基本概念
字符集
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII 字符集、GB2312 字符集、BIG5 字符集、 GB18030 字符集、 Unicode 字符集等。计算机要准确的处理各种字符集文字,就需要进行 字符编码 ,以便计算机能够识别和存储各种文字。
字符编码
字符编码(英语:Character encoding)也称字集码,是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8 位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。
为了理解字符集和字符编码的关系,这里举个简单的例子,我们可以把字符集当成接口,把字符编码当成接口的实现。 Unicode 是接口(字符集), UTF-8 / UTF-16 / UTF-32 则是不同的实现(字符编码)。
ANSI
ANSI 全称(American National Standard Institite)美国国家标准学会(美国的一个非营利组织),首先 ANSI 不是指的一种特定的 编码 ,而是不同地区扩展编码方式的统称,各个国家和地区所独立制定的兼容 ASCII 但互相不兼容的字符编码, 微软 统称为 ANSI 编码。

在简体中文 windows 下使用文本文件保存” 联通 “,则再次打开会显示乱码。这是因为 windows 下的文本文件默认使用 ansi 字符集,而简体中文 windows 下的 ansi 字符集为 GB2312,”联通“两个字的 GB2312 编码看起来和 UTF-8 非常相似,又因为我们没有在文件开头设置字符集标记(BOM),所以当我们再次打开该文件时,被识别为 UTF-8,因此出现乱码。
Unicode
Unicode(统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
- CodeUnit :代码单元/编码单元,是 Unicode 编码里一个 CodePoint 需要的最少字节数例如:UTF-8 是一个字节,UTF-16 是两个字节,UTF-32 是四个字节
- CodePoint :代码点,Unicode 规定的每一个字符就是一个 CodePoint
- CodeSpace :代码空间,所有的代码点构成一个代码空间,根据 Unicode 定义,总共有 1,114,112 个代码点,编号从 0x0-0x10FFFF ,也就是大概 110 多万个字符
- CodePlane :代码平面,Unicode 标准把代码点分成了17 个代码平面,编号为 #0-#16。每个代码平面包含 65,536(2^16)个代码点(17*65,536=1,114,112)。#0 叫做 基本多语言平面 (BMP:大部分常用的字符都坐落在这个平面内,比如 ASCII 字符,汉字等。代码点范围:0x0000-0xFFFF),其余平面叫做 补充平面
- SurrogatePair :代理对,由一个 High-surrogate (高代理代码点: 0xD800-0xDBFF )和一个 Low-surrogate (低代理代码点: 0xDC00-0xDFFF )组成。这 2048 个代码点位于 BMP 内,并且不是有效的字符代码点,它们是为 UTF 编码保留的。在 UTF-16 中它可以编码 BMP 之外的代码点
UTF-8
UTF-8 的特点是对不同范围的字符使用不同长度的编码。对于 0x00-0x7F 之间的字符,UTF-8 编码与 ASCII 编码完全相同。UTF-8 编码的最大长度是 4 个字节。
- 对于单个字节的字符,第一位设为 0,后面的 7 位对应这个字符的 Unicode 码点。
- 对于需要使用 N 个字节来表示的字符(N > 1),第一个字节的前 N 位都设为 1,第 N + 1 位设为0,剩余的 N – 1 个字节的前两位都设位 10,剩下的 二进制 位则使用这个字符的 Unicode 码点来填充。
Unicode 编码(十六进制)UTF-8 字节流(二进制)000000-00007F0xxxxxxx000080-0007FF110xxxxx 10xxxxxx000800-00FFFF1110xxxx 10xxxxxx 10xxxxxx010000-10FFFF11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8 编码的最大长度是 4 个字节。从上表可以看出,4 字节模板有 21 个 x,即可以容纳 21 位二进制数字。Unicode 的最大码位 0x10FFFF 也只有 21 位。
例1:“汉”字的Unicode 编码是 0x6C49。0x6C49 在 0x0800-0xFFFF 之间,使用3字节模板: 1110xxxx10xxxxxx10xxxxxx 。将0x6C49写成二进制是: 0110110001001001 , 用这个比特流依次代替模板中的x,得到: 111001101011000110001001 ,即 E6 B1 89。
例2:Unicode编码0x20C30在0x010000-0x10FFFF 之间,使用 4 字节模板 11110xxx10xxxxxx10xxxxxx10xxxxxx 。将 0x20C30 写成 21 位二进制数字(不足 21 位就在前面补 0): 000100000110000110000 ,用这个比特流依次代替模板中的 x,得到: 11110000101000001011000010110000 ,即 F0 A0 B0 B0。
UTF-16
UTF-16 是 Unicode 的一种编码方式,它用两个字节来编码 BMP 里的代码点,用四个字节编码其余平面里的代码点。
为了书写方便,我们把 Unicode 编码记作 U。
- 如果 U<0x10000 ,U 的 UTF-16 编码就是 U 对应的 16 位 无符号整数 。
- 如果 U≥0x10000 ,我们先计算 U’=U-0x10000,然后将 U’ 写成二进制形式: yyyy yyyy yyxx xxxx xxxx ,U 的 UTF-16 编码(二进制)就是: 110110yyyyyyyyyy110111xxxxxxxxxx 。
为什么 U’ 可以被写成 20 个二进制位?
Unicode 的最大码位是 0x10FFFF,减去 0x10000 后,U 的最大值是 0xFFFFF,所以肯定可以用 20 个二进制位表示。
为什么把 0x10000-0x10FFFF 编码为 110110yyyyyyyyyy110111xxxxxxxxxx ?
110110yyyyyyyyyy 的取值范围为 1101100000000000 – 1101101111111111 ,即 0xD800-0xDBFF( High-surrogate )
110111xxxxxxxxxx 的取值范围为 1101110000000000 – 1101111111111111 ,即 0xDC00-0xDFFF( Low-surrogate ) 所以 110110yyyyyyyyyy110111xxxxxxxxxx 正好是一个 SurrogatePair ,也就是 4 个字节
例如:Unicode 编码 0x20C30,减去 0x10000 后,得到 0x10C30,写成二进制是: 00010000110000110000 。用前 10 位依次替代模板中的 y,用后 10 位依次替代模板中的 x,就 得到: 11011000010000111101110000110000 ,即 0xD843 0xDC30。
UTF-32
UTF-32 编码以 32 位无符号整数为单位。Unicode 的 UTF-32 编码就是其对应的 32 位无符号整数。
大/小端
大小端是 CPU 处理多字节数的不同方式,其主要特点是字节序在内存中存储位置不同。
- 大端(Big-Endian):高字节序存储在低地址,低字节序存储在高地址。
- 小端(Little-Endian):高字节序存储在高地址,低字节序存储在低地址。
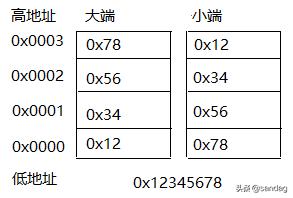
对于任何字符编码,编码单元的顺序是由编码方案指定的,与 endian 无关。例如 GBK 的编码单元是字节,用两个字节表示一个汉字。这两个字节的顺序是固定的,不受 CPU 字节序的影响。UTF-16 的编码单元是 word(双字节),word 之间的顺序是编码方案指定的,word 内部的字节排列才会受到 endian 的影响。
在网络上传输数据时,由于数据传输的两端对应不同的硬件平台,采用的存储字节顺序可能不一致。所以在 TCP/IP 协议规定了在网络上必须采用网络字节顺序,也就是大端模式。
JVM 屏蔽了大小端问题,默认为大端,并且可使用 byte Order.nativeOrder() 查询处理器和内存系统的大小端,在使用 ByteBuffer 时,也可以使用 ByteBuffer.order() 进行设置。
BOM
Unicode 的学名是 “Universal Multiple-Octet Coded Character Set”,简称为 UCS 。UCS 可以看作是 “Unicode Character Set” 的缩写。在 UCS 编码中有一个叫做 “Zero Width No-Break Space”,中文译名作“零宽无间断间隔”的字符,它的编码是 FEFF。而 FFFE 在 UCS 中是不存在的字符,所以不应该出现在实际传输中。UCS 规范建议我们在传输字节流前,先传输字符 “Zero Width No-Break Space”。这样如果接收者收到 FEFF,就表明这个字节流是 Big-Endian 的;如果收到 FFFE,就表明这个字节流是 Little- Endian 的。因此字符 “Zero Width No-Break Space” (“零宽无间断间隔”)又被称作 BOM(即 Byte Order Mark)。
UTF-8 BOM:UTF-8 以字节为编码单元,没有字节序的问题,但可以用 BOM 来表明编码方式。字符 “Zero Width No-Break Space” 的 UTF-8 编码是 EF BB BF 。( windows 系统默认使用 UTF-8 BOM 编码,需要注意 )
文件:D:bom.txt,编码:UTF-8-BOM
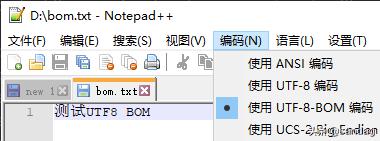
代码:
结果
常见BOM
BOM Encoding字符编码EF BB BFUTF-8 BOMFE FFUTF-16 (big-endian)FF FEUTF-16 (little-endian)00 00 FE FFUTF-32 (big-endian)FF FE 00 00UTF-32 (little-endian)
Java 字符编码
Java 使用 Unicode 字符集并且使用 UTF-16 字符编码。
Java 语言规范规定,Java 的 char 类型是 UTF-16的code unit,也就是一定是 16 位(2 字节)。
一个字符到底占用多少个字节?
对于 Java 中的 char 类型来说的话,固定占用 2 字节,但是为什么使用 newString(“字”).getBytes().length 返回的是 3,这是因为 getBytes 实际是做了 编码转换 (内码转外码),你可以显式传入一个参数来指定编码,否则它会使用 缺省编码 来转换。
对于肉眼可见的字符来说,这个取决于字符编码,同一个字符在不同的编码下占用不同的字节。例如:汉字的”字”,”字”在 GBK 编码下占 2 字节,在 UTF-8 编码下占 3 字节,在 UTF-32 编码下占 4 字节。
内码 & 外码
- 内码 :程序内部使用的字符编码,特别是某种语言实现其 char 或 String 类型在内存里用的内部编码。Java 的内码就是 UTF-16。
- 外码 :程序与外部交互时外部使用的字符编码。简单的来说就是除了内码都可以认为是“外码”(包括 class 文件的编码)。
内码转外码:
- String.getBytes(StringcharsetName) :将内存中的 字符串 用 UTF-16 编码转换为指定编码的 byte 序列。
- String.getBytes() :将内存中的字符串用 UTF-16 编码转换为缺省编码的 byte 序列。
外码转内码:
- newString(byte[]bytes,Stringcharset) :就是把字节流以指定的编码转换为 UTF-16 编码的字节流存入内存中。
- Java 的 class 文件是以 UTF-8 的方式来编码的。JVM 读取 class 文件时需要把 UTF-8 编码转换为 UTF-16 编码读入内存。
注意:编码和解码的“字符编码”必须要一致才能解码成想要的字符串。
缺省编码
可以在启动 JVM 时通过 -Dfile.encoding=UTF-8 来设置,否则使用操作系统环境下的缺省编码,可通过 Charset.defaultCharset() 获取编码。
通常,Windows 系统下是 GBK,Linux 和 Mac 是 UTF-8。
如果使用 IDE ,则会使用工程的缺省编码,具体编码是什么,需要看具体使用的 IDE,可以百度来修改 IDE 的编码。(有可能会遇到某 IDE 在启动项目时控制台打印的日志是乱码,这就是编码搞得鬼) 因为 getBytes 受缺省编码的影响而得到的结果不同,所以在使用该方法时,建议显示指定编码。
String#length()获取的是真正的字符串长度吗?
不是,它获取的仅仅是代码单元的数量,而真正的字符串长度是代码点数量,可使用 String#codePointCount() 来获取。
原因:我们在上面介绍过,某字符的代码点>=0x10000时UTF-16 编码会占用 4 个字节,又因为 Java 的 char 固定就是 2 字节,所以我们需要使用 2 个 char 来表示该字符,那么在使用 String#length()获取字符串长度时,就会出错。
为什么我们平时都是使用该方法获取字符串长度呢?因为 BMP 里定义了我们使用的大部分字符,并且我们基本使用不到 BMP 之外的字符。
为什么 Java 不使用定长编码呢?
Java 设计之初 UTF-16 确实是定长编码,只不过后来 Unicode 的字符变多了之后,UTF-16 变成了变长编码。
Java 5.0 版本既要支持 Unicode 4.0 同时要保证向后兼容性,不得不开始使用 UTF-16 作为内部编码方式。
代码点/代码单元分析
代码
结果
编解码
可通过 Charset.availableCharsets().keySet()来查看 Java 到底支持哪些字符编码。
- 编码:字符集的字符 => 字节数组
- 解码:字节数组 => 字符集的字符
- 编码转换:字符集1的字符 => 字符集 2 的字符,通过这里可以看出如果 2 个字符集的某个字符没有对应关系,那么就会导致乱码
其他来源的字符保存到 JVM 内存需要经历:字节数组 => 指定编码的字符 => Unicode 字符 => UTF-16 编码后的字节数组。
JVM 内存保存到其他地方需要经历:UTF-16 编码后的字节数组 => Unicode字符 => 指定编码的字符 => 字节数组。
由此可以看出,系统内部是做了一步字符集转换。如果两个字符集没有转换规则,那么就会使用 Codepage(代码页),有兴趣的同学可以自行去了解代码页。
代码
结果
1. “编码转换”以 UTF-8 编码存储在 class文件 。
2. JVM 加载 class 文件,从常量池中读取”编码转换“,并使用 UTF-8 解码为 Unicode 字符,然后使用 UTF-16 编码保存到 JVM 内存。
3. “编码转换”.getBytes(“UTF-8”),直接从 JVM 内存获取”编码转换”的字节数组,然后使用 UTF-16 解码为 Unicode 字符,最后使用 UTF-8 编码为新的字节数组。(UTF-16 => UTF-8)
4. new String(utf8Bytes, “GBK”),使用 GBK 把 bytes 解码为 GBK 字符,然后把 GBK 字符转换为 Unicode 字符,最后使用 UTF-16 编码保存到 JVM 内存(GBK 和 Unicode 无联系,所以通过代码页来完成转换)。
浏览器/Tomcat/Mysql

浏览器编码
URI:不同浏览器采用的编码方案不同。例如 chrome 使用 UTF-8 header:ISO-8859-1 body:根据 Content-Type 来进行编码
chrome浏览器
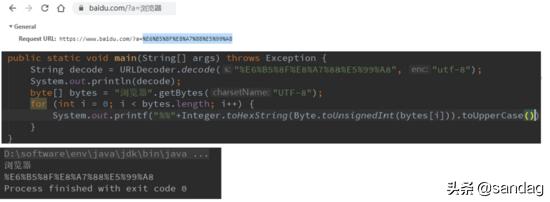
浏览器解码
header:ISO-8859-1 body:首先查看 Content-Type 中是否存在编码方案,其次若返回的是 html 格式,则查看 meta 中是否指定字符集,最后使用浏览器默认字符集解码
在 chrome 中可以使用插件手动修改默认的字符集。例如:Set Character Encoding。
tomcat 编码
依赖于应用程序
tomcat 解码
依赖于 server.xml 的 Connector 的配置
UTIEncoding:URI 的编码,tomcat7 默认 ISO-8859-1,tomcat8 默认 UTF-8。
useBodyEncodingForURI:使 URI 编码等于 request.setCharacterEncoding() 设置的编码。
request.setCharacterEncoding():指定 body 体的编码方式,必须在第一次获取 body 体内容之前设置。
Spring
如果使用 Spring MVC,则需要配置 CharacterEncodingFilter 为第一个过滤器,并且指定编码。
如果使用 Spring Boot,则无需配置,默认配置了 OrderedCharacterEncodingFilter ,默认编码为 UTF-8。
这个过滤器只是针对的 body 体,至于 get 请求还依赖于使用的 tomcat 版本,如使用 Tomcat7,则需要去 server.xml 配置 UTIEncoding/useBodyEncodingForURI,若使用 Tomcat8,无需配置。
Mysql
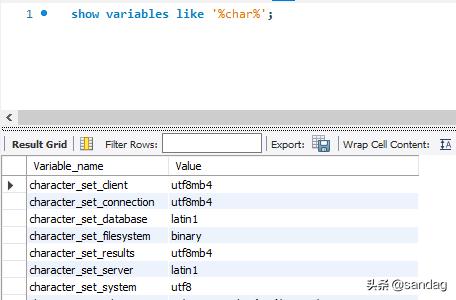
character_set_client :客户端数据解析、编码的字符集
character_set_connection :连接层字符集
character_set_database :当前数据库的字符集
character_set_server :服务器内部操作字符集
character_set_results :查询结果字符集
character_set_system :系统源数据(字段名等)字符集
setnames utf8mb4 等同于同时设置 character_set_client , character_set_connection , character_set_results 这三个字符集
1. 客户端使用特定字符集编码 SQL 发送到服务端。
2. 服务端接受到字节流后,使用 character_set_client 进行解码。
3. 服务端解码后,会使用 character_set_connection 进行编码,然后传给存储引擎。若 character_set_connection 和 character_set_client 不同,则发生字符集转换操作。
4. 存储引擎查询表时,若表字符集和 character_set_connection 不同,则发生字符集转换操作。
5. 存储引擎查询到结果之后,会使用 character_set_results 进行编码返回给客户端,若表字符集和 character_set_results 不同,则发生字符集转换操作。
6. 客户端接受到结果后,使用特定字符集进行解码。
客户端character set clientcharacter set connection表字符集character set results结果utf8utf8utf8/gbkutf8/gbkutf8正常gbkgbkutf8/gbkutf8/gbkgbk正常gbkutf8utf8/gbkutf8/gbkgbk乱码gbkgbkutf8/gbkutf8/gbkutf8乱码gbkutf8utf8/gbkutf8/gbkutf8乱码
由此表可以看出,必须保证 客户端 、 character_set_client 、 character_set_results 一致才可以保证数据正常。如果使 character_set_connection 、 表字符集 和上面 3 个保持一致,可以减少字符集转换。
Connector / J
在使用Connector / J时,创建连接语句 jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=utf8 基本都会配置 useUnicode 和 characterEncoding 。否则创建连接时,驱动程序会自动检测 character_set_server 并使用该字符集。
要覆盖客户端自动检测到的编码,请使用 characterEncoding 服务器连接 URL 中的属性。指定字符编码时,请使用 Java 样式的名称。
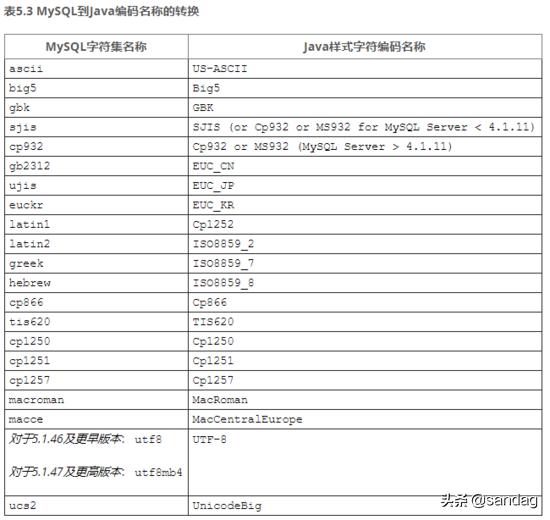
对于 Connector / J 5.1.46 及更早版本:为了使用 utf8mb4 字符集进行连接,服务器必须配置为 character set server=utf8mb4。如果不是这种情况,UTF-8则characterEncoding在连接字符串中使用时,它将映射到 MySQL 字符集名称 utf8。
对于 Connector / J 5.1.47 及更高版本:当 UTF-8 用于 characterEncoding 连接字符串中,它映射到 MySQL 的字符集的名字 utf8mb4。


