介绍
该实现与 HashMap 不同的是它维护一个双向链表,可以使HashMap有序。与HashMap一样,该类不安全。
结构
和HashMap的结构非常相似,只不过 LinkedHashMap 是一个双向链表
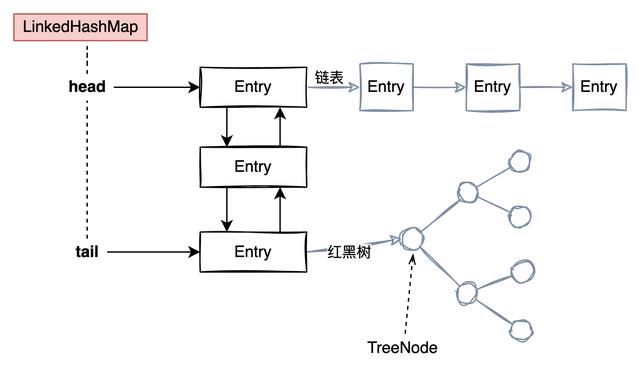
LinkedHashMap 分为两种节点 Entry 和 TreeNode 节点
Entry 节点结构:
class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } before 和 after 是双向链表中的前继和后继节点
TreeNode 节点和 HashMap 中的一样
从这里能看出 LinkedHashMap 是一个双向链表
LinkedHashMap 有如下属性:
transient LinkedHashMap.Entry<K,V> head;transient LinkedHashMap.Entry<K,V> tail;final boolean accessOrder; head 和 tail 很好理解就是双向 链表 的头和尾
HashMap 中没有 accessOrder 这个字段,这也是与 HashMap 最不同的地方,该类有两种取值分别代表不同的意思 :
- true,按照访问顺序排序
- false,按照插入顺序排序
HashMap预留的一些方法
HashMap 预留了一些方法提供给 LinkedHashMap 使用
// LinkedHashMap重写了以下四个方法来保证双向队列能够正常工作// 创建一个Node节点Node<K,V> newNode(int hash, K key, V value, Node<K,V> next){...}// 创建树节点TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {...}// 树节点和普通节点相互转换Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {...}TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {...} // HashMap未实现,留给LinkedHashMap实现// 后置处理// 访问节点后如何处理 void afterNodeAccess(Node<K,V> p) { } // 插入节点后如何处理void afterNodeInsertion(boolean evict) { } // 移除节点后如何处理void afterNodeRemoval(Node<K,V> p) { } afterNodeAccess 、 afterNodeInsertion 、 afterNodeRemoval 这三个方法保证了 LinkedHashMap 有序,分别会在 get 、 put 、 remove 后调用
put 和 remove 都对顺序没有影响,因为在操作的时候已经调整好了(put放在)。但是 get 是对顺序有影响的(被访问到了),所以需要重写该方法:
public V get(Object key) { Node<K,V> e; // 获取节点 if ((e = getNode(hash(key), key)) == null) return null; // 改变顺序 if (accessOrder) afterNodeAccess(e); return e.value; } 通过 afterNodeAccess 来改变该节点(P)的顺序,该方法分为一下几步:
- 拆除需要移动的节点P
- 处理前置节点,前置节点有两种情况前置节点为空,表示P为头节点前置节点不为空,表示P为中间节点
- 处理后置节点后置节点为空,表示P为尾节点后置节点不为空,表示P为中间节点
- 将该节点移动到 tail 处
void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; if (b == null) head = a; else b.after = a; if (a != null) a.before = b; else last = b; if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; } } afterNodeInsertion 则在 putVal 中调用
基本逻辑是如果参数为 true 则尝试删除头节点,但是还需要满足头节点是最’老’的,具体的与 removeEldestEntry 配合使用,可以继承 LinkedHashMap 并定制, LinkedHashMap 是恒为 false 的。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false; } 如果所有条件都满足则删除头节点
void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); } } afterNodeRemoval 则在 removeNode 成功删除节点之后调用:
用来保证在双向链表中删除一个节点仍然能够使结构不被破坏
为被删除节点的头和尾节点建立联系:
void afterNodeRemoval(Node<K,V> e) { // unlink LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.before = p.after = null; if (b == null) head = a; else b.after = a; if (a == null) tail = b; else a.before = b; } 应用
实现 LRU
LRU是一种缓存置换机制,LRU (Least Recently Used)将最近最少使用的内容替换掉。实现非常简单,每次访问某个元素,就将这个元素浮动到栈顶。这样最靠近栈顶的页面就是 最近经常访问 的,而被压在栈底的就是 最近最少使用 的,只需要删除栈底的元素。
LinkedHashMap 非常方便实现LRU, LinkedHashMap 在 put 操作时同时会判断是否需要删除最’老’的元素。只需要重写 removeEldestEntry 方法,使得超过容量就删除最’老’的元素。
下面是具体实现:
public class LRU<K, V> extends LinkedHashMap<K, V> { /** * 最大容量 * <p> * Note: 用位运算就不需要将十进制转换为 二进制 ,直接就为二进制。 */ private final int MAX_CAPACITY = 1 << 30; /** * 缓存的容量 */ private int capacity; public LRU(int capacity) { this(true, capacity); } public LRU(boolean accessOrder, int capacity) { this(1 << 4, 0.75f, accessOrder, capacity); } public LRU(int initialCapacity, float loadFactor, boolean accessOrder, int capacity) { super(initialCapacity, loadFactor, accessOrder); this.capacity = capacity; }} 测试:
LRU<Integer, Integer > lru = new LRU<Integer, Integer>(10); for (int i = 0; i < 10; i++) { lru.put(i, i * i); System.out.println("put: (" + i + "," + i * i + ")"); int random Key = (int) (Math.random() * i); System.out.println("get "+randomKey+": " + lru.get(randomKey)); System.out.println("head->"+lru+"<-tail"); } 结果:
put: (0,0)get 0: 0head->{0=0}<-tail---------------put: (1,1)get 0: 0head->{1=1, 0=0}<-tail---------------put: (2,4)get 1: 1head->{0=0, 2=4, 1=1}<-tail--------------- 喜欢的朋友点赞,转发加关注。


