Java 异常分类及处理
概念
如果某个方法不能按照正常的途径完成任务,就可以通过另一种路径退出方法。在这种情况下会抛出一个封装了错误信息的对象。此时,这个方法会立刻退出同时不返回任何值。另外,调用这个方法的其他代码也无法继续执行,异常处理机制会将代码执行交给异常处理器。
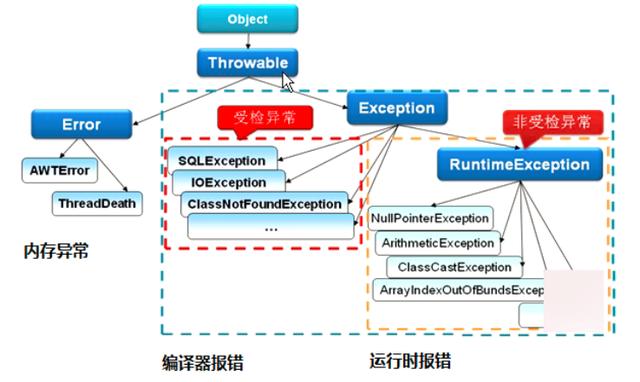
异常分类
Throwable 是 Java 语言中所有错误或异常的超类。下一层分为 Error 和 Exception
Error
1. Error 类是指 java 运行时系统的内部错误和资源耗尽错误。应用程序不会抛出该类对象。如果出现了这样的错误,除了告知用户,剩下的就是尽力使程序安全的终止。
Exception( RuntimeException、CheckedException )
2. Exception 又 有 两 个 分 支 , 一 个 是 运 行 时 异 常 RuntimeException , 一 个 是CheckedException。
RuntimeException 如 : NullPointerException 、 ClassCastException ; 一 个 是 检 查 异 常CheckedException,如 I/O 错误导致的 IOException、SQLException。 RuntimeException 是那些可能在 Java 虚拟机正常运行期间抛出的异常的超类。 如果出现 RuntimeException,那么一定是程序员的错误。
检查异常 CheckedException :一般是外部错误,这种异常都发生在编译阶段,Java 编译器会强制程序去捕获此类异常,即会出现要求你把这段可能出现异常的程序进行 try catch,该类异常一般包括几个方面:
1. 试图在文件尾部读取数据
2. 试图打开一个错误格式的 URL
3. 试图根据给定的字符串查找 class 对象,而这个字符串表示的类并不存在
异常的处理方式
遇到问题不进行具体处理,而是继续抛给调用者 (throw,throws)
抛出异常有三种形式,一是 throw,一个 throws,还有一种系统自动抛异常。
public static void main(String[] args) {
String s = "abc";
if(s.equals("abc")) {
throw new NumberFormatException();
} else {
System.out.println(s);
}
}
int div(int a,int b) throws Exception{
return a/b;}
try catch 捕获异常针对性处理方式
Throw 和 throws 的区别:
位置不同
1. throws 用在函数上,后面跟的是异常类,可以跟多个;而 throw 用在函数内,后面跟的是异常对象。
功能不同:
2. throws 用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方式;throw 抛出具体的问题对象,执行到 throw,功能就已经结束了,跳转到调用者,并将具体的问题对象抛给调用者。也就是说 throw 语句独立存在时,下面不要定义其他语句,因为执行不到。
3. throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw 则是抛出了异常,执行 throw 则一定抛出了某种异常对象。
4. 两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
JAVA 反射
动态语言
动态语言,是指程序在运行时可以改变其结构:新的函数可以引进,已有的函数可以被删除等结构上的变化。比如常见的 JavaScript 就是动态语言,除此之外 Ruby,Python 等也属于动态语言,而 C、C++则不属于动态语言。从反射角度说 JAVA 属于半动态语言。
反射机制 概念 (运行状态中知道类所有的属性和方法)
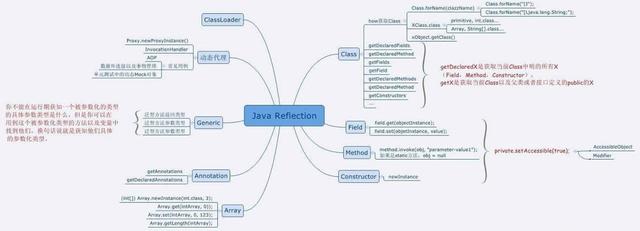
在 Java 中的反射机制是指在运行状态中,对于任意一个类都能够知道这个类所有的属性和方法;并且对于任意一个对象,都能够调用它的任意一个方法;这种动态获取信息以及动态调用对象方法的功能成为 Java 语言的反射机制。
反射的应用场合
编译时类型和运行时类型
在 Java 程序中许多对象在运行是都会出现两种类型:编译时类型和运行时类型。 编译时的类型由声明对象时实用的类型来决定,运行时的类型由实际赋值给对象的类型决定 。如:
Person p=new Student();
其中编译时类型为 Person,运行时类型为 Student。
的编译时类型无法获取具体方法
程序在运行时还可能接收到外部传入的对象,该对象的编译时类型为 Object,但是程序有需要调用该对象的运行时类型的方法。为了解决这些问题,程序需要在运行时发现对象和类的真实信息。
然而,如果编译时根本无法预知该对象和类属于哪些类,程序只能依靠运行时信息来发现该对象和类的真实信息,此时就必须使用到反射了。
Java 反射 API
反射 API 用来生成 JVM 中的类、接口 或则 对象的信息。
1. Class 类:反射的核心类,可以获取类的属性,方法等信息。
2. Field 类:Java.lang.reflec 包中的类,表示类的成员变量,可以用来获取和设置类之中的属性值。
3. Method 类: Java.lang.reflec 包中的类,表示类的方法,它可以用来获取类中的方法信息或者执行方法。
4. Constructor 类: Java.lang.reflec 包中的类,表示类的构造方法。
反射使用步骤(获取 Class 对象、调用对象方法)
1. 获取想要操作的类的 Class 对象,他是反射的核心,通过 Class 对象我们可以任意调用类的方法。
2. 调用 Class 类中的方法,既就是反射的使用阶段。
3. 使用反射 API 来操作这些信息。
获取 Class 对象的 3 种方法
调用某个对象的 getClass()方法
Person p=new Person();
Class clazz=p.getClass();
调用某个类的 class 属性来获取该类对应的 Class 对象
Class clazz=Person.class;
使用 Class 类中的 forName()静态方法(最安全/性能最好)
Class clazz=Class.forName(“类的全路径”); (最常用)
当我们获得了想要操作的类的 Class 对象后,可以通过 Class 类中的方法获取并查看该类中的方法和属性。
//获取 Person 类的 Class 对象
Class clazz=Class.forName("reflection.Person");
//获取 Person 类的所有方法信息
Method[] method=clazz.getDeclaredMethods();
for(Method m:method){
System.out.println(m.toString());
}
//获取 Person 类的所有成员属性信息
Field[] field=clazz.getDeclaredFields();
for(Field f:field){
System.out.println(f.toString());
}
//获取 Person 类的所有构造方法信息
Constructor[] constructor=clazz.getDeclaredConstructors();
for(Constructor c:constructor){
System.out.println(c.toString());
}
创建对象的两种方法
Class 对象的 newInstance()
1. 使用 Class 对象的 newInstance()方法来创建该 Class 对象对应类的实例,但是这种方法要求该 Class 对象对应的类有默认的空构造器。
调用 Constructor 对象的 newInstance()
2. 先使用 Class 对象获取指定的 Constructor 对象,再调用 Constructor 对象的 newInstance()方法来创建 Class 对象对应类的实例,通过这种方法可以选定构造方法创建实例。
//获取 Person 类的 Class 对象
Class clazz=Class.forName("reflection.Person");
//使用.newInstane 方法创建对象
Person p=(Person) clazz.newInstance();
//获取构造方法并创建对象
Constructor c=clazz.getDeclaredConstructor(String.class,String.class,int.class);
//创建对象并设置属性
Person p1=(Person) c.newInstance("李四","男",20);
JAVA 注解
概念
Annotation (注解)是 Java 提供的一种对元程序中元素关联信息和元数据(metadata)的途径和方法。Annatation(注解)是一个接口,程序可以通过反射来获取指定程序中元素的 Annotation对象,然后通过该 Annotation 对象来获取注解中的元数据信息。
4 种标准元注解
元注解的作用是负责注解其他注解。 Java5.0 定义了 4 个标准的 meta-annotation 类型,它们被用来提供对其它 annotation 类型作说明。
@Target 修饰的对象范围
@Target说明了Annotation所修饰的对象范围: Annotation可被用于 packages、types(类、接口、枚举、Annotation 类型)、类型成员(方法、构造方法、成员变量、枚举值)、方法参数和本地变量(如循环变量、catch 参数)。在 Annotation 类型的声明中使用了 target 可更加明晰其修饰的目标
@Retention 定义 被保留的时间长短
Retention 定义了该 Annotation 被保留的时间长短:表示需要在什么级别保存注解信息,用于描述注解的生命周期(即:被描述的注解在什么范围内有效),取值(RetentionPoicy)由:
SOURCE:在源文件中有效(即源文件保留)
CLASS:在 class 文件中有效(即 class 保留)
RUNTIME:在运行时有效(即运行时保留)
@Documented 描述-javadoc
@ Documented 用于描述其它类型的 annotation 应该被作为被标注的程序成员的公共 API,因此可以被例如 javadoc 此类的工具文档化。
@Inherited 阐述了某个被标注的类型是被继承的
@Inherited 元注解是一个标记注解,@Inherited 阐述了某个被标注的类型是被继承的。如果一个使用了@Inherited 修饰的 annotation 类型被用于一个 class,则这个 annotation 将被用于该class 的子类。

注解处理器
如果没有用来读取注解的方法和工作,那么注解也就不会比注释更有用处了。使用注解的过程中,很重要的一部分就是创建于使用注解处理器。Java SE5 扩展了反射机制的 API,以帮助程序员快速的构造自定义注解处理器。下面实现一个注解处理器。
/1:*** 定义注解*/
@Target(ElementType.FIELD)
@Retent io n(RetentionPolicy.RUNTIME)
@Documented
public @interface FruitProvider {
/**供应商编号*/
public int id() default -1;
/*** 供应商名称*/
public String name() default "";
/** * 供应商地址*/
public String address() default "";
}
//2:注解使用
public class Apple {
@FruitProvider(id = 1, name = "陕西红富士集团", address = "陕西省西安市延安路")
private String appleProvider;
public void setAppleProvider(String appleProvider) {
this.appleProvider = appleProvider;
}
public String getAppleProvider() {
return appleProvider;
}
}
/3:*********** 注解处理器 ***************/
public class FruitInfoUtil {
public static void getFruitInfo(Class<?> clazz) {
String strFruitProvicer = "供应商信息:";
Field[] fields = clazz.getDeclaredFields();//通过反射获取处理注解
for (Field field : fields) {
if (field.isAnnotationPresent(FruitProvider.class)) {
FruitProvider fruitProvider = (FruitProvider) field.getAnnotation(FruitProvider.class);
//注解信息的处理地方
strFruitProvicer = " 供应商编号:" + fruitProvider.id() + " 供应商名称:"
+ fruitProvider.name() + " 供应商地址:"+ fruitProvider.address();
System.out.println(strFruitProvicer);
}
}
}
}
public class FruitRun {
public static void main(String[] args) {
FruitInfoUtil.getFruitInfo(Apple.class);
/***********输出结果***************/
// 供应商编号:1 供应商名称:陕西红富士集团 供应商地址:陕西省西安市延
}
}
JAVA 内部类
Java 类中不仅可以定义变量和方法,还可以定义类,这样定义在类内部的类就被称为内部类。根据定义的方式不同,内部类分为静态内部类,成员内部类,局部内部类,匿名内部类四种。
静态内部类
定义在类内部的静态类,就是静态内部类。
public class Out {
private static int a;
private int b;
public static class Inner {
public void print() {
System.out.println(a);
}
}
}
1. 静态内部类可以访问外部类所有的 静态变量 和方法,即使是 private 的也一样。
2. 静态内部类和一般类一致,可以定义静态变量、方法,构造方法等。
3. 其它类使用静态内部类需要使用“外部类.静态内部类”方式,如下所示:Out.Inner inner =new Out.Inner();inner.print();
4. Java集合类HashMap内部就有一个静态内部类Entry。Entry是HashMap存放元素的抽象,HashMap 内部维护 Entry 数组用了存放元素,但是 Entry 对使用者是透明的。像这种和外部类关系密切的,且不依赖外部类实例的,都可以使用静态内部类。
成员内部类
定义在类内部的非静态类,就是成员内部类。成员内部类不能定义静态方法和变量(final 修饰的除外)。这是因为成员内部类是非静态的,类初始化的时候先初始化静态成员,如果允许成员内部类定义静态变量,那么成员内部类的静态变量初始化顺序是有歧义的。
public class Out {
private static int a;
private int b;
public class Inner {
public void print() {
System.out.println(a);
System.out.println(b);
}
}
}
局部内部类(定义在方法中的类)
定义在方法中的类,就是局部类。如果一个类只在某个方法中使用,则可以考虑使用局部类。
public class Out {
private static int a;
private int b;
public void test(final int c) {
final int d = 1;
class Inner {
public void print() {
System.out.println(c);
}
}
}
}
匿名内部类(要继承一个父类或者实现一个接口、直接使用new 来生成一个对象的引用)
匿名内部类我们必须要继承一个父类或者实现一个接口,当然也仅能只继承一个父类或者实现一个接口。同时它也是没有 class 关键字,这是因为匿名内部类是直接使用 new 来生成一个对象的引用。
public abstract class Bird {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public abstract int fly();
}
public class Test {
public void test(Bird bird){
System.out.println(bird.getName() + "能够飞 " + bird.fly() + "米");
}
public static void main(String[] args) {
Test test = new Test();
test.test(new Bird() {
public int fly() {
return 10000;
}
public String getName() {
return "大雁";
}
});
}
}
JAVA 泛型
泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。比如我们要写一个排序方法,能够对整型数组、字符串数组甚至其他任何类型的数组进行排序,我们就可以使用 Java 泛型。
泛型方法(<E>)
你可以写一个泛型方法,该方法在调用时可以接收不同类型的参数。根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
// 泛型方法 printArray
public static < E > void printArray( E[] inputArray )
{
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
}
1. <? extends T>表示该通配符所代表的类型是 T 类型的子类。
2. <? super T>表示该通配符所代表的类型是 T 类型的父类。
泛型类<T>
泛型类的声明和非泛型类的声明类似,除了在类名后面添加了类型参数声明部分。和泛型方法一样,泛型类的类型参数声明部分也包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。因为他们接受一个或多个参数,这些类被称为参数化的类或参数化的类型。
public class Box<T> {
private T t;
public void add(T t) {
this.t = t;
}
public T get() {
return t;
}
类型通配符?
类型通配符一般是使用 ? 代 替 具 体 的 类 型 参 数 。 例 如 List<?> 在逻辑上是List<String>,List<Integer> 等所有 List<具体类型实参>的父类。
类型擦除
Java 中的泛型基本上都是在编译器这个层次来实现的。在生成的 Java 字节代码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会被编译器在编译的时候去掉。这个过程就称为类型擦除。如在代码中定义的 List<Object>和 List<String>等类型,在编译之后都会变成 List。JVM 看到的只是 List,而由泛型附加的类型信息对 JVM 来说是不可见的。类型擦除的基本过程也比较简单,首先是找到用来替换类型参数的具体类。这个具体类一般是 Object。如果指定了类型参数的上界的话,则使用这个上界。把代码中的类型参数都替换成具体的类。
JAVA 序列化(创建可复用的 Java 对象) 保存(持久化)对象及其状态到内存或者磁盘
Java 平台允许我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比 JVM 的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。
Java 对象序列化就能够帮助我们实现该功能。
序列化对象以字节数组保持-静态成员不保存
使用 Java 对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
序列化用户远程对象传输
除了在持久化对象时会用到对象序列化之外,当使用 RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java序列化API为处理对象序列化提供了一个标准机制,该API简单易用。
Serializable 实现序列化
在 Java 中,只要一个类实现了 java.io.Serializable 接口,那么它就可以被序列化。
ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化
通过 ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化。
writeObject 和 readObject 自定义序列化策略
在类中增加 writeObject 和 readObject 方法可以实现自定义序列化策略。
序列化 ID
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)。
序列化并不保存静态变量
序列化子父类说明
要想将父类对象也序列化,就需要让父类也实现 Serializable 接口。
Transient 关键字阻止该变量被序列化到文件中
1. 在变量声明前加上 Transient 关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
2. 服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
JAVA 复制
将一个对象的引用复制给另外一个对象,一共有三种方式。第一种方式是直接赋值,第二种方式是浅拷贝,第三种是深拷贝。所以大家知道了哈,这三种概念实际上都是为了拷贝对象。
直接 赋值 复制
直接赋值。在 Java 中,A a1 = a2,我们需要理解的是这实际上复制的是引用,也就是说 a1 和 a2 指向的是同一个对象。因此,当 a1 变化的时候,a2 里面的成员变量也会跟着变化。
浅复制(复制引用但不复制引用的对象)
创建一个新对象,然后将当前对象的非静态字段复制到该新对象,如果字段是值类型的,那么对该字段执行复制;如果该字段是引用类型的话,则复制引用但不复制引用的对象。
因此,原始对象及其副本引用同一个对象。
class Resume implements Cloneable{
public Object clone() {
try {
return (Resume)super.clone();
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
深复制(复制对象和其应用对象)
深拷贝不仅复制对象本身,而且复制对象包含的引用指向的所有对象。
class Student implements Cloneable {
String name;
int age;
Professor p;
Student(String name, int age, Professor p) {
this.name = name;
this.age = age;
this.p = p;
}
public Object clone() {
Student o = null;
try {
o = (Student) super.clone();
} catch (CloneNotSupportedException e) {
System.out.println(e.toString());
}
o.p = (Professor) p.clone();
return o;
}
}
序列化(深 clone 一中实现)
在 Java 语言里深复制一个对象,常常可以先使对象实现 Serializable 接口,然后把对象(实际上只是对象的一个拷贝)写到一个流里,再从流里读出来,便可以重建对象。
多多转发关注不迷路~~感谢大家支持~~~~~~~~~
好的东西就要分享给大家学习!


