Java 集合、 多线程 、反射和Spring框架总结,源码解析
一、集合 – 通过不同的数据结构存储以及操作数据的工具
1.1 Collection
1.1.1 ArrayList、Vector
1.1.1.1 底层原理
1.1.1.2 ArrayList VS Vector
ArrayList是 线程 不安全 的集合,而Vector是 线程安全 的集合。Vector本质是JDK1.0的产物,但是集合体系是JDK1.2才推出的新特性。因此,JDK1.2之后sun公司强行的让Vector类实现了List接口,从而导致Vector之中有很多功能重复的方法。虽然现在为止Vector都没有过时,但是基本上已经不再使用Vector集合,哪怕是多线程环境,也不推荐直接使用Vector来保证线程安全。
1.1.1.3 什么是动态数组?
本质上数组是不能动态的,因为Java中数组一旦初始化好之后,就不能再改变数组长度。但是ArrayList和Vector底层是通过创建新的数组的方式,来达到数组动态扩展的目的。这种动态”改变”数组长度的方式,称之为动态数组
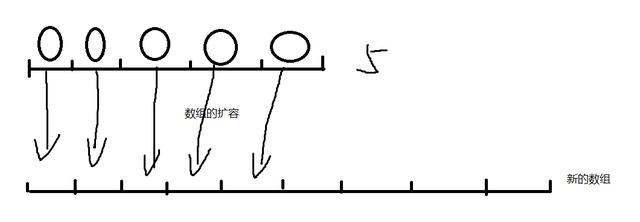
1.1.1.4 源码解析
ArrayList – 构造方法
构造方法中就是将一个长度为空的数组,赋值给一个Object数组的引用(elementData)。JDK1.8之后,ArrayList初始化时,不再默认的初始化一个长度为10的数组(懒加载)。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
....
/**
* 构造方法 - 初始化底层的数组
*/public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
} add – 添加元素
public boolean add(E e) {
//判断当前底层的数组是否需要扩容,如果需要扩容则调用grow方法,进行扩容
ensureCapacityInternal(size + 1);
//将元素设置到数组size的位置,并且size自增
elementData[size++] = e;
return true;
}
//核心扩容方法,参数minCapacity表示当前最小需要扩容的容量
private void grow(int minCapacity) {
//获得旧的数组容量
int oldCapacity = elementData.length;
//计算新的数组容量,根据旧的容量1.5倍扩容
//右移一位相当于除以2,左移一位相当于乘以2
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果新容量没有达到最小容量的要求,则直接用最小容量顶替新容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//数组扩容
//Arrays.copyOf表示将根据参数二(newCapacity)的大小,创建一个新的空数组,并且将参数一(elementData)中的元素,全部拷贝过去,并且返回新数组
elementData = Arrays.copyOf(elementData, newCapacity);
} add – 插入(往中间添加)元素的方法
//插入元素element到下标为index的位置
public void add(int index, E element) {
//检测index下标是否越界
rangeCheckForAdd(index);
//判断是否需要扩容
ensureCapacityInternal(size + 1);
//做一个index位置的元素整体后移,空出index位置来
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//将新的元素放到index位置处
elementData[index] = element;
//元素数量加1
size++;
} **注意:**在ArrayList中,记性数组扩容或者元素移位时,底层都是调用的native方法实现,native本身没有方法体,方法实现是由C/C++实现的,以此来提高扩容的效率。
1.1.2 LinkedList
1.1.2.1 底层原理
Linked底层是由 双向 链表 实现
1.1.2.2 什么是链表?什么是双向链表?
链表是一种非常常见的线性数据结构(和数组类似),由一个一个的节点组成,每个节点都有一个指针,指向链表的下一个节点,因为有”指针”的存在,所以链表在内存空间上可以地址不连续,因此链表没有长度的限制(数组在内存空间上地址必须连续,长度有限)。
双向链表就是普通链表的节点多了一个指向上一个节点的指针
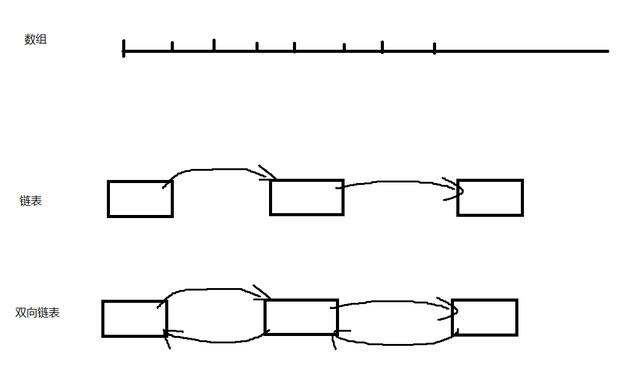
1.1.2.3 Java如何实现一个双向链表?
链表的关键其实就是节点,链表由一个一个节点组成,指向实现了节点的结构,那么链表就能实现。
链表节点的实现:
//LinkedList中底层节点的实现
private static class Node <E> {
//数据部分,存储节点的元素
E item;
//尾部指针,指向下一个节点
Node<E> next;
//头部指针,指向上一个节点
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 1.1.2.4 源码解析
LinkedList的一些基本属性
//first在LinkedList中永远指向链表的头节点,如果没有元素时,就为null
transient Node<E> first;
//last在LinkedList中永远指向链表的尾节点,如果没有元素时,就为null
transient Node<E> last; add添加元素的方法
//添加元素
public boolean add(E e) {
//调用该方法添加元素到链表的尾部
linkLast(e);
return true;
}
//添加元素e到链表的尾部
void linkLast(E e) {
//让l指向尾节点,第一次添加时,因为没有任何节点,所以l和last都是null
final Node<E> l = last;
//将新元素封装成新节点,并且新节点的头指针指向l
final Node<E> newNode = new Node<>(l, e, null);
//再将尾指针指向新节点
last = newNode;
//判断l是否为null,如果为null,表示新节点就是第一个节点
if (l == null)
//first再指向新节点
first = newNode;
else
//l节点的尾指针指向新节点
l.next = newNode;
size++;
modCount++;
} get获取元素的方法
//获取下标index除外的元素
public E get(int index) {
//检查下标越界
checkElementIndex(index);
//找到index位置的节点,获得节点的数据部分
return node(index).item;
}
//node方法,返回index处的节点对象
Node<E> node(int index) {
//判断查找的下标是靠前还是靠后
if (index < (size >> 1)) {
//如果靠前,就从头节点开始,依次遍历往后查找
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//如果靠后,就从尾节点开始,依次遍历往前查找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} add插入(从中间添加)元素的方法
//插入元素到index下标的位置
public void add(int index, E element) {
//检查下标是否越界
checkPositionIndex(index);
if (index == size)
//说明当前的插入位置为末尾,直接调用追加元素的方法
linkLast(element);
else
//插入元素到指定节点之前
linkBefore(element, node(index));
}
....
//插入数据e到succ节点的前面
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
} 1.1.4 ArrayList VS LinkedList
插入性能对比:**尾部:**ArrayList和LinkedList性能相近**中间:**ArrayList的速度 >> LinkedList的速度,ArrayList虽然存在移位,但是底层通过C++直接操作内存的方式进行了优化,而LinkedList每次插入都需要通过遍历的方式找到元素,所以性能有所下降。**头部:**LinkedList的速度 >> ArrayList的速度,ArrayList往头部插入元素,也就意味着每次都需要位移整个数组,虽然有优化,但是也不等于没有耗时,但是LinkedList查找靠前/后的元素速度很快,同时插入性能也很快,所以相对ArrayList性能更优
查询性能对比:**尾部:**ArrayList和LinkedList性能相近**中间:**ArrayList >>>>>>>> LinkedList**头部:**ArrayList和LinkedList性能相近
1.1.3 HashSet、LinkedHashSet、TreeSet
Set各个实现类的特点: HashSet :无序、不可重复**LinkedHashSet:**不可重复,但是元素有序(插入顺序)**TreeSet:**不可重复,但是元素有序(字典顺序)
底层实现:
底层都是通过对应的 Map集合 实现
1.2 Map
1.2.1 HashMap 、Hashtable
1.2.1.1 底层原理
HashMap和Hashtable底层都是由 哈希表 实现的,Hashtable和HashMap的关系与Vector和ArrayList之间的关系类似, Hashtable线程安全 , HashMap线程不安全
1.2.1.2 哈希表(重要)
什么是哈希表?
哈希表 是一种用于快速 树索 的 数据结构 ,精准查询(通过key查询value)效率极高,和元素的数量(理想型,实际过程中,多少还是有点关系)无关,所以 时间复杂度为O(1)
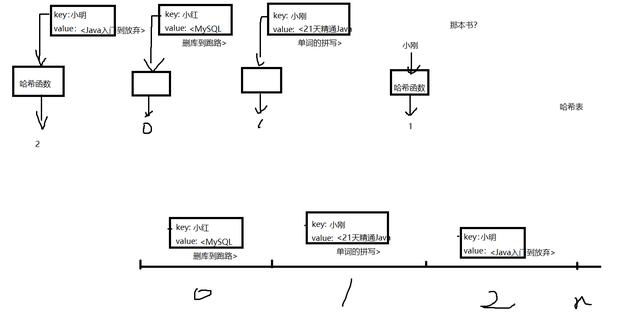
什么是哈希碰撞(哈希冲突)?
哈希碰撞不是一件好事,但是不可避免,所以任何一张好的哈希表必须对哈希碰撞有良好的解决方案。
所谓的哈希碰撞就是指,不同的key,通过哈希函数,计算出的下标相同了。
哈希碰撞的解决方式(HashMap的解决方案)
链地址法:将发生碰撞的元素通过链表连接起来
(JDK1.8之后,是通过 链表 + 红黑树 的方式解决的哈希碰撞)
哈希表的扩容(底层数组的扩容)
一个哈希表,哈希碰撞是不可避免的,如果频繁的发生哈希碰撞,那么会导致大量的链表生成,对查询性能影响很严重。因此哈希表必须通过适当的扩容,来降低哈希碰撞发生的概率,以及优化查询性能。
扩容的好处:1、降低后续发生哈希碰撞的概率2、打散现有的碰撞的链表
什么时候扩容?
哈希表有一个参数,称之为 填充因子 (加载因子,HashMap默认为0.75),当添加的元素数量/数组长度时,一旦达到了填充因子的比例,就会触发一次扩容。 数组长度(100) * 填充因子(0.75) = 扩容 阈值 (75)
如果碰到一些精准定位、去重、判断是否存在等诸如此类的问题,都可以先考虑一下哈希表或者哈希表的一些 变种结构(布隆过滤器)
1.2.1.3 红黑树(简单介绍)
什么是红黑树?
红黑树本身是一种特殊的二叉树,是用于 快速查询 的 数据结构
什么是二叉搜索树?
在一颗二叉树中,任意节点的左子树节点都比当前节点要小,右子树节点都比当前节点要大,那么这颗二叉树就称之为 二叉搜索树
二叉搜索树的缺点:如果插入的元素有一定的顺序,那么就可以导致树的失衡,从而严重降低树的查询能力
红黑树 就是为了解决二叉搜索树,失衡问题而设计的一颗 二叉搜索平衡树
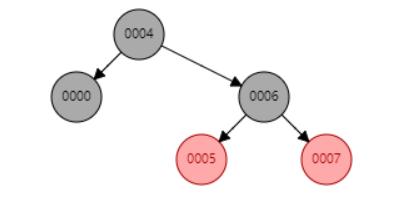
1.2.1.4 HashMap的源码解析(JDK1.8)
HashMap中的一些属性设置
//默认的哈希表容量(数组长度)- 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//哈希表的最大容量(最大的数组长度) - 2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的填充因子 - 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//链表转成树的默认长度
static final int TREEIFY_THRESHOLD = 8;
//树转回链表的默认长度
static final int UNTREEIFY_THRESHOLD = 6;
//当哈希表的容量达到该值时,才会发生链表转树的情况
static final int MIN_TREEIFY_CAPACITY = 64;
//当前的扩容阈值 - 当哈希表的元素数量达到这个阈值时,就会触发扩容 阈值 = 容量 * 填充因子
int threshold;
//当前有效的填充因子值
final float loadFactor;
//底层的哈希表
transient Node<K,V>[] table; HashMap的构造方法
//无参构造
public HashMap() {
//设置当前的填充因子为默认填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
//2个参数的构造方法
//参数1 - 哈希表的初始化容量
//参数2 - 自定义填充因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//根据自定义的容量设置扩容阈值
this.threshold = tableSizeFor(initialCapacity);
} HashMap元素的节点类
//一个key-value就对应一个Node对象
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//当前key的哈希值
final K key;//key
V value;//value
Node<K,V> next;//指向下一个节点的引用 - 链表
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
} HashMap的扩容方法 – resize()
HashMap构造方法并不会初始化底层的哈希表(数组),所以第一次添加元素时,一定会触发一次resize方法扩容,这次扩容的目的是为了初始化哈希表
/*
哈希表扩容的方法
如果是第一次添加元素,则该方法就会初始化哈希表
*/final Node<K,V>[] resize() {
//将旧的哈希表赋值给oldTab变量,如果是第一次添加元素,table必然为null
Node<K,V>[] oldTab = table;
//计算旧的哈希表容量,如果是第一次添加元素,旧哈希表的容量也必然为0
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//当前的拓展阈值 容量(16) * 加载因子(0.75f) = 12
//第一次添加时,oldThr threshold 也是为0
int oldThr = threshold;
//newCap - 扩容后新的哈希表容量
//newThr - 扩容后新的扩展阈值
int newCap, newThr = 0;
//判断旧的哈希表容量是否大于0
if (oldCap > 0) {
//说明哈希表已经被初始化过了
//如果旧的哈希表容量超过了哈希表的最大容量限制,那么就不在扩容,直接返回旧的哈希表
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//新的容量为旧容量的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//新的扩展阈值也设置为旧阈值的2倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
//说明当前哈希表还未被初始化
//将默认的哈希表长度16 设置为newCap属性
newCap = DEFAULT_INITIAL_CAPACITY;
//计算新的扩展阈值 16 * 0.75 = 12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//将新的扩展阈值设置给全局变量,方便下次使用
threshold = newThr;
//初始化新的哈希表
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//将新的哈希表赋值给全局的table变量,后续所有对table的操作,其实就是在操作新的哈希表了
table = newTab;
//判断是否存在旧的哈希表,如果是第一次添加元素,那么oldTable必然为null,resize方法就到此为止了。如果不是第一次添加元素,那么就会存在旧的哈希表,就需要对旧的哈希表进行重新计算
if (oldTab != null) {
//重新计算旧哈希表的每个元素,赋值到新的哈希表中 ?????????
//循环旧的哈希表中的各个哈希桶
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
//当前j位置的哈希桶中有元素节点,将该元素节点赋值给e变量
//将桶j的位置设置为null
oldTab[j] = null;
if (e.next == null)
//说明当前e对应的数据节点只有一个节点(不是链表也不是树)
//通过重新计算哈希位置,将节点e放入新的哈希表中
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
//当前节点e是一颗红黑树,直接走红黑树重新设置的方法
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
//当前节点e是一个链表,将链表进行高位和低位的拆分,重新放入到新的哈希表中,相当于将原来的一个链表,打散成了2个链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
} 设置key-value的方法 – put方法
//给哈希表设置key - value
//hash(key) - 根据key计算哈希值 -> 在哈希表中的下标
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//HashMap底层的哈希函数 - 将任意类型的key转成一个int类型的哈希值(现在还没有落在哈希表的范围内)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//实际添加元素的方法
//参数1-hash:通过key计算的哈希值
//参数2-key:保存的key
//参数3-value:保存的value
//参数4-onlyIfAbsent:用来确定key相同时,value是否覆盖,false表示覆盖,true表示不覆盖
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//初始化一些临时变量
//tab - 当前的哈希表
//p - 当前要保存的key-value对应的哈希桶的中的元素
//n - 当前哈希表的容量
//i - key-value计算出来的哈希表的下标
Node<K,V>[] tab; Node<K,V> p; int n, i;
//获得全局哈希表,判断哈希表是否为空(没有初始化过),意味着本次添加元素是第一次添加
if ((tab = table) == null || (n = tab.length) == 0)
//调用resize方法进行初始化
//将初始化的哈希表赋值给tab变量
//在计算新的哈希表的长度,赋值给n变量
n = (tab = resize()).length;
//(n - 1) & hash - 通过key的哈希值,计算哈希表的下标 !!!!!!!!
//任意类型的int值 & x 得到的结果一定是0 ~ x范围内
//计算出下标位置后,赋值给i变量
if ((p = tab[i = (n - 1) & hash]) == null)
//恭喜你没有发生哈希碰撞
//思考:为什么这里要调用newNode方法,在方法里初始化Node对象,而不是直接初始化Node对象
tab[i] = newNode(hash, key, value, null);
//tab[i] = new Node(hash, key, value, null); 为什么不这么写????
else {
//很遗憾,本次添加发生了哈希碰撞
//临时变量e - 当前临时的节点,用于后续的计算
//临时变量k - 当前发生碰撞的节点p的key值
Node<K,V> e; K k;
//判断添加的元素key和碰撞的元素key是否相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//如果key相同,则将碰撞的节点p设置给临时变量e
e = p;
else if (p instanceof TreeNode)
//当前桶i的位置是一颗红-黑树
//执行红黑树添加节点的方法,如果返回null,就表示节点正常添加到红黑树中
//如果返回的节点不为null,说明添加的数据和红黑树中某个子节点key相同了
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//当前桶i的位置是一个链表(长度有可能为1)
//循环当前哈希桶位置的整个链表
//变量binCount代表当前链表的
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//将添加的数据封装成Node节点对象,插入到链表的末端(尾插)
p.next = newNode(hash, key, value, null);
//如果当前链表的长度达到了TREEIFY_THRESHOLD值
if (binCount >= TREEIFY_THRESHOLD - 1)
//可能将该桶的链表转成红-黑树或者进行哈希表的2倍扩容
treeifyBin(tab, hash);
break;
}
//找到了链表中key和添加元素key相同的节点,跳出循环直接走value覆盖逻辑
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果e不为空,就执行value覆盖的代码,具体覆盖的逻辑需要结合参数onlyIfAbsent
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//key-value已经添加到哈希表中
//++size哈希表的元素数量+1
//当前添加的元素数量超过了扩展阈值(容量 * 加载因子),当前需要扩容
if (++size > threshold)
//执行扩容方法
resize();
afterNodeInsertion(evict);
return null;
}
//tab哈希表的hash值对应的桶的链表转换成红黑树的方法
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//如果哈希表为空,或者哈希表的容量没有达到转树的最小容量(64)
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
//这个时候是不会转树的,而是直接进行一次扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//才将桶index位置的链表转换成红-黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
} 注意:HashMap底层是通过先比较两个key的hash值 , 再比较对象的内存地址 || 比较对象的equals方法 来判断这两个key是否相等
1.2.2 LinkedHashMap
1.2.2.1 特点
key有序(插入顺序),不可重复
1.2.2.2 底层原理
在HashMap的基础上,新增了一个 链表结构 (和解决哈希冲突的链表是两回事),这个链表是用来 维护元素的插入顺序 的。
//每次添加元素时,都会生成一个特殊的节点(除了HashMap里面需要的属性外,额外的多了两个属性,头尾节点的引用)
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
//将新的元素节点,添加到整个链表的尾部
linkNodeLast(p);
return p;
} **注意:**本质上LinkedHashMap和HashMap的实现方式几乎一致,只是添加元素时,需要额外的去维护一个插入顺序的链表,所以添加元素的性能比HashMap略低,但是正因为有这个链表的存在,所以遍历哈希表的性能反而要高于HashMap
1.2.3 TreeMap
1.2.3.1 特点
key有序(字典排序),不可重复
1.2.3.2 底层原理
没有哈希表,底层完全有红-黑树实现。查询性能和添加性能平均情况都低于HashMap,所以除非真的需要key有顺序,否则我们都应该使用HashMap,而不是TreeMap
**注意:**在TreeMap中判断两个key是否相同的方式,不是用==,也不是用equals方法,而是通过比较器(compare)的方法判断是否返回0,如果比较器返回0了,就表示key相同了。
二、多线程
2.1 什么是线程安全的问题?
在 多线程 环境下,同时并发的 操作(增删改)同一份资源 时,因为线程的调度不确定性,所以可能导致资源最后的执行状态和理想状态有一定的出入,这种问题就是所谓的 线程安全问题 。
2.2 什么情况下,程序会有线程安全的问题?
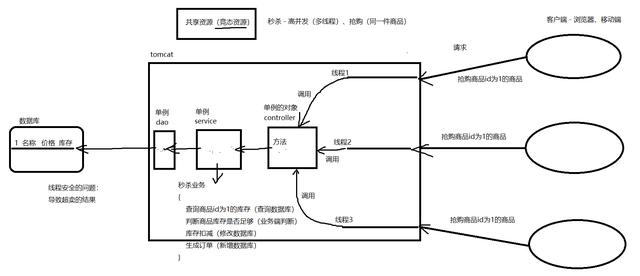
2.3 引发线程安全问题的三个因素
可见性 – 某个线程对一个数据的修改,其他线程是立即可见的
原子性 – 对某个数据的的操作是原子并且不可分割的
有序性 – 程序会按照代码编写的顺序依次执行
在多线程并发操作中,如果以上3个特性有任何一个特性没有得到保证,就会引发线程安全的问题
2.3.1 可见性
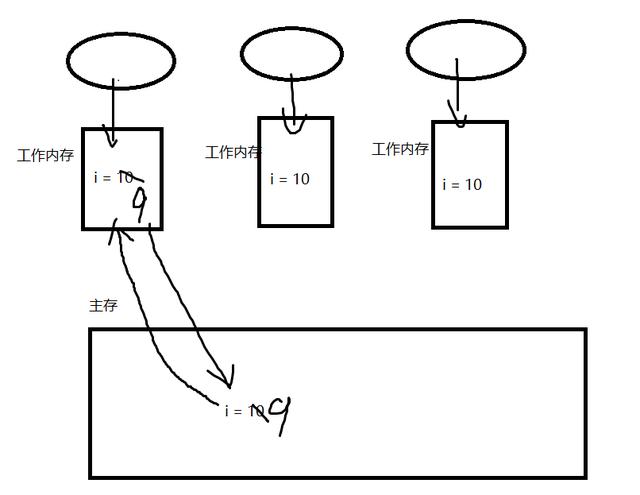
可见性问题的代码:
public class Test1 {
private static boolean flag = true;
public static void main(String[] args) {
//创建一个新的线程
new Thread(() -> {
//
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = false;
System.out.println("flag设置为false!");
}).start();
//死循环
while(flag){
}
}
} 因为可见性的原因,导致子线程对flag的修改,主线程不能立即可见,因此还是无限死循环
2.3.2 原子性(大概率线程安全的问题都是由原子性导致)
i = 10; – 原子操作i++; – 非原子操作 x = i+1; | i=x;
public class Test2 {
private static int x = 0;
public static void main(String[] args) {
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
x++;
}).start();
//x=900
//线程1 - x++ -> (901=900+1; 打断 x=901;)
//线程2 - x++ -> (901=900+1; 901=y;)
}
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("x当前的结果:" + x);//结果又可能小于1000
}
} 因为x++是非原子性的,所以在执行过程中有可能被其他线程打断,从而导致最后的结果一致性出现问题
注意:Java中两个原子性操作,放在一起就不是原子性的了。
2.3.3 有序性
什么是指令重排?
在某些情况下,CPU基于执行效率优化的考虑,可能会改变代码的执行顺序(代码的编写顺序和执行顺序不一样),这种情况就称为 指令重排
指令重排的保证 :在 单线程 情况下,重排后的执行结果与顺序执行的执行结果一定一致。
public class Test3 {
private static Object obj = null;
private static boolean flag = true;
public static void main(String[] args) {
//线程1
while(flag){
System.out.println("死循环中....");
}
//调用hashcode方法
obj.hashCode();//不会报空指针异常
//线程2
obj = new Object();
flag = false;
}
} 2.4 如何保证线程安全
1)使用 volatile 关键字
添加了volatile关键字的属性,具有 可见性 ,对该属性的所有修改,其他线程全部立即可见。同时volatile关键字可以保证 局部有序性 。但是volatile 不能保证原子性 。是一种相对于加锁来说更加轻量级的解决方案。
2)使用concurrent包下的一些 AtomicXxxx类 来进行原子操作
AtomicXxxxx类中的方法都是可以保证原子性的,但是两个原子性的方法并不能保证原子性
3)使用 AtomicXxxx类 来实现 CAS(compare and swap)
CAS本质上是基于 乐观锁 的思想实现的技术,在某些场景下可以帮助我们实现线程安全,比Lock和synchronized加锁的方式会轻量级一些。
public class Test4 {
private static volatile String name;
private static volatile Integer age;
private static volatile
AtomicInteger flag = new AtomicInteger(0);//boolean flag = false;
public static void main(String[] args) {
//线程1
new Thread(() -> {
//如果flag的值等于第一个参数,就设置为第二个参数,并且返回true,否则不设置,返回false
//这个比较并且设置的过程是具有原子性的
//flag.compareAndSet(false, true)
//设置小明,年龄为16
if (flag.compareAndSet(0, 1)){//true
name = "小明";
age = 16;
System.out.println("线程1设置成功!");
} else {
System.out.println("线程1设置失败!");
}
}).start();
//线程2
new Thread(() -> {
//设置小红,年龄为18
if (flag.compareAndSet(0, 1)){//false
name = "小红";
age = 18;
System.out.println("线程2设置成功!");
} else {
System.out.println("线程2设置失败!");
}
}).start();
//线程3
new Thread(() -> {
//设置小刚,年龄为12
if (flag.compareAndSet(0, 1)){//false
name = "小刚";
age = 12;
System.out.println("线程3设置成功!");
} else {
System.out.println("线程3设置失败!");
}
}).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(name + " - " + age);
}
} 4) synchronized 加锁,同时解决 可见性、原子性和有序性 问题
synchronized加锁具体应该锁什么对象?- 将可能降低锁的细粒度
synchronized修饰方法时,如果是非静态方法,默认锁的是this(当前对象)如果是静态方法,默认锁的是当前类的class对象
5)通过 Lock对象 加锁
重入锁机制,是可以完全取代synchronized关键字,相对来说比synchronized更加灵活
//重入锁对象
Lock lock = new ReentrantLock();
new Thread(() -> {
//线程1
lock.lock();//加锁
System.out.println("执行线程1的业务!!!");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unlock();
}).start();
new Thread(() -> {
//线程1
lock.lock();//加锁
System.out.println("执行线程2的业务!!!");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
lock.unlock();
}).start(); 重入读写锁机制
//重入读写锁
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
ReentrantReadWriteLock.WriteLock writeLock = lock.writeLock();//写锁
ReentrantReadWriteLock.ReadLock readLock = lock.readLock();//读锁
new Thread(() -> {
//线程1
writeLock.lock();//加锁
System.out.println("执行线程1的业务!!!");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
writeLock.unlock();
}).start();
new Thread(() -> {
//线程1
readLock.lock();//加锁
System.out.println("执行线程2的业务!!!");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
readLock.unlock();
}).start(); 读写锁中,读锁 兼容 读锁,读锁 互斥 写锁,写锁 互斥 写锁读写锁特别适合读多写少的业务
6)通过 数据库的锁 保证线程安全(表锁、行锁[共享锁、排他锁])
7)通过 redis的lua脚本 实现线程安全
8)通过 分布式锁 (zookeeper、redis)
…
2.5 编写一个线程安全的单例模式(懒汉式)
CAS版的线程安全的懒汉式
public class SingleClass {
//私有化构造方法
private SingleClass(){}
private static AtomicReference<SingleClass> singleClass
= new AtomicReference<>();
/**
* 返回单例对象
* @return
*/ public static SingleClass getInstance(){
singleClass.compareAndSet(null, new SingleClass());
return singleClass.get();
}
} 双重锁判定版本
public class SingleClass {
//私有化构造方法
private SingleClass(){}
private volatile static SingleClass singleClass;
/**
* 返回单例对象
*
* 只有第一次创建对象时有线程安全的问题,一旦创建好之后,就没有线程安全问题了
* @return
*/ public static SingleClass getInstance(){
//线程2
if (singleClass == null){
synchronized (SingleClass.class) {
if(singleClass == null) {
//1、申请堆内存地址
//2、初始化堆内存地址
//3、将引用指向的内存地址
singleClass = new SingleClass();
}
}
}
return singleClass;
}
} 2.6 集合中线程安全的问题
ArrayList、HashMap等集合线程不安全,体现在什么地方?会带来什么问题?
2.6.1 如何解决多线程下集合安全的问题?
可以使用一些线程安全的集合,比如Vector、Hashtable,底层是通过加锁的方式,保证操作的原子性,以此达到线程安全。但是实际开发过程中,不推荐使用这些集合,因为锁的细粒度太大,导致集合的并发性能很差,JDK1.4之后,提供了JUC(java.util.concurrent)的工具包,JUC包中包含了很多线程安全的集合类,这些类采用了特别的机制来保证线程安全,相对来说比Vector、Hashtable并发性更好。
注意:线程安全的集合,不等于所有对集合的操作都是线程安全。
所谓的线程安全集合,指的是集合的每个方法独立调用时,是线程安全的。但是将这些线程安全的方法组合在一起调用,就不一定是线程安全的了。
2.6.2 CopyOnWriteArrayList类 – ArrayList线程安全的解决方案
CopyOnWriteArrayList底层采用了 写入时复制 的机制,来保证写数据的线程安全,同时提高读数据的并发性能(所有读的操作是不加锁),特别适合 读多写少 的场景。但是该类没办法保证数据的强一致性(读的时候有可能读到的是过期的数据),对于某些数据一致性没有绝对要求的场景才能使用,在分布式项目中,往往追求的都是最终一致性(并不会要求强一致),所以CopyOnWriteArrayList在分布式环境下可以使用。如果对数据的一致性要求很高,应该采用List list = Collections.synchronizedList(new ArrayList<>());方式获得线程安全的集合使用。
添加元素的方法 – add(写入时复制)
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//获得当前底层的数据对象
Object[] elements = getArray();
//获得数组的长度
int len = elements.length;
//基于原来的数组,复制一个长度+1的新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
//将新元素写入新数组中
newElements[len] = e;
//将新的数组赋值给全局变量,以后读取的就是这个新数组了
setArray(newElements);
return true;
} finally {
lock.unlock();
}
} 读取元素时的方法 – get
//读取的方法没有任何加锁操作
public E get(int index) {
return get(getArray(), index);
}
1234 2.6.3 ConcurrentHashMap – 线程安全的HashMap
ConcurrentHashMap底层数据结构和HashMap完全一样,采用 数组 + 链表 + 红黑树 的方式实现的哈希表。JDK1.7之前,ConcurrentHashMap采用 分段锁 的方式保证线程安全JDK1.8之后,采用 CAS + synchronized 方式,保证线程安全,并发性能相对于1.7之前会更高
添加元素的方法 – put(key,value)
//添加元素时的方法
final V putVal(K key, V value, boolean onlyIfAbsent) {
//key和value不允许为null
if (key == null || value == null) throw new NullPointerException();
//通过key,计算hash值(后续通过hash值计算哈希桶的位置)
int hash = spread(key.hashCode());
//计数器
int binCount = 0;
//死循环 - ??????????? 自旋
//tab指向当前的哈希表(底层数组)
for (Node<K,V>[] tab = table;;) {
//声明一些局部变量
//f - 当前key对应的哈希桶的第一个节点对象
//n - 当前哈希表的容量(数组的长度)
//i - key计算出来的哈希桶的位置
//fh - 当前桶的第一个元素f的状态位
Node<K,V> f; int n, i, fh;
//判断哈希表是否为空(如果未空,表示还没初始化,需要初始化哈希表)
if (tab == null || (n = tab.length) == 0)
//初始化哈希表,返回新的哈希表,赋值给tab变量
tab = initTable();
//i - 根据key的哈希值和哈希表的容量,计算的哈希桶的位置
//tabAt(tab, i = (n - 1) & hash)) - 可以理解为tab[i]
//因为tab有可见性,但是tab中的节点并不具备可见性,
//方法tabAt(tab, i = (n - 1) & hash))可以直接根据内存地址去内存中读取该位置的节点(可加性)
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//能进入该代码块,说明当前没有发生哈希碰撞,直接将节点设置到指定桶位置
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break;
}
//如果桶i的位置有节点元素,就说明发生了碰撞
//fh赋值为桶i的头节点f的哈希值,但是如果头节点f的哈希值为-1
//表示当前的哈希桶i的位置的所有节点正在参与扩容迁移
else if ((fh = f.hash) == MOVED)
//当前线程会帮助扩容线程进行桶i位置的元素转移
//转移完成后,获得扩容后新的哈希表
tab = helpTransfer(tab, f);
else {
//说明当前哈希桶i位置有节点,发生了哈希碰撞,然后桶i位置的节点也没有进行迁移
//尝试将key-value放入哈希桶i的位置
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
//如果fh(f节点的哈希值)>0,表示当前哈希桶是一个链表
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
//找到尾节点,进行尾插
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//如果f instanceof TreeBin,表示当前哈希桶是一颗红-黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//判断是否进行转树的操作
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
} 初始化哈希表的方法 – initTable
//初始化哈希表
//线程1 - initTable
//线程2 - initTable
private final Node<K,V>[] initTable() {
//tab - 当前哈希表的引用
//sc - 状态值
Node<K,V>[] tab; int sc;
//循环??????- 自旋
while ((tab = table) == null || tab.length == 0) {
//判断sizeCtl(默认为0)状态值,赋给sc变量
if ((sc = sizeCtl) < 0)
//如果sizeCtl<0,说明有人改过这个状态值,可能其他线程已经进来初始化哈希表了
//当前线程直接让步
Thread.yield();
//else 表示没有人修改过sizeCtl变量,那么当线下就修改并且开始进行初始化操作
//U.compareAndSwapInt(this, SIZECTL, sc, -1) - CAS(具有原子性)
//如果变量sizeCtl和sc值相等,那么就给sizeCtl变量赋值为-1,并且整个方法返回true
//如果不相等,就不赋值,并且返回false
//简单来说,这段代码的意思,就是为了保证一定只有一个线程能将sizeCtl变量赋值为-1,一定只有一个线程进入else代码块
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
//一定只有一个线程进入该代码块,执行哈希表的初始化方法
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
//初始化长度为n的哈希表
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
//返回哈希表
return tab;
} 三、反射
什么是反射?
反射 就是在运行时获得动态解析类的能力。
简单来说,反射可以帮助我们创建对象,获得对象的属性,方法…
为什么我们需要通过反射创建对象、获取属性、调用方法?
在实际架构设计过程中,很多时候,我们需要设计一种更为 通用的方法 来处理某些问题,但是我们可能并 不能确定很多对象的类型 ,这时传统的创建对象、获取属性、调用方法就行不通了,那么就可以通过 反射 来编写通用的代码解决问题。
架构师,功能 -> 对象转换成json字符串
/**
* 对象转json的方法 - 使用反射通用实现(简单版本)
* @return
*/ private static String obj2Json(Object obj){
StringBuilder sb = new StringBuilder();
sb.append("{");
//从对象中获取所有属性,拼接成一个json字符串
Class<?> clazz = obj.getClass();
//通过反射的class对象获得对象中的所有属性
Arrays.stream(clazz.getDeclaredFields()).filter(field -> {
//判断当前属性是否有NoJSON注解
boolean has = field.isAnnotationPresent(NoJson.class);
return !has;
}).forEach(field -> {
//给属性授权,可以操作私有
field.setAccessible(true);
//获取所有属性名称
String fielgName = field.getName();
//获得所有的属性值
Object fieldValue = null;
try {
fieldValue = field.get(obj);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
if (sb.length() != 1){
sb.append(",");
}
//封装json
sb.append(""" + fielgName +"":").append(""").append(fieldValue).append(""");
});
sb.append("}");
return sb.toString();
} 工作中运用反射解决的问题
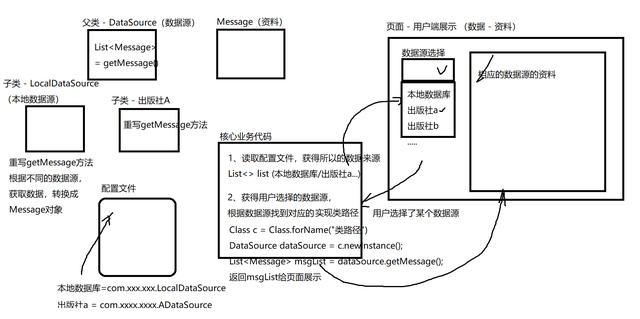
四、Spring框架
4.1 IOC和AOP
什么是IOC?
控制反转 – 将对象创建的权利交给第三方容器(Spring容器),简单点的理解,就是让容器给你New对象,你自己不要new对象了。
为什么需要IOC容器帮助我们new对象?我们自己new对象有啥不好?
解耦 – 解耦能带来什么好处?????
实际开发过程中,当 A类直接new B类的对象 ,我们称之为 硬编码耦合 。如果随着业务的升级迭代, B类的构造形式有可能发生变化 (比如需要构造代理对象),因为B类的构造方式变化了,就必须去A类中修改B对象初始化的代码,如果很多地方new B类的对象,就需要改很多地方,程序的维护性、拓展性就严重下降,Spring的IOC就是为了解除这种耦合性。
什么是AOP?
AOP表示面向切面编程,AOP是一种思想,而Spring是实现了这种思想的框架。对于很多业务来说,通常可以分为核心业务和非核心业务两部分。每个业务的核心业务都不相同,但是很多业务的非核心业务部分却是有着相同的功能(开启事务、回收资源、记录日志…),将这些非核心业务的部分抽取出来,形成一个个所谓的切面,针对这些切面的编程方式,就是所谓的面向切面编程
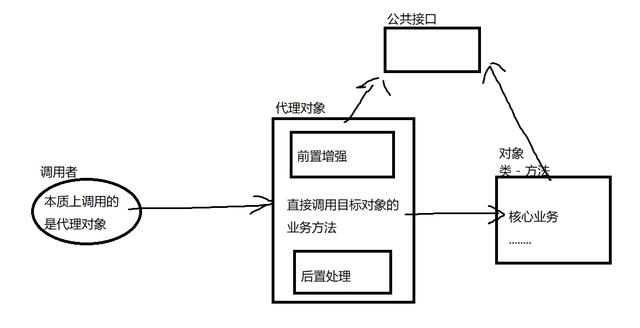
AOP的底层实现
核心原理:动态代理
4.2 猜测一下,Spring IOC实现的基本流程
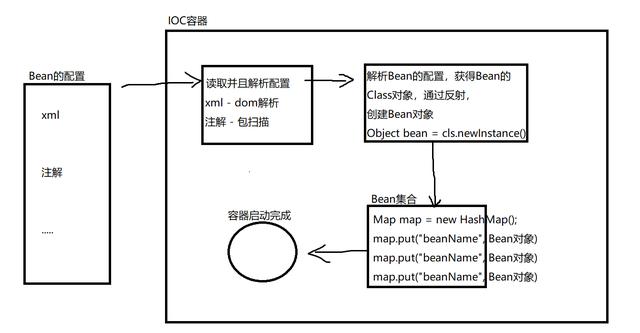
4.3 实际SpringIOC的结构流程图(简化)
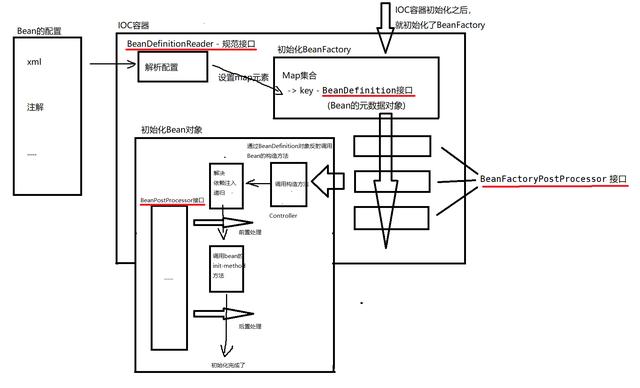
AnnotationConfigApplicationContext构造方法
//注解的配置解析器 //解析类上@ComponentScan(“com.qf”) this.reader = new AnnotatedBeanDefinitionReader(this); //解析包字符串进行扫包的 this.scanner = new ClassPathBeanDefinitionScanner(this); ….. //父类的构造方法中调用,初始化BeanFactory this.beanFactory = new DefaultListableBeanFactory(); 12345678910
scan 扫描包路径的方法
BeanDefinitionRegistry registry; // – 这个对象用来将BeanDefinition对象注册到BeanFactory中 doScan(basePackages); 123
doScan 扫描包路径生成对应的Bean的BeanDefinition对象
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
//根据包路径扫描包下所有的Bean对象,生成对应的BeanDefinition对象
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
} refresh方法
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//准备阶段
prepareRefresh();
//获得前面阶段初始化过的BeanFactory对象(bean工厂)
//Bean工厂 -> Map<beanName, BeanDefinition>
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
//准备BeanFacotory对象,就是给Bean工厂设置一些属性
prepareBeanFactory(beanFactory);
try {
//后置处理器的空方法,留给以后拓展使用,暂时没有作用
postProcessBeanFactory(beanFactory);
//重要!!!!
//调用BeanFactoryPostProcessor后置处理器自定义处理Bean工厂
invokeBeanFactoryPostProcessors(beanFactory);
//重要!!!
//找到内部的和自定义的BeanPostProcess对象,添加到BeanFactory的list集合中保存起来
//List<BeanPostProcessor> beanPostProcessors = new CopyOnWriteArrayList<>();
//现在并没有执行
registerBeanPostProcessors(beanFactory);
//初始化一些消息设置(比如国际化)
initMessageSource();
//初始化容器事件广播器
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
//注册各种监听
registerListeners();
//重要!!!!
//初始化所有的Bean对象(单例)
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
ostProcessor后置处理器自定义处理Bean工厂
invokeBeanFactoryPostProcessors(beanFactory);
//重要!!!
//找到内部的和自定义的BeanPostProcess对象,添加到BeanFactory的list集合中保存起来
//List<BeanPostProcessor> beanPostProcessors = new CopyOnWriteArrayList<>();
//现在并没有执行
registerBeanPostProcessors(beanFactory);
//初始化一些消息设置(比如国际化)
initMessageSource();
//初始化容器事件广播器
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
//注册各种监听
registerListeners();
//重要!!!!
//初始化所有的Bean对象(单例)
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
} 

