一、JVM进程内存占用图像
图像拆解解析
用户态虚拟内存、内核态虚拟内存,动态映射与线性映射
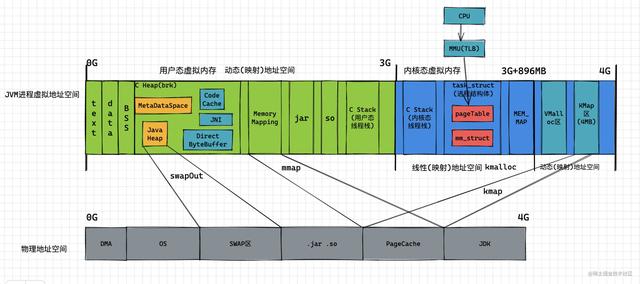
上图中机器持有4G的物理内存,JVM进程则对应4G的虚拟内存空间(物理内存与虚拟内存大小并不需要保持一致); PS:为什么以4G(32位)为例,因为64位的设计因为地址空间足够反而简单一些。
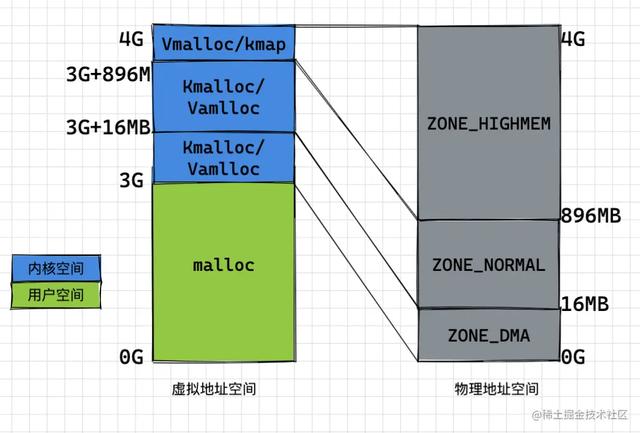
可以看到在虚拟地址空间中,0G~3G的虚拟地址空间为用户空间,3G~4G的虚拟地址空间为内核空间; 因为 CPU 是通过虚拟地址进行内存访问,而内核空间需要访问所有的物理地址,所以需要在1G的内核空间映射4G的物理地址 ;
- 内核在3G~3G+896MB的空间中进行 线性映射 ,即从物理地址0~896MB的部分(ZONE_DMA+ZONE_NORMAL),直接加上3GB的偏移(在Linux中用PAGE_OFFSET表示);
- 在3G+896MB~4G的空间中进行 动态映射 ,即对于ZONE_HIGHMEM中的某段物理内存和这128M中的某段虚拟空间建立映射,完成所需操作后,需要断开与这部分虚拟空间的映射关系,以便ZONE_HIGHMEM中其他的物理内存可以继续往这个区域映射;
PS:为什么 内核 空间需要访问所有的物理地址,举个简单的例子,对于read某个磁盘文件的调用,需要将 pageCache 中的数据拷贝到用户空间的缓冲区中,所以内核空间需要访问所有的物理地址;
JVM进程载入,操作系统进行进程初始化
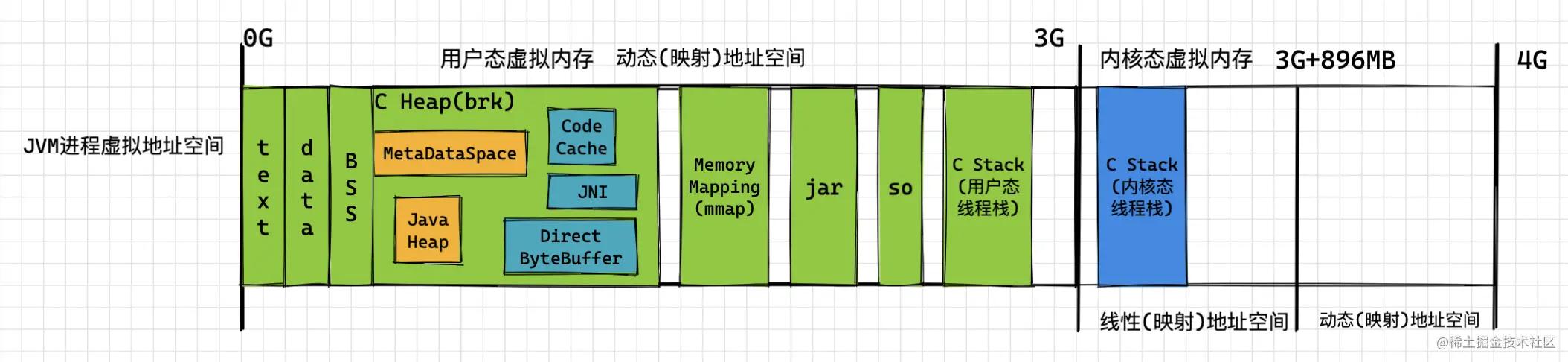
首先,Linux会通过JVM的ELF(进程的二进制代码)进行进程启动,并放入上图中最左侧的 text段 (只读)
- 在初始化过程中, data段 存储已初始化的 全局变量 , bss段 存储未初始化的全局变量, C stack段 也就建立了;
- 接着在JVM进程运行的过程中,需要加载一些lib.so的动态链接库,或者通过mmap进行一些共享内存的映射;
- 然后HotSpot会通过brk(mmap)进行C heap的扩展,并在C heap中进行 Java Heap、MetaSpace区域的初始化;初始化的过程中, 会通过Java堆中的ClassLoader将jar中的. class文件 加载到metaDataSpace中,并在堆中生成对应的class对象 ;
- 在执行过程中,会进行一些 线程 的初始化, 因为HotSpot采用的是Java线程与操作系统线程为1:1的线程模型 ,因此在Linux下会直接调用glibc的 pthread _create进行线程创建,并为该线程创建一套栈(内核栈与用户栈),内核栈用于线程陷入内核态时进行使用,而HotSpot对于JVM概念中的Java栈与本地方法栈,则是将JVM栈与本地方法栈二合一,使用 用户栈 进行实现;具体的代码分析可以参考这篇博客:JVM线程源码浅析-JVM线程如何映射到操作系统线程 – 掘金 (juejin.cn)
二、绕过JVM管理进行内存使用的方式
为什么使用内存要绕过JVM的内存管理(主要是GC)? 《深入理解Java虚拟机》第二章的引言我觉得恰到好处,“Java与C++之间有一堵由内存动态分配和垃圾收集技术所围成的高墙,墙外面的人想进去,墙里面的人却想出来。”
站在内存使用的角度来讲:1)JVM中一切皆对象,数据的对象存储会带来所谓object overhead ,浪费空间;2)如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量; 并且GC会导致对象移动,改变了对象的地址,对于数据buffer而言即为没有稳定的地址,与一些系统调用不能很好适配
使用Native堆(直接内存、DirectByteBuffer)
Native堆指不由JVM直接管理的C Heap(除了JavaHeap、MetaDataSpace等JVM运行时占用的剩余空间),一般通过UnSafe.allocateMemory、 Byte Buffer.allocateDirect等navtie方法进行申请,并通过存储在 JVM堆 中的DirectByteBuffer对象作为对这块内存的引用进行操作;
Java中的NIO类使用native方法申请直接内存,以此避免在JVM堆和 native堆 中来回复制数据,提高效率; 但是从native堆到JVM堆的 copy 是因为JVM本身机制的限制 ,因为write、read等系统调用都需要传入读/写buffer的起始地址和buffer count作为参数,这两个参数使得JVM需要进行 冗余 的内存拷贝:
- GC机制的限制:因为JVM会进行GC,会导致JVM堆中的buffer(byte[],即HeapByteBuffer)进行移动,所以在Java BIO时需要mark此段内存不能移动,从而影响GC效率;而另一种方式是将byte[] 复制到到C Heap,并通过DirectByteBuffer进行引用,即使发生GC,JVM堆内的DirectByteBuffer发生地址变化也不会影响buffer的地址,比较稳定。 因此相比于copy到C Heap,不如直接读写DirectByteBuffer,也就避免了一次多余的内存拷贝。
- JVM内存使用的限制,JVM规范中byte[]并不一定需要在连续的虚拟地址空间中,但是 write 、read这类系统调用需要连续的地址空间,但是C Heap中分配的内存可以是连续的。
不过因为JVM是用户进程,对于直接内存JVM使用malloc进行内存申请,因此比一般在堆内申请内存慢,因此一般使用NIO的网络框架都会维护对自身使用的直接内存进行池化,避免频繁申请释放的同时,也是避免 内存泄漏 。
PS:设置-XX:NativeMemoryTracking=detail,可以通过jcmd pid VM.native_memory detail命令查看直接内存的内存分布
文件读取(Java FileChannel)
对于 kafka 这种会使用pageCache进行有序读、追加写的Java应用而言,对于内存中pageCache的使用尤为关键。
- 当生产者发送生产请求到kafka broker时,broker使用 File Channel.write()(对应pwrite系统调用),将数据按照 文件偏移量 先写到pageCache中,然后再等待flusher异步线程刷到磁盘中。因为kakfa采用稀疏索引,写入一定量后会使用FileChannel.map()(对应mmap系统调用,用户空间位置在第一张内存图中的MemoryMapping段)生成的MappedByteBuffer对索引文件进行写入;
- 当消费者发送消费请求到kafka broker时,broker使用FileChannel.transferTo(对应sendFile系统调用),将数据从pageCache传输到broker的Socket buffer,再通过网络传输。
对于kafka这类的系统而言,这些数据也无需拷贝到JVM中去,利用操作系统自身的机制便可以管理的很好;因此一般kafka的服务堆可以设置小一些,将更多的内存分配给pageCache,有更好的吞吐量。
PS:当然不是读文件都一定都会经过pageCache,比如对于 Mysql 而言,在进行读文件的时候,会设置O_DIRECT绕过pageCache,因为pageCache是以文件为缓存单元进行管理,Mysql中存在一些抽象概念,诸如 表空间 ..,这些抽象概念会用于查询,但与文件并不是一一对应的关系,所以Mysql自己维护了一个缓存池(BufferPool),可以基于自身的抽象概念进行查询。
三、总结
本文主要介绍了从JVM进程角度看JVM内存空间占用的视角;借助Kafka对FileChannel的使用介绍了Java如何使用pageCache,并借助NIO分析了为什么要使用直接内存;本地内存中还有JNI Memory 、CodeCache,因为 JNI 的内容相对较多,后面会单独写。
原文:


