一、前言
1、内容增加适用不同读者
《 大数据 和人工智能交流》头条号向广大初学者新增C 、 Java 、 Python 、 Scala 、javascript 等目前流行的计算机、大数据编程语言,希望大家以后关注本头条号更多的内容。
2、本文章目的
(1)、HBase集群的安装步骤;配置文件配置项的含义
(2)、了解Zookeeper 的安装运行
3、所需的系统环境
(1)、Linux操作系统
(2)、安装64位jdk8
(3)、已经安装 Hadoop 分布式环境
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的 Google 论文”Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是 hbase 基于列的而不是基于行的模式。
二、安装环境准备
1、检查是否安装jdk

2、检查是否安装hadoop
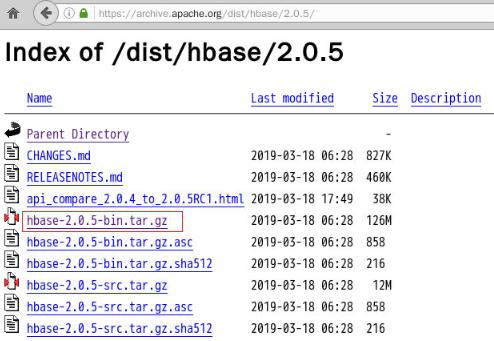
3、下载HBase
下载地址:,现在我们下载hbase2.0.5版本:
三、安装HBase分布式
1、解压
tar -zxvf hbase-2.0.5- bin .tar.gz
解压后的文件如下图所示:

2、配置 环境变量
vi /root/.bashrc
在/root/.bashrc配置文件中输入如下内容:
HBASE_HOME=/home/hbase-2.0.5
HBASE_CONF_DIR=$ HBASE_HOME/conf
HBASE_CLASS_PATH=$HBASE_CONF_DIR
PATH=$PATH:$HBASE_HOME/bin
如下图所示:

保存退出,然后使环境变量生效:
source /root/.bashrc
3、修改/home/hbase-2.0.5/conf下的hbase-env.sh文件
export JAVA_HOME=/opt/java/jdk1.8.0_211/

export HBASE_MANAGERS_ZK=true

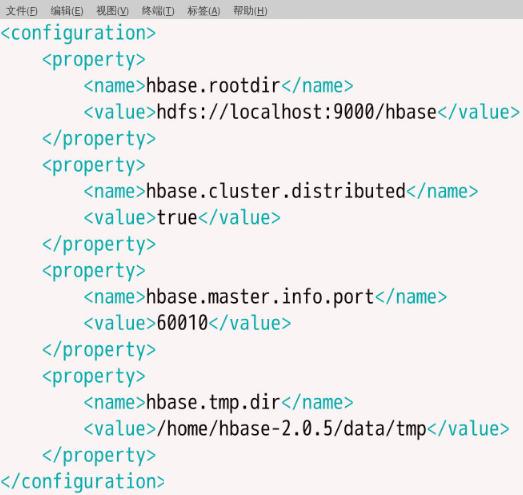
4、修改/home/hbase-2.0.5/conf下的hbase-site.xml文件
在/home/hbase-2.0.5/conf下的hbase-site.xml文件输入如下内容:
<onfiguration>
<property>
<name>hbase.rootdir</name>
<value> hdfs ://localhost:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/hbase-2.0.5</value>
</property>
</configuration>
四、运行HBase服务
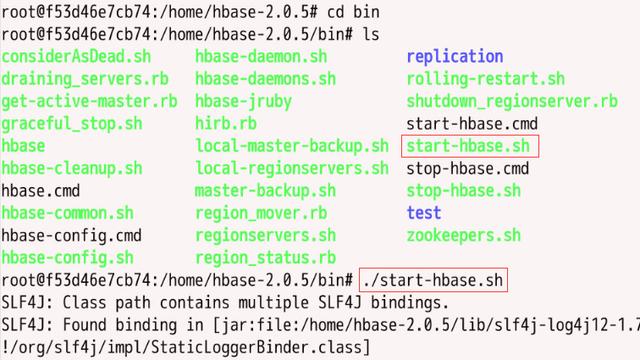
1、启动HBase
在/home/hbase-2.0.5/bin下找到start-hbase.sh脚本,启动hbase,如图所示:
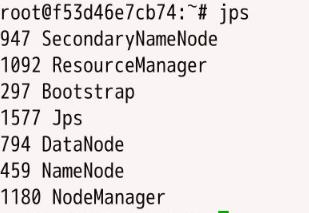
2、使用jps查看HBase的进程
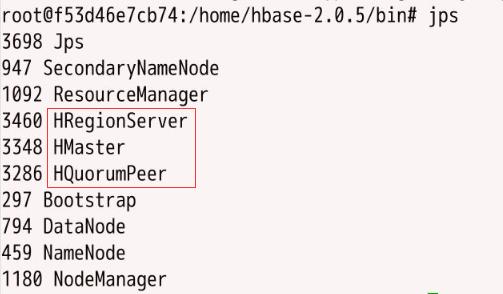
3、进入HBase的 shell 客户端
在/home/hbase-2.0.5/bin下找到hbase,使用下列命令进入HBase的客户端shell:
hbase shell
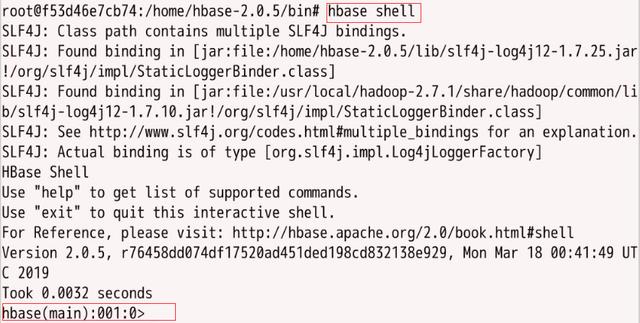
进入HBase的shell,如图所示:
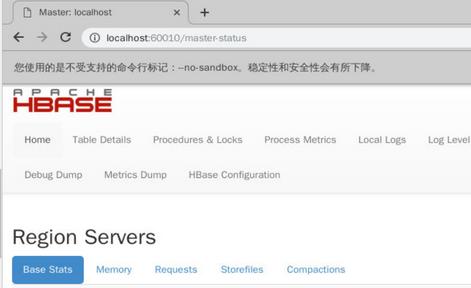
使用浏览器访问60010端口,进入web管理界面:

《大数据和人工智能交流》的宗旨
1、将大数据和人工智能的专业数学:概率数理统计、线性代数、决策论、优化论、博弈论等数学模型变得通俗易懂。
2、将大数据和人工智能的专业涉及到的数据结构和算法:分类、聚类 、回归算法、概率等算法变得通俗易懂。
3、最新的高科技动态:数据采集方面的智能传感器技术;医疗大数据智能决策分析;物联网智慧城市等等。
根据初学者需要会有C语言、Java语言、Python语言、Scala函数式等目前主流计算机语言。
根据读者的需要有和人工智能相关的计算机科学与技术、电子技术、芯片技术等基础学科通俗易懂的文章。


