat中了,然后打开postman,发起一个Http的Get请求,请求链接为:
,仔细观察控制台的输出信息,会看一些令自己躁动不安的东西:
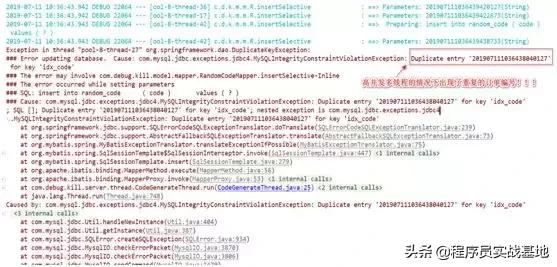
竟然会出现“重复生成了重复的订单编号”!而且,打开数据库表进行观察,会发现“他娘的1000个线程生成订单编号,竟然只有900多个记录”,这就说明了这么多个线程在执行生成订单编号的逻辑期间出现了“重复的订单编号”!如下图所示:
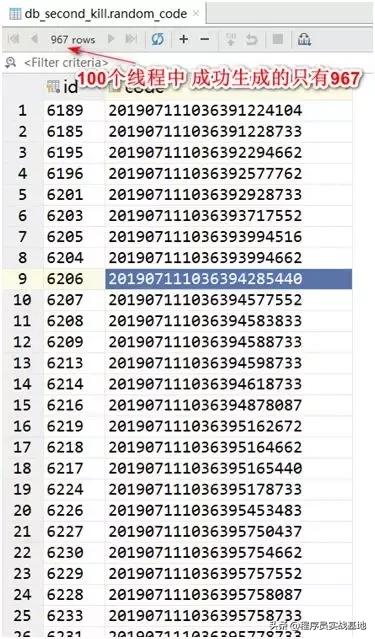
因此,此种基于随机数生成唯一ID或者订单编号的方式,我们是可以Pass掉了(当然啦,在并发量不是很高的情况下,这种方式还是阔以使用的,因为简单而且易于理解啊!)
鉴于此种“基于随机数生成”的方式在高并发的场景下并不符合我们的要求,接下来,我们将介绍另外一种比较流行的、典型的方式,即“分布式唯一ID生成算法-雪花算法”来实现。
对于“雪花算法”的介绍,各位小伙伴可以参考Github上的这一链接,我觉得讲得还是挺清晰的:,详细的Debug在这里就不赘述了,下面截取了部分概述:
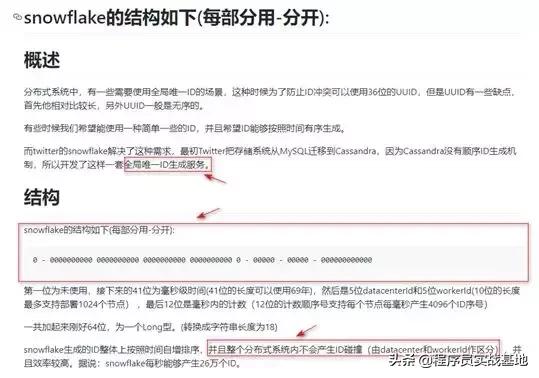
SnowFlake算法在分布式的环境下,之所以能高效率的生成唯一的ID,我觉得其中很重要的一点在于其底层的实现是通过“位运算”来实现的,简单来讲,就是直接跟机器打交道!其底层数据的存储结构(64位)如下图所示:

下面,我们就直接基于雪花算法来生成秒杀系统中需要的订单编号吧!
(1)同样的道理,我们首先定义一个Thread类,其run方法的实现逻辑是借助雪花算法生成订单编号并将其插入到数据库中。
/** 基于雪花算法生成全局唯一的订单编号并插入数据库表中
* @Author:debug (SteadyJack)
* @Date:2019/7/11 10:30
**/public class CodeGenerateSnowThread implementsRunnable{
private static final SnowFlake SNOW_FLAKE=new SnowFlake(2,3);
private RandomCodeMapper randomCodeMapper;
public CodeGenerateSnowThread(RandomCodeMapper randomCodeMapper) {
this.randomCodeMapper = randomCodeMapper;
}
@Override
publicvoid run() {
RandomCode entity=new RandomCode();
//采用雪花算法生成订单编号
entity.setCode(String.valueOf(SNOW_FLAKE.nextId()));
randomCodeMapper.insertSelective(entity);
}
}
其中,SNOW_FLAKE.nextId()的方法正是采用雪花算法生成全局唯一的订单编号的逻辑,其完整的源代码如下所示:
/* 雪花算法
* @author:zhonglinsen
* @date:2019/5/20
*/public class SnowFlake {
//起始的时间戳
private final static long START_STAMP = 1480166465631L;
//每一部分占用的位数
private final static long sequence _BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATA_CENTER_BIT = 5;//数据中心占用的位数
//每一部分的最大值
private final static long MAX_DATA_CENTER_NUM = -1L ^ (-1L << DATA_CENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
//每一部分向左的位移
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT =SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
private long dataCenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStamp = -1L;//上一次时间戳
public SnowFlake(long dataCenterId, long machineId) {
if(dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0) {
throw new IllegalArgumentException("dataCenterId can't be greaterthan MAX_DATA_CENTER_NUM or less than 0");
}
if(machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater thanMAX_MACHINE_NUM or less than 0");
}
this.dataCenterId= dataCenterId;
this.machineId = machineId;
}
//产生下一个ID
public synchronized long nextId() {
long currStamp = getNewStamp();
if(currStamp < lastStamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if(currStamp == lastStamp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStamp = getNextMill();
}
}else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStamp = currStamp;
return (currStamp - START_STAMP) << TIMESTAMP_LEFT //时间戳部分
| dataCenterId << DATA_CENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewStamp();
while(mill <= lastStamp) {
mill = getNewStamp();
}
return mill;
}
private long getNewStamp() {
return System.currentTimeMillis();
}
}
(2)紧接着,我们在BaseController中开发一个请求方法,用于模拟前端触发高并发产生多线程抢单的场景。
/**
* 测试在高并发下多线程生成订单编号-雪花算法
* @return
*/@RequestMapping(value ="/code/generate/thread/snow",method = RequestMethod.GET)
public BaseResponse codeThreadSnowFlake(){
BaseResponse response=new BaseResponse(StatusCode.Success);
try {
ExecutorService executorService=Executors.newFixedThreadPool(10);
for(int i=0;i<1000;i++){
executorService.execute(new CodeGenerateSnowThread(randomCodeMapper));
}
}catch(Exception e){
response=new BaseResponse(StatusCode.Fail.getCode(),e.getMessage());
}
returnresponse;
}
(3)完了之后,我们采用Postman发起一个Http的Get请求,其请求链接如下所示:,观察控制台的输出信息,可以看到“一片安然的景象”,再观察数据库表的记录,可以发现,1000个线程成功触发生成了1000个对应的订单编号,如下图所示:

除此之外,各位小伙伴还可以将线程数从1000调整为10000、100000甚至1000000,然后观察控制台的输出信息以及数据库表的记录等等。
Debug亲测了1w跟10w的场景下是木有问题的,100w的线程数的测试就交给各位小伙伴去试试了(时间比较长,要有心理准备哦!)
至此,我们就可以将雪花算法生成全局唯一的订单编号的逻辑应用到我们的“秒杀处理逻辑”中,即其代码(在KillService的commonRecordKillSuccessInfo方法中)如下所示:
ItemKillSuccess entity=new ItemKillSuccess(); String orderNo=String.valueOf(snowFlake.nextId());//雪花算法 entity.setCode(orderNo); //其他代码省略
Debug有话说
1、目前,这一秒杀系统的整体构建与代码实战已经全部完成了,完整的源代码数据库地址可以来这里下载:记得Fork跟Star啊!!!
2、由于相应的博客的更新可能并不会很快,故而如果有想要快速入门以及实战整套系统的,可以考虑联系Debug获取这一“Java秒杀系统”的完整视频教程(课程是收费的!),当然,大家也可以点击下面这个链接 联系Debug或者加入相应的技术交流群进行交流!
3、实战期间有任何问题都可以留言或者与Debug联系、交流。
推荐阅读:


