一、大数据处理引擎 spark 介绍
1.大数据处理技术栈

大数据 的特性,数据是海量的,数据源是丰富多样的,有消息,图片,音视频流,数据产生的非常快,需要快速处理,提高数据价值。 数据生成后,需要存储元数据信息,选择合适的存储格式,像Parquet、ORC是两种高性能的列式存储,Hudi数据存储的中间件,优化存储的读写,也可以存储到分布式文件存储系统 HDFS ,分布式消息系统 kafka ,keyvalue分布式存储的nosql引擎数据库 Hbase ,基于列式存储的分布式数据库Kudu,字节提供的TOS,S3 对象存储 。 存储的数据需要计算才能使用,大数据的计算框架,Spark批式计算,Flink流式计算,Presto等处理在线分布式查询场景的,是可交互式的OLAP引擎,计算框架借助资源管理的编排调度工具 YARN ,K8S,来运行在分布式集群中处理存储的数据。 计算处理存储的数据后提供给上层应用,有BI报表,广告,推荐,金融风控等。
2.常见大数据处理链路

数据库中采集到的数据称为数据源,存储到分布式存储系统中HDFS等,进行一系列的数据处理,会有多次数据读取写入,可以是各种存储系统,也可以是各种数据库,讲处理的结果进行计算,再做各种应用。
3.开源大数据处理引擎
批式计算: Hadoop 、 Hive 、Spark 流式计算:Flink OLAP:presto,ClickHouse,Impala,DORIS
MapReduce 解决了Hadoop诞生,数据大规模处理数据,主流Spark是基于内存处理,对 map Reduce进行了优化。
4.什么是Spark?
Spark是用于大规模数据处理的统一分析引擎,是一种多语言引擎,可以用于单机节点或集群上来执行数据工程,数据科学和机器学习。

feature:
- 多语言选择,用统一的方式处理流批的数据
- 可以用为仪表盘执行快速的 sql 查询分析,
- 适用于大规模的数据科学,对PB级别的数据来执行探索性的数据分析,对数据进行训练建模预测。
- 机器学习,在单机上训练机器学习的算法,可以很方便的拓展到大规模集群上
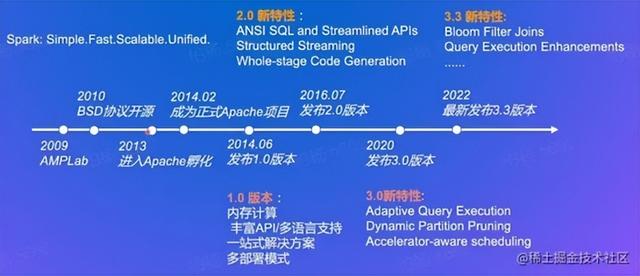
5.Spark版本演进
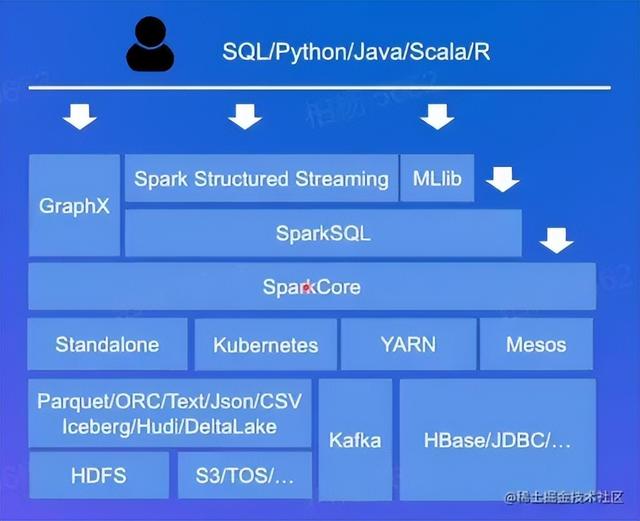
Spark生态&特点 -SparkCore 核心块 基本功能:任务调度,内存管理 -SparkSQL,操作结构化数据的核心组件,直接查询Hbase等各种各样的数据源,可以进行交互式的查询 -StruturedStreaming 流式计算框架,支持高吞吐的,可容错处理的,实时流式数据 -MLlib,机器学习算法库,分类,聚类,回归等,模型评估, -GraphX分布式图处理框架,提供图计算,图挖掘的一些API
- 统一引擎,支持各种各样分布式场景
- 多语言支持
- 支持丰富的数据源:内置 DataSource ,Text;Parquet/ORC; JSON / CSV ;JSBC 自定义DataSource:Hbase/Mongo等
- 丰富灵活的API/算子: RDD
- 支持K8S/YARN/Meso资源调度
6.Spark运行架构&部署方式

集群管理器,负责管理整个集群,负责资源管理和调度,监控Woker节点, Worker从节点,负责控制计算节点 Deiver Program,是一个APP整个应用的管理者,负责作业的调度,是一个 JVM 进程,创建一个SparkContext上下文,控制整个应用的 生命周期
Spark Local Mode 本地测试/单进程多线程模式
Spark Srandalone Mode 不需要借助外部的资源调度管理, 需要启动Spark的Sandalone集群的Master/Worker
依赖 YARN/K8S 依赖外部资源调度器 用master完成不同的部署方式,委托给谁资源管理
二、SparkCore原理解析
1.SparkCore

用户选择了集群提交到外部资源管理器,比如说提交到YARN,在mode management创建一个appmaster,用来管理资源,是否有资源创建 Executor ,APPmaster在YARN模式下相当于Driver也会通过DAG,Task Scheduler管理和分配Task。

Spark的数据输入到输出所有的数据结构都是基于RDD的,接下来从RDD开始说。
2.什么是RDD
RDD是一个可以容错的,并行执行的分布式数据集,最基本的数据处理模型。
- 分区列表,每一个RDD都有多个分区,这些分区运行在集群不同节点上,每个分区都会被一个计算任务Task处理,分区决定了并行计算的数量。创建RDD可以指定分区个数,从集群创建的话,默认分区数是CPU核数;从HDFS文件存储创建的话,Partition个数就是文件的blog数。
- 都有一个计算函数,RDD以Partition为基本单位,每个RDD实现一个compute函数,对具体的RDD进行计算
- 有依赖,每一个RDD都会依赖于RDD,每次转换都会生成新的RDD,RDD会形成像Pipeline形成前后依赖关系。部分分区数据丢失时,Spark可以通过依赖关系重新计算分区数据,而不是对所有的RDD都进行重新计算
- 实现了两种类型分区函数,一个基于哈希的Hash partitioner,基于范围的 range partitioner,两种分区器。对于只有key-value的RDD,才会有分区partitioner,非key-value的RDD,partitioner的值是空的。Partitioner不但决定了RDD本身的分区数量,也决定了parent RDD shuffle时的shuffle分区数量。
- 每个分区有一个优先的位置列表,他会存储每个partition的优先位置,例如HDFS的文件会存储每个partition块的数据,移动数据不如移动计算,进行任务调度的时候,尽可能将计算分配到需要处理的任务块的位置。
提供了各种各样的算子,就是成员函数,map,filter返回新的RDD;count返回新的数据类型。 cache ,persist(缓存)当一个RDD被多次使用,这个RDD计算链路非常长,那么计算结果就会非常珍贵。可以中间进行缓存,保存计算结果,这也是Spark速度快的原因,可以在内存中持久化缓存数据集。
如何创建RDD?
- 有很多内置RDD
- 自定义RDD
- 有很多内置RDD
- 自定义RDD
两类RDD算子
- Transform算子:生成一个新的RDD
比如map,filter,flatMap,groupByKey,reduceByKey…..

本来是一个Parallel的RDD,经过一个Map的操作后,变成了一个MapPartitionsRDD。
- Action算子:触发Job提交
比如collect、count、take、saveAsText File …..

本来是一个RDD,做了一个count,触发了Job提交,返回了 Long 类型。take就是取前几个元素,触发了一个Job,返回了一个Array。
RDD依赖
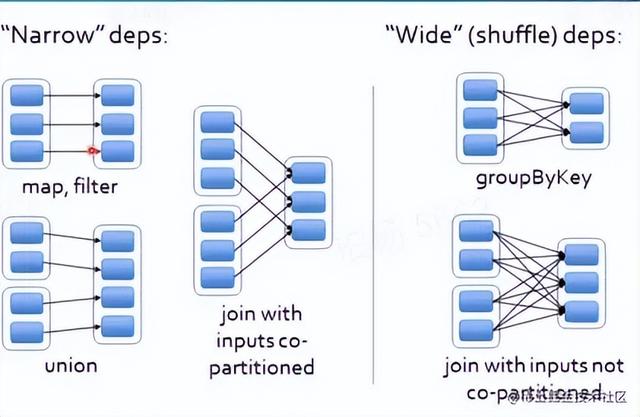
- 窄依赖:父RDD的partition至多对应一个子RDD的分区,但是子RDD可能有多个父RDD的分区。窄依赖分别有三种
OneToOneDependency,是一对一的,返回对应Partition的list
RangeDependency,inStart是父RDD起始的位置,outStart是子RDD起始的位置,length是range的长度,如果子RDD的partition的index在父RDD的range内,返回父RDD,返回父RDD的partition是子RDD的partition的index减去父RDD分区的range的起始,再加上子RDD分区range的起始
PruneDependency
- 宽依赖(会产生Shuffle):父RDD的每个partition都可能对应多个子RDD分区,都会使用所有父RDD的多个分区,就相当于是one to many,当RDD做groupBy或Join操作时会产生宽依赖。
ShuffleDependency,Shuffle的产生是因为有宽依赖,宽依赖对应一个Shuffle的操作,运行过程中父RDD的分区,会传入不同的子RDD分区中,中间就可能涉及到多个节点的数据传输。
如果子RDD故障,有可能一部分父RDD就可以覆盖子RDD的计算,有时需要所有的父RDD进行重算,代价比较高。可以设置一个检查点 checkpoint ,然后涉及容错文件的系统工作,HDFS的检查点,把这些数据写入到检查点上,做高可用的数据存储,后面有节点宕机,数据丢失,可以从检查点的RDD计算,不需要从头到尾。
RDD执行流程
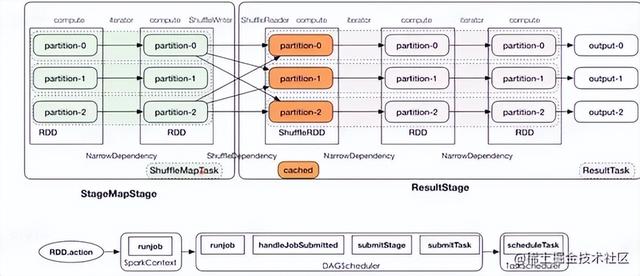
Job:RDD action算子触发 Stage:依据宽依赖划分 Task:Stage内执行单个partition任务 从后往前划分,遇到一个宽依赖,划分一个stage,遇到窄依赖就加入到这个stage,DAG最后一个阶段生成的partition生成的task叫Result Task,其余的satge叫ShuffleMapTask因为都有一个Shuffle操作。最后一个RDD partition的数量就决定了每个stage task的数量。

一个action算子怎么去触发Job,到如何调度?
调度器
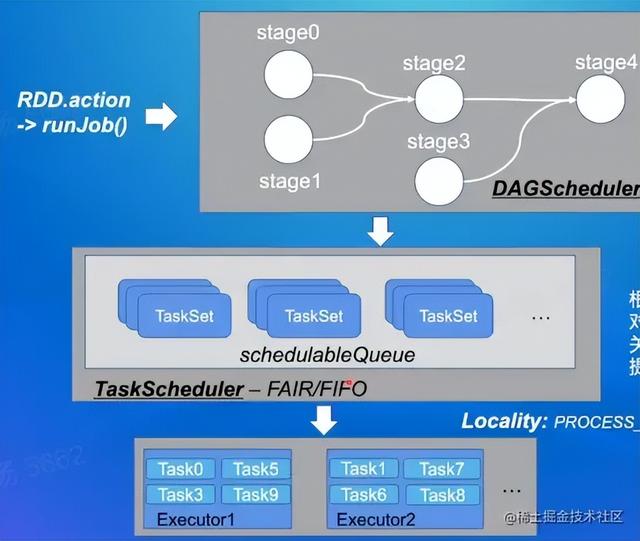
- 当一个RDD的算子创建之后,Sparkcontext就会根据RDD对象创建一个DAG有向无环图,触发job之后,将DAG提供给调度器,然后调度器根据ShuffleDependency分为不同的Stage,然后按照依赖顺序调度Stage,为每个Stage生成TaskSet集合并分发到TaskScheduler。
- 通过集群中的 资源管理器 ,在K8S模式下是master,在YARN模式下是result manager根据调度算法(FIFO/FAIR)对多个TaskSet进行调度,对于调度到的TaskSet,会将Task调度(locality)到相关Executor上面执行。
3. 内存管理
Executor内存主要有两类:Storage、Execution

启动Spark时,会设置一个spark.executor.memory参数,JVM的内存,堆内内存。 缓存RDD数据或者广播数据,占用内存叫做存储内存Storage Memory。在处理shuffle时占用的内存叫执行内存Execution Memory,剩余的用户自定义数据结构,还有一些Spark 内部的元数据,定义为User Memory。
前两种内存可以互相借用,可以减少spill的操作,执行内存是不能够被存储内存所驱逐的,但执行内存需要内存时,可以驱逐被Storage借用的内存,直到达到一个规定的存储内存的边界。当双方空间都不足时,都需要存储到硬盘上。
为了进一步优化内存的使用,提高Shuffle的排序效率,Spark引入了堆外内存(。可以直接操作操作系统堆外内存,减少不必要的内存开销,扫描回收等,管理难度低,误差比较小。
多任务间内存分配
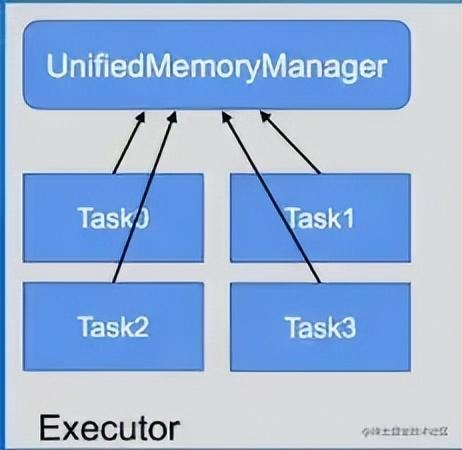
在一个Executor内,所有的task是共享内存的,UnifiedMemoryManager统一管理多个并发Task的内存分配,Executor下可以运行多个task,每个task至少要获取1/2n的空间,如果不能满足,任务就会被阻塞,直到有足够的空间,任务才会被唤醒,n为当前Executor中正在并发运行的task数量。
Shuffle
map跟reduce之间数据处理重新分发的过程称之为Shuffle,创建一个ShuffleManger,在shuffleRDD compute逻辑执行的时候会从,env里面get实现具体函数。
SortShuffleManger
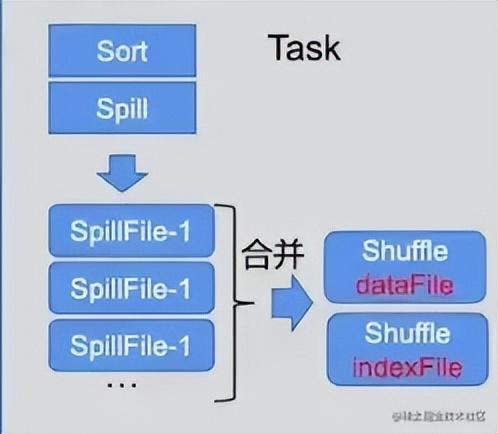
SortShuffleManger是Manager的一个实现方式,这个是两个数据量表大的时候常用的方法。对数据进行排序,Spill,产生多个零时的Spill磁盘文件,SpillFile,在最后,零时文件会合并成一个磁盘文件,为这些磁盘文件加一个索引,会产生两个文件,一个数据文件,一个索引文件。在下一个stage来的时候,在索引文件中找到partition所在的数据文件的位置,再在数据文件中找到数据。
External Shuffle Service
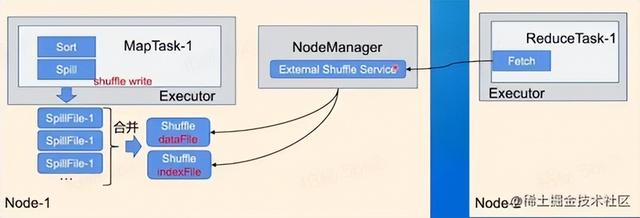
External Shuffle Service运行在主机上,管理这台主机Executor节点产生的shuffle数据,在YARN上就是NodeManager管理,只处理来自于map节点和reduce节点的请求,map节点会将Shuffle的文件路径告诉shuffle service,reduce端去读取数据的时候就会发送一个请求获取stream id,再去获取数据。
三、SparkSQL原理解析
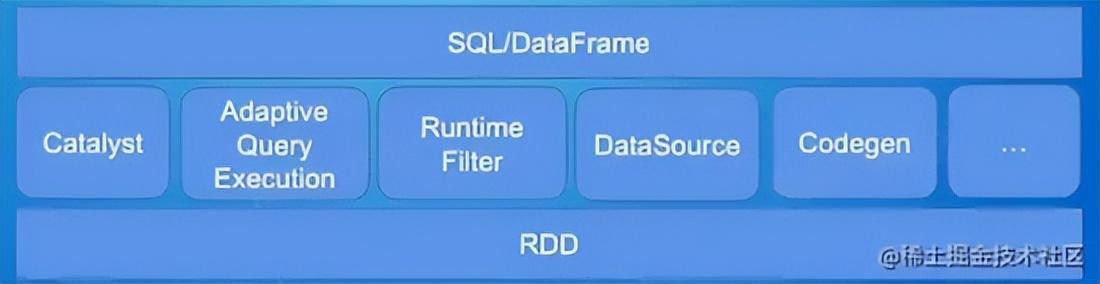
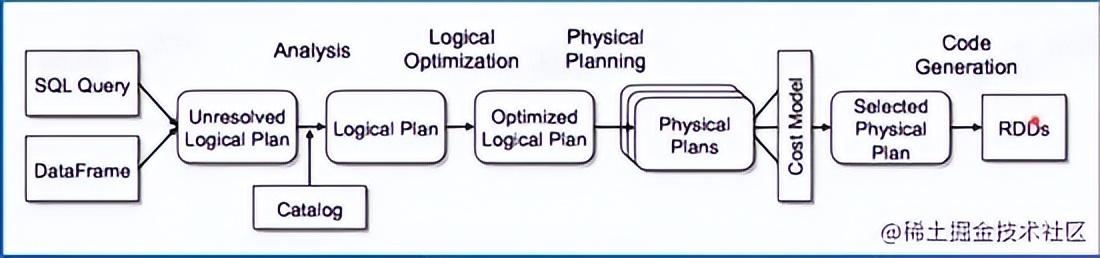
1.SparkSQL执行过程
- SQL Parse: 将SparkSQL字符串或DataFrame解析为一个抽象语法树/AST,即Unresolved Logical Plan
- Analysis:遍历整个AST,并对AST上的每个节点进行数据类型的绑定以及函数绑定,然后根据元数据信息Catalog对数据表中的字段进行解析。 利用Catalog信息将Unresolved Logical Plan解析成Analyzed Logical plan
- Logical Optimization:该模块是Catalyst的核心,主要分为RBO和CBO两种优化策略,其中RBO是基于规则优化,CBO是基于代价优化。 利用一些规则将Analyzed Logical plan解析成Optimized Logic plan
- Physical Planning: Logical plan是不能被spark执行的,这个过程是把Logic plan转换为多个Physical plans物理执行计划
- CostModel: 主要根据过去的性能统计数据,选择最佳的物理执行计划(Selected Physical Plan)。
- Code Generation: SQL 逻辑生成 Java 字节码
影响SparkSQL性能两大技术:
- Optimizer:执行计划的优化,目标是找出最优的执行计划
- runtime :运行时优化,目标是在既定的执行计划下尽可能快的执行完毕。
2. Catalyst优化
- Rule Based Optimizer(RBO): 基于规则优化,对语法树进行一次遍历,模式匹配能够满足特定规则的节点,再进行相应的等价转换。
- Cost Based Optimizer(CBO): 基于代价优化,根据优化规则对关系表达式进行转换,生成多个执行计划,然后CBO会通过根据统计信息(Statistics)和代价模型(Cost Model)计算各种可能执行计划的代价,从中选用COST最低的执行方案,作为实际运行方案。CBO依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择。
3.AQE
AQE对于整体的Spark SQL的执行过程做了相应的调整和优化,它最大的亮点是可以根据已经完成的计划结点真实且精确的执行统计结果来不停的反馈并重新优化剩下的执行计划。
AQE框架三种优化场景(3.0版本):
- 动态合并shuffle分区(Dynamically coalescing shuffle partitions)
- 动态调整Join策略(Dynamically switching join strategies)
- 动态优化数据倾斜Join(Dynamically optimizing skew joins)
处理的数据是比较大的,shuffle比较影响性能,这个算子比较费时,partition的个数非常关键,很难确定partition的数目应该是多少
4.RuntimeFilter
在join中形成filter算子进行优化。实现在Catalyst中。动态获取Filter内容做相关优化,当我们将一张大表和一张小表等值连接时,我们可以从小表侧收集一些统计信息,并在执行join前将其用于大表的扫描,进行分区修剪或数据过滤。
Runtime优化分两类:
- 全局优化:从提升全局资源利用率、消除数据倾斜、降低IO等角度做优化。包括AQE。
- 局部优化:提高某个task的执行效率,主要从提高CPU与内存利用率的角度进行优化。依赖Codegen技术。
5.Codegen
前面是优化执行计划,找出最优的执行计划。另一种是在运行时优化,如何尽快的完成优化,提高全局利用率,消除数据倾斜,提高数据利用率。另一方面就是Codegen,局部优化,提高task的效率,从提高 CPU 与内存的利用率的角度来进行runtime优化。
- Expression级别
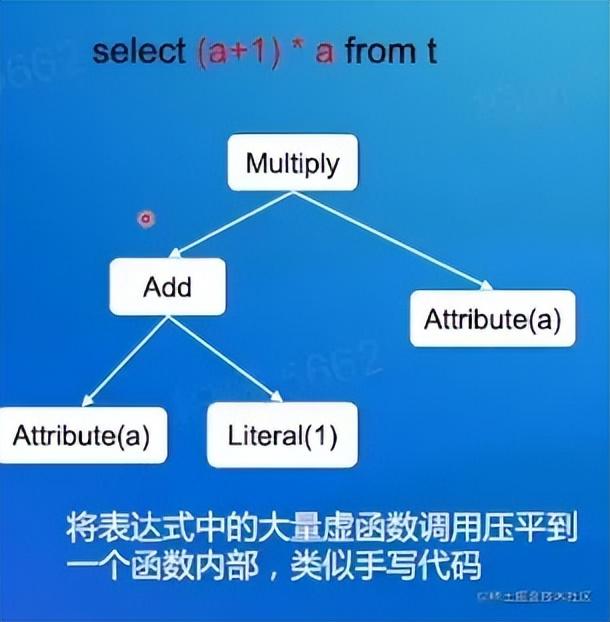
表达式常规递归求值语法树。需要做很多类型匹配、虚函数调用、对象创建等额外逻辑,这些 overhead 远超对表达式求值本身,为了消除这些overhead,Spark Codegen直接拼成求值表达式的java代码并进行即时编译
- WholeStage级别

传统的火山模型:SQL经过解析会生成一颗查询树,查询树的每个节点为 operator ,火山模型把operator看成迭代器,每个 迭代器 提供一个next()接口。通过自顶向下的调用 next 接口,数据则自底向上的被拉取处理,火山模型的这种处理方式也称为拉取执行模型,每个Operator 只要关心自己的处理逻辑即可,耦合性低。
火山模型问题:数据以行为单位进行处理,不利于CPU cache 发挥作用;每处理一行需要调用多次next() 函数,而next()为虚函数调用。会有大量类型转换和 虚函数 调用。虚函数调用会导致CPU分支预测失败,从而导致严重的性能回退
Spark WholestageCodegen:为了消除这些overhead,会为物理计划生成类型确定的java代码。并进行即时编译和执行。
Codegen打破了Stage内部算子间的界限,拼出来跟原来的逻辑保持一致的裸的代码(通常是一个大循环)然后把拼成的代码编译成 可执行文件 。
四、业界挑战与实践
1.Shuffle稳定问题
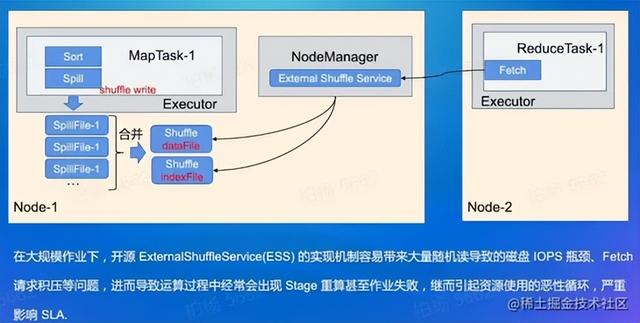
在大规模作业下,存在本地磁盘上,没有备份,有大量的请求,数量级很大,有热点数据反复读,spill数据会带来写放大,reduce高并发读取小数据块会带来磁盘随机访问的问题,也是低效率的问题,NodeManager的模块也会经常JC。 解决方案:
- 数据远端存储
- 在partition端shuffle的时候进行聚合,少了很多排序的操作
2.SQL执行性能问题
CPU流水线/分支预测/乱序执行/ CPU缓存 友好/SIMD/… 向量法/Codegen/两者结合,例如 Intel :OAP
3.参数推荐/作业诊断
Spark参数很多,参数不合理的作业,对资源利用率/Shuffle稳定性/性能有非常大影响。 自动化参数推荐/作业诊断——自动化


