一 Hbase 简介
HBase 是一个 高可靠性 、 高性能 、 面向列 、 可伸缩 的分布式存储系统,利用 HBase 技术可在廉价 PC Server 上搭建起大规模结构化存储集群。HBase 的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。HBase 是 的开源实现,但是也有很多不同之处。比如:Google Bigtable 利用 GFS 作为其文件存储系统,HBase 利用 Hadoop hdfs 作为其文件存储系统; Google 运行 MAPREDUCE 来处理 Bigtable 中的海量数据,HBase 同样利用 Hadoop MapReduce 来处理 HBASE 中的海量数据;Google Bigtable 利用 Chubby 作为协同服务,HBase 利用 Zookeeper 作为对应。它介于 nosql 和 RDBMS 之间,仅能通过主键(row key)和主键的 range 来检索数据,仅支持单行事务(可通过 hive 支持来实现多表 join 等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
- HBase 与 mysql 、oralce、 db2 、 sqlserver 等关系型数据库不同,它是一个 NoSQL 数据库( 非关系型数据库 )
- HBase 的表模型与 关系型数据库 的表模型不同:
- HBase 与 mysql、oralce、db2、sqlserver 等关系型数据库不同,它是一个 NoSQL 数据库(非关系型数据库)
- HBase 的表模型与关系型数据库的表模型不同:
- HBase 的表没有固定的字段定义;
- HBase 的表中每行存储的都是一些 key-value 对;
- Hbase 的表中有列族的划分,用户可以指定将哪些 kv 插入哪个列族;
- Hbase 的表在物理存储上,是按照列族来分割的,不同列族的数据一定存储在不同的文件中;
- Hbase 的表中的每一行都固定有一个行键,而且每一行的行键在表中不能重复;
- Hbase 中的数据,包含行键,包含 key,包含 value,都是 byte []类型,hbase 不负责为用户维护数据类型;
- HBASE 对事务的支持很差;
- HBASE 相比于其他 nosql 数据库(mongodb、 redis 、cassendra、hazelcast)的特点:
- Hbase 的表数据存储在 HDFS 文件系统中,所以,hbase 具备如下特性:
- 海量存储
- 列式存储
- 数据存储的安全性可靠性极高
- 支持高并发
- 存储容量可以线性扩展
二 HBase 表的数据模型

1 rowkey 行键
table 的主键,table 中的记录按照 rowkey 的字典序进行排序 Row key 行键可以是任意 字符串 (最大长度是 64KB,实际应用中长度一般为 10-100bytes)
2 Column Family 列族
列族或列簇 HBase 表中的每个列,都归属与某个列族 列族是表的 schema 的一部分(而列不是),即建表时至少指定一个列族 比如创建一张表,名为 user,有两个列族,分别是 info 和 data,建表语句 create ‘user’, ‘info’, ‘data’
3 Column 列
列肯定是表的某一列族下的一个列,用列族名:列名表示,如 info 列族下的 name 列,表示为 info:name 属于某一个 ColumnFamily,类似于我们 mysql 当中创建的具体的列
4 cell 单元格
指定 row key 行键、列族、列,可以确定的一个 cell 单元格 cell 中的数据是没有类型的,全部是以字节数组进行存储
5 timestamp 时间戳
可以对表中的 Cell 多次赋值,每次赋值操作时的时间戳 timestamp,可看成 Cell 值的版本号 version number ;即一个 Cell 可以有多个版本的值
三 HBase 整体架构
1 Client 客户端
Client 是操作 HBase 集群的入口;对于管理类的操作,如表的增、删、改操纵,Client 通过 RPC 与 HMaster 通信完成;对于表数据的读写操作,Client 通过 RPC 与 RegionServer 交互,读写数据 Client 类型:HBase shell java 编程接口 Thrift、Avro、Rest 等等
2 ZooKeeper 集群
作用: 实现了 HMaster 的高可用,多 HMaster 间进行主备选举;保存了 HBase 的元数据信息 meta 表,提供了 HBase 表中 region 的寻址入口的线索数据;对 HMaster 和 HRegionServer 实现了监控;
3 HMaster
HBase 集群也是主从架构,HMaster 是主的角色,是老大 主要负责 Table 表和 Region 的相关管理工作:关于 Table 管理 Client 对 Table 的增删改的操作 关于 Region 在 Region 分裂后,负责新 Region 分配到指定的 HRegionServer 上 管理 HRegionServer 间的负载均衡,迁移 region 分布 当 HRegionServer 宕机后,负责其上的 region 的迁移
4 HRegionServer
HBase 集群中的从角色,是小弟 作用:响应客户端的读写数据请求 负责管理一系列的 Region 切分在运行过程中变大的 region
5 Region
HBase 集群中分布式存储的最小单元 一个 Region 对应一个 Table 表的部分数据 HBase 使用,主要有两种形式:① 命令;② Java 编程
四 HBase 安装
HBASE 是一个分布式系统 其中有一个管理角色:HMaster(一般 2 台,一台 active,一台 backup) 其他的数据节点角色:HRegionServer(很多台,看数据量)
1 安装准备
需要先有一个 java 环境 首先,要有一个 HDFS 集群,并正常运行;regionserver 应该跟 hdfs 中的 datanode 在一起 其次,还需要一个 zookeeper 集群,并正常运行,然后,安装 HBase 角色分配如下:Hdp01: namenode datanode regionserver hmaster zookeeper Hdp02: datanode regionserver zookeeper Hdp03: datanode regionserver zookeeper
2 安装步骤
解压 HBase 安装包 修改 hbase-env.sh
export JAVA_HOME=/ root /apps/jdk1.7.0_67
export HBASE_MANAGES_ZK=false
修改 hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hdp01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hdp01:2181,hdp02:2181,hdp03:2181</value>
</property>
</configuration>
修改 regionservers
hdp01
hdp02
hdp03
3 启动 HBase 集群
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/start-hbase.sh
启动完后,还可以在集群中找任意一台机器启动一个备用的 master
bin/hbase-daemon.sh start master
新启的这个 master 会处于 backup 状态
4 停止 HBase 集群
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/stop-hbase.sh
五 HBase shell 命令基本操作
1 进入 HBase 客户端命令操作界面
node01 执行以下命令,进入 HBase 的 shell 客户端
cd /kkb/install/hbase-1.2.0-cdh5.14.2
bin/hbase shell

如果出现下图所示情况,说明 HBase 未正常启动

以下为正常启动页面,并且有相关进程

① list 查看当前数据库中有哪些表

② 查看 HBase 集群状态
③ 查看 HBase 集群版本
ps: NameSpace 操作
HBase 系统默认定义了两个缺省的 namespace
hbase:系统内建表,包括 namespace 和 meta 表
default:用户建表时未指定 namespace 的表都创建在此
创建:create_namespace 'lzc'
删除:drop_namespace 'lzc'
查看:describe_namespace 'lzc'
列出所有:list_namespace
在 namespace 下创建表:create 'lzc:user_info','id','name','age'
查看 namespace 下的表 :list_namespace_tables 'lzc'
2 HBase 表模型特点

1.一个表,有表名
2.一个表可以分为多个列族(不同列族的数据会存储在不同文件中)
3.表中的每一行有一个“行键 rowkey”,而且行键在表中不能重复
4.表中的每一对 kv 数据称作一个 cell
5.hbase 可以对数据存储多个历史版本(历史版本数量可配置)
6.整张表由于数据量过大,会被横向切分成若干个 region(用 rowkey 范围标识),不同 region 的数据也存储在不同文件中

7.hbase 会对插入的数据按顺序存储:要点一:首先会按行键排序 要点二:同一行里面的 kv 会按列族排序,再按 k 排序
3 HBase 数据类型
hbase 中只支持 byte[] 此处的 byte[] 包括了:rowkey,key,value,列族名,表名
4 HBase 命令行操作
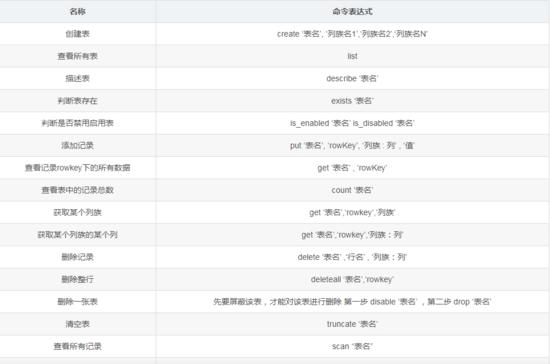
① help 帮助命令 hbase(main):005:0> help

查看具体命令的帮助信息 hbase(main):006:0> help ‘create’

② create 创建表 创建 user 表,包含 info、data 两个列族 使用 create 命令 hbase(main):008:0> create ‘user’, ‘info’, ‘data’ 0 row(s) in 1.3080 seconds 或者 => Hbase::Table – user hbase(main):009:0> create ‘user’,{NAME => ‘info’, VERSIONS => ‘3’},{NAME => ‘data’} ERROR: Table already exists : user!

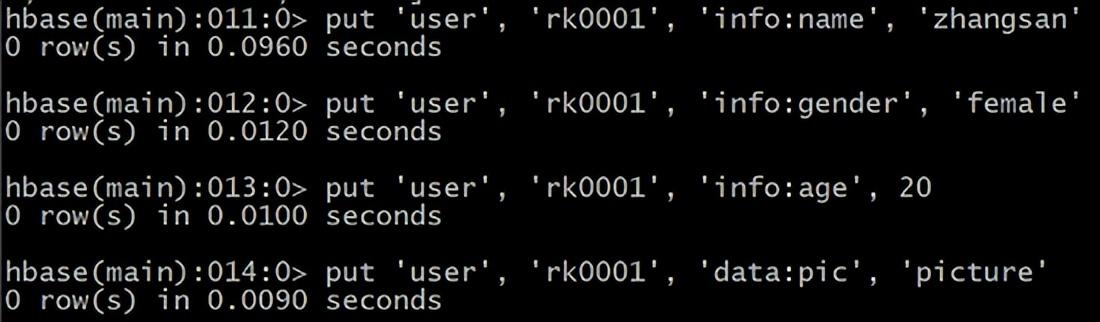
③ put 插入数据操作 向表中插入数据 使用 put 命令 向 user 表中插入信息,row key 为 rk0001,列族 info 中添加名为 name 的列,值为 zhangsan HBase(main):011:0> put ‘user’, ‘rk0001’, ‘info:name’, ‘zhangsan’
向 user 表中插入信息,row key 为 rk0001,列族 info 中添加名为 gender 的列,值为 female HBase(main):012:0> put ‘user’, ‘rk0001’, ‘info:gender’, ‘female’
向 user 表中插入信息,row key 为 rk0001,列族 info 中添加名为 age 的列,值为 20 HBase(main):013:0> put ‘user’, ‘rk0001’, ‘info:age’, 20
向 user 表中插入信息,row key 为 rk0001,列族 data 中添加名为 pic 的列,值为 picture HBase(main):014:0> put ‘user’, ‘rk0001’, ‘data:pic’, ‘picture’
④ 查询数据操作一 查询方式一 使用 get 命令通过 rowkey 进行查询 获取 user 表中 row key 为 rk0001 的所有信息(即所有 cell 的数据) 使用 get 命令 HBase(main):015:0> get ‘user’, ‘rk0001’

使用 get 命令查看 rowkey 下某个列族的信息 获取 user 表中 row key 为 rk0001,info 列族的所有信息 HBase(main):016:0> get ‘user’, ‘rk0001’, ‘info’

使用 get 命令查看 rowkey 指定列族指定字段的值 获取 user 表中 row key 为 rk0001,info 列族的 name、age 列的信息 HBase(main):017:0> get ‘user’, ‘rk0001’, ‘info:name’, ‘info:age’


使用 get 命令查看 rowkey 指定多个列族的信息 获取 user 表中 row key 为 rk0001,info、data 列族的信息 HBase(main):018:0> get ‘user’, ‘rk0001’, ‘info’, ‘data’
或者你也可以这样写 HBase(main):019:0> get ‘user’, ‘rk0001’, {COLUMN => [‘info’, ‘data’]}
或者你也可以这样写,也行 HBase(main):020:0> get ‘user’, ‘rk0001’, {COLUMN => [‘info:name’, ‘data:pic’]}

使用 get 命令指定 rowkey 与列值过滤器查询 获取 user 表中 row key 为 rk0001,cell 的值为 zhangsan 的信息 HBase(main):021:0> get ‘user’, ‘rk0001’, {FILTER => “ValueFilter(=, ‘binary:zhangsan’)”}
使用 get 命令指定 rowkey 与列名模糊查询 获取 user 表中 row key 为 rk0001,列标示符中含有 a 的信息 HBase(main):022:0> get ‘user’, ‘rk0001’, {FILTER => ” Qualifier Filter(=,’substring:a’)”}

继续插入一批数据 HBase(main):023:0> put ‘user’, ‘rk0002’, ‘info:name’, ‘fanbingbing’ HBase(main):024:0> put ‘user’, ‘rk0002’, ‘info:gender’, ‘female’ HBase(main):025:0> put ‘user’, ‘rk0002’, ‘info:nationality’, ‘中国’ HBase(main):026:0> get ‘user’, ‘rk0002’, {FILTER => “ValueFilter(=, ‘binary:中国’)”}

⑤ 查询所有行的数据二查询 user 表中的所有信息 使用 scan 命令 HBase(main):027:0> scan ‘user’

使用 scan 命令进行列族查询 查询 user 表中列族为 info 的信息
scan ‘user’, {COLUMNS => ‘info’}

//当把某些列的值删除后,具体的数据并不会马上从存储文件中删除;查询的时候,不显示被删除的数据;如果想要查询出来的话, RAW => true scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 5}

scan ‘user’, {COLUMNS => ‘info’, RAW => true, VERSIONS => 3}

使用 scan 命令进行多列族查询 查询 user 表中列族为 info 和 data 的信息 scan ‘user’, {COLUMNS => [‘info’, ‘data’]}

使用 scan 命令指定列族与某个列名查询 查询 user 表中列族为 info、列标示符为 name 的信息 scan ‘user’, {COLUMNS => ‘info:name’}

查询 info:name 列、data:pic 列的数据 scan ‘user’, {COLUMNS => [‘info:name’, ‘data:pic’]}

查询 user 表中列族为 info、列标示符为 name 的信息,并且版本最新的 5 个 scan ‘user’, {COLUMNS => ‘info:name’, VERSIONS => 5}

使用 scan 命令指定多个列族与条件模糊查询 查询 user 表中列族为 info 和 data 且列标示符中含有 a 字符的信息 scan ‘user’, {COLUMNS => [‘info’, ‘data’], FILTER => “QualifierFilter(=,’substring:a’)”}

使用 scan 命令指定 rowkey 的范围查询 查询 user 表中列族为 info,rk 范围是[rk0001, rk0003)的数据 scan ‘user’, {COLUMNS => ‘info’, STARTROW => ‘rk0001’, ENDROW => ‘rk0003’}

使用 scan 命令指定 rowkey 模糊查询 查询 user 表中 row key 以 rk 字符开头的数据

使用 scan 命令指定数据版本的范围查询 查询 user 表中指定范围的数据(前闭后开) scan ‘user’, {TIMERANGE => [1392368783980, 1392380169184]}
hbase(main):039:0> scan ‘user’, {TIMERANGE => [1615386788707,1615386809222]}

⑥ 更新数据操作 1 更新数据值 更新操作同插入操作一模一样,只不过有数据就更新,没数据就添加 使用 put 命令 2 更新版本号 将 user 表的 f1 列族版本数改为 5 HBase(main):040:0> alter ‘user’, NAME => ‘info’, VERSIONS => 5

⑦ 删除数据以及删除表操作 1 指定 rowkey 以及列名进行删除 删除 user 表 row key 为 rk0001,列标示符为 info:name 的数据(删除一个 kv 数据) HBase(main):041:0> delete ‘user’, ‘rk0001’, ‘info:name’
删除整行数据
hbase(main):024:0> deleteall 't_user_info','001'
0 row(s) in 0.0090 seconds
hbase(main):025:0> get 't_user_info','001'
COLUMN CELL
0 row(s) in 0.0110 seconds
2 指定 rowkey,列名以及版本号进行删除 删除 user 表 row key 为 rk0001,列标示符为 info:name,timestamp 为 1392383705316 的数据 hbase(main):042:0> delete ‘user’, ‘rk0001’, ‘info:name’, 1392383705316
3 删除一个列族 删除一个列族:alter ‘user’, NAME => ‘info’, METHOD => ‘delete’ 或 alter ‘user’, ‘delete’ => ‘info’

4 清空表数据 HBase(main):045:0> truncate ‘user’

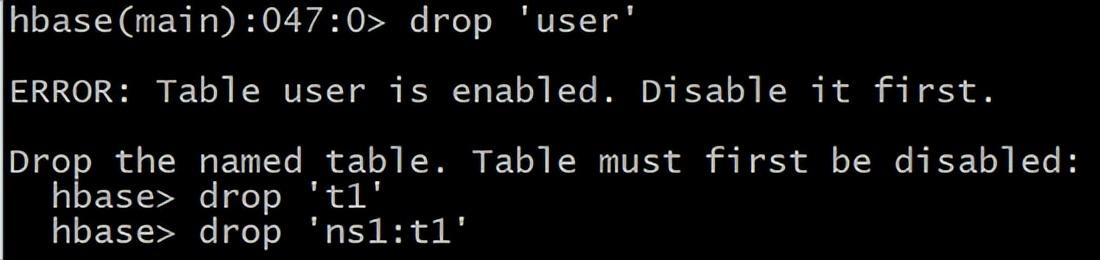
5 删除表 首先需要先让该表为 disable 状态,使用命令:HBase(main):049:0> disable ‘user’ 然后使用 drop 命令删除这个表 HBase(main):050:0> drop ‘user’
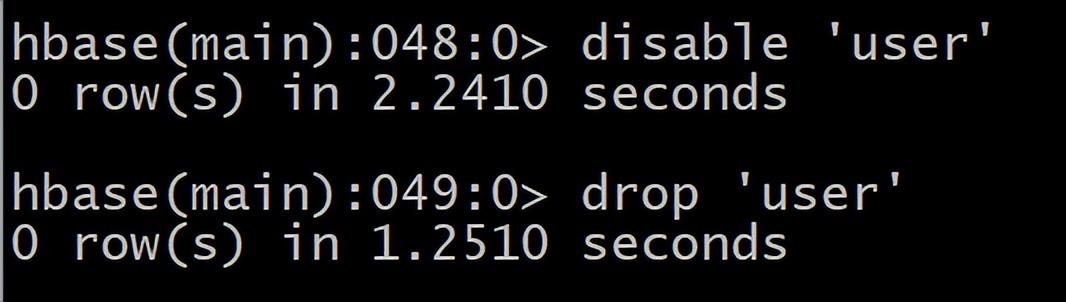
(注意:如果直接 drop 表,会报错:Drop the named table. Table must first be disabled)
⑧ 统计一张表有多少行数据 HBase(main):046:0> count ‘user’

六 HBase 的高级 shell 管理命令
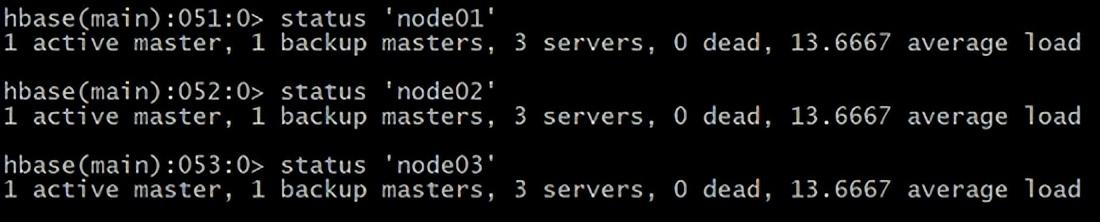
1 status 例如:显示服务器状态 HBase(main):051:0> status ‘node01’
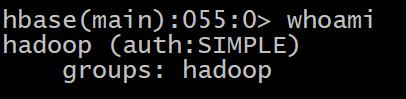
2 whoami 显示 HBase 当前用户,例如:HBase> whoami
3 list 显示当前所有的表 HBase > list

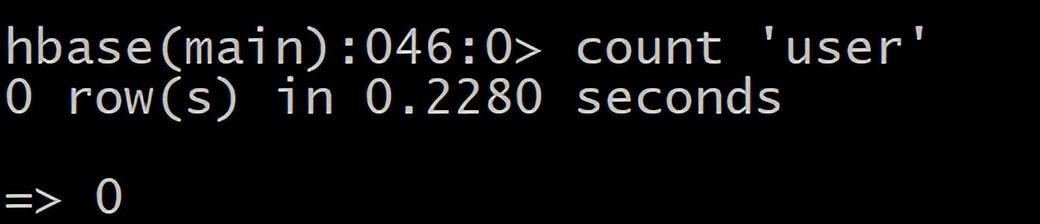
4 count 统计指定表的记录数,例如:HBase> count ‘user’
为了展示下面功能,然后重新创建 user 表,并插入数据 创建 user 表,包含 info、data 两个列族 使用 create 命令
hbase(main):008:0> create 'user', 'info', 'data'
0 row(s) in 1.3080 seconds
向表中插入数据 使用 put 命令 向 user 表中插入信息,row key 为 rk0001,列族 info 中添加名为 name 的列,值为 zhangsan
HBase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
向 user 表中插入信息,row key 为 rk0001,列族 info 中添加名为 gender 的列,值为 female
HBase(main):012:0> put 'user', 'rk0001', 'info:gender', 'female'
向 user 表中插入信息,row key 为 rk0001,列族 info 中添加名为 age 的列,值为 20
HBase(main):013:0> put 'user', 'rk0001', 'info:age', 20
向 user 表中插入信息,row key 为 rk0001,列族 data 中添加名为 pic 的列,值为 picture
HBase(main):014:0> put 'user', 'rk0001', 'data:pic', 'picture'

5 describe 展示表结构信息 HBase> describe ‘user’

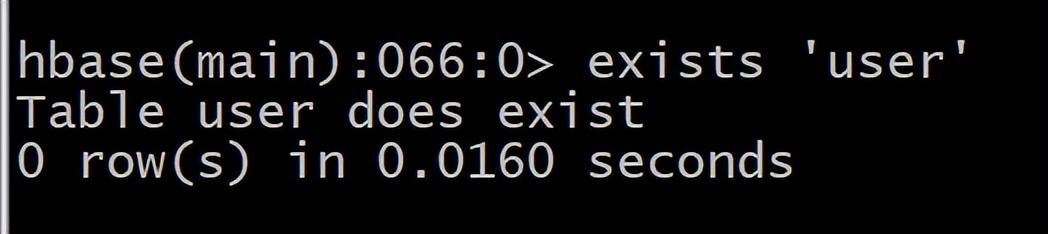
6 exists 检查表是否存在,适用于表量特别多的情况
7 is_enabled、is_disabled 检查表是否启用或禁用 HBase> is_enabled ‘user’ HBase> is_disabled ‘user’

8 alter 该命令可以改变表和列族的模式,例如:为当前表增加列族:HBase> alter ‘user’, NAME => ‘CF2’, VERSIONS => 2

为当前表删除列族:HBase(main):002:0> alter ‘user’, ‘delete’ => ‘CF2’

9 disable/enable 禁用一张表/启用一张表 HBase> disable ‘user’ HBase> enable ‘user’
10 drop 删除一张表,记得在删除表之前必须先禁用
11 truncate 禁用表-删除表-创建表
七 Hive 与 HBase 的集成
Hive 提供了与 HBase 的集成,使得能够在 HBase 表上使⽤ HQL 语句进⾏查 询 插⼊操作以及进⾏ Join 和 Union 等复杂查询、同时也可以将 hive 表中的 数据映射到 Hbase 中。
版本说明:
hbase 版本: h base-1.2.0-cdh5.14.2
hive 版本:hive-1.1.0-cdh5.14.2
数据模型:
row,addres,age,username
001,guangzhou,20,alex
002,shenzhen,34,jack
003,beijing,23,lili
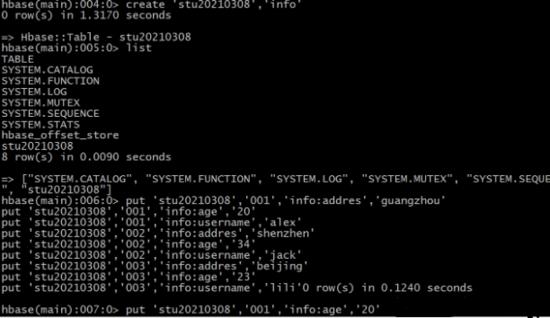
create 'stu20210308','info'
put 'stu20210308','001','info:addres','guangzhou'
put 'stu20210308','001','info:age','20'
put 'stu20210308','001','info:username','alex'
put 'stu20210308','002','info:addres','shenzhen'
put 'stu20210308','002','info:age','34'
put 'stu20210308','002','info:username','jack'
put 'stu20210308','003','info:addres','beijing'
put 'stu20210308','003','info:age','23'
put 'stu20210308','003','info:username','lili' 创建 HBase 的数据:
create 'stu20210308','info'
put 'stu20210308','001','info:addres','guangzhou'
put 'stu20210308','001','info:age','20'
put 'stu20210308','001','info:username','alex'
put 'stu20210308','002','info:addres','shenzhen'
put 'stu20210308','002','info:age','34'
put 'stu20210308','002','info:username','jack'
put 'stu20210308','003','info:addres','beijing'
put 'stu20210308','003','info:age','23'
put 'stu20210308','003','info:username','lili'
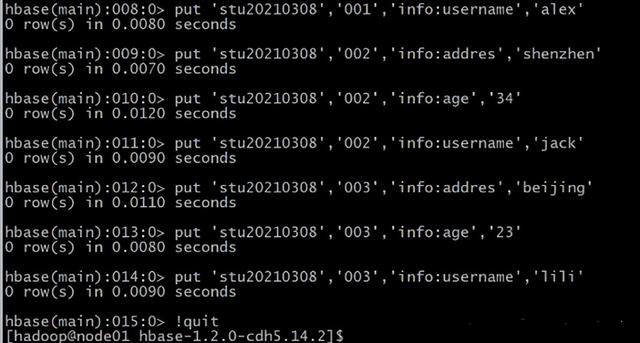
ps:退出 HBASE 指令是!quit 创建与 HBase 集成的 Hive 的外部表:
CREATE EXTERNAL TABLE stu20210308(
id string,
addres string,
age string,
username string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping" =
":key,info:addres,info:age,info:username")
TBLPROPERTIES ("hbase.table.name" = "stu20210308");
hive (test)> CREATE EXTERNAL TABLE stu20210308( > id string, > addres string, > age string, > username string) > STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' > WITH SERDEPROPERTIES ( > "hbase.columns.mapping" = > ":key,info:addres,info:age,info:username") > TBLPROPERTIES ("hbase.table.name" = "stu20210308");
OK
Time taken: 1.933 seconds
hive (test)> select * from stu20210308;
OK
stu20210308.id stu20210308.addres stu20210308.age stu20210308.username
001 guangzhou 20 alex
002 shenzhen 34 jack
003 beijing 23 lili
Time taken: 0.09 seconds, Fetched: 3 row(s)

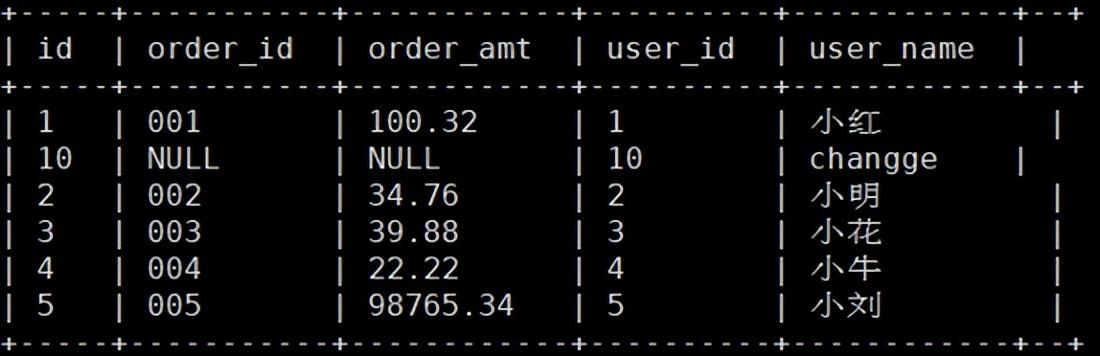
ps:具体这里可查看 Hive 与 HBase 的集成 Hive 表映射 HBase 实例二 建 HBase 表 hbase(main):018:0> create ‘user_info’,‘info’ 数据插入 HBase info:order_amt info:order_id info:user_id info:user_name

建 hive 映射表
create external table wedw_tmp.t_user_info
(
id string
,order_id string
,order_amt string
,user_id string
,user_name string
)
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping"=":key,info:order_id,info:order_amt,info:user_id,info:user_name")
tblproperties("hbase.table.name"="user_info");
查询映射好的 hive 表 select * from wedw_tmp.t_user_info;
八 HBase 客户端 API 操作
表创建 增加数据 删除数据 全表扫描 过滤器 匹配
九 phoenix 操作 HBase
Phoenix,由 saleforce.com 开源的一个项目,后又捐给了 Apache。它相当于一个 Java 中间件,帮助开发者,像 使用 jdbc 访问关系型数据库一样,访问 NoSql 数据库 HBase。Apache Phoenix 与其他 Hadoop 产品完全集成,如 Spark,Hive,Pig,Flume 和 MapReduce。
1 安装 pheonix
1.1 下载 pheonix
注意:下载 Phoenix 的时候,请注意对应的版本,其中 4.14 版本可以运行在 HBase0.98、1.1、1.2、1.3、1.4 上。下载时也可以直接使用:
wget
1.2 解压 pheonix
tar -zxvf apache-phoenix-4.14.0-HBase-1.2-bin.tar.gz
1.3 整合 phoenix 到 hbase
查看 Phoenix 下的所有的文件,将 phoenix-4.14.0-HBase-1.2-server.jar 拷贝到所有 HBase 节点(包括 Hmaster 以及 HregionServer)的 lib 目录下:
重启 HBase:
bin/stop-hbase.sh
bin/start-hbase.sh
1.4 使用 phoenix SQL 命令行
进入 Phoenix 的安装包,执行:
bin/sqlline.py bigdata1:2181
1.4.1 创建表
在 Phoenix 终端下创建 us_population 表:
> > CREATE TABLE IF NOT EXISTS us_population (
> > state CHAR(2) NOT NULL,
> > city VARCHAR NOT NULL,
> > population BIGINT
> > CONSTRAINT my_pk PRIMARY KEY (state, city));
使用!tables 查看创建的表:
> > !tables

1.4.2 编辑并导入数据
在 Phoenix 目录下创建一个 data 目录,在 data 目录下创建:vi us_population.csv
NY,New York,8143197
CA,Los Angeles,3844829
IL,Chicago,2842518
TX,Houston,2016582
PA,Philadelphia,1463281
AZ,Phoenix,1461575
TX,San Antonio,1256509
CA,San Diego,1255540
TX,Dallas,1213825
CA,San Jose,912332
执行 bin/psql.py data/us_population.csv 导入数据。除了导入数据外,还可以使用 Phoenix 的语法插入数据:upsert into us_population values(‘NY’,’NewYork’,8143197);
1.4.3 查询数据
方式一:在 data 目录下创建 us_population_queries.sql 文件:
SELECT state as "State",count(city) as "City Count",sum(population) as "Population Sum"
FROM us_population
GROUP BY state
ORDER BY sum(population) DESC;
执行 bin/psql.py data/us_population_queries.sql 检索数据。方式二:使用命令行终端
bin/sqlline.py bigdata1:2181
> > select * from us_populcation;

2 Squirrel-sql 连接 Phoenix
2.1 下载 Squirrel-sql
#installation
2.2 设置 Squirrel-sql 连接 Phoenix
拷贝 Phoenix Client jar【phoenix-4.14.0-HBase-1.2-client.jar】到 Squirrel-sql 的 lib 目录;

设置 Phoenix 连接的 Driver 信息,其中 localhost 为 zookeeper 所在的主机地址,填写一个即可。

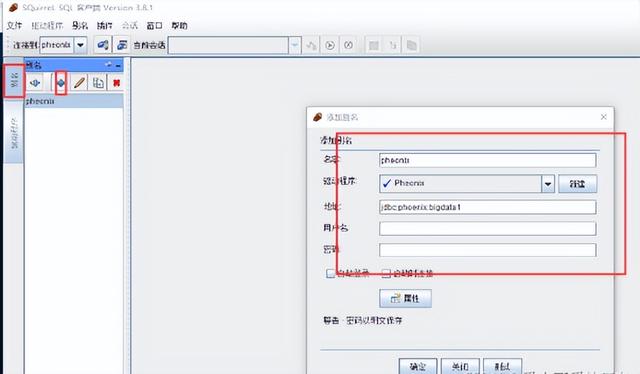
3 Phoenix 映射 Hbase 表
进入 Hbase 命令行终端 bin/hbase shell 创建 Hbase 表’phoenix’:
– 创建 Hbase 表 Phoenix,列族 info create ‘phoenix’,’info’
– 添加数据 put ‘phoenix’, ‘row001′,’info:name’,’phoenix’ put ‘phoenix’, ‘row002′,’info:name’,’hbase’
映射 HBase 表的方式有两种,一直是视图映射,一种是表映射。两者的区别就是对 HBase 的物理表有没有影响;删除 Phoenix 视图映射不会对 Hbase 的表造成影响;删除 Phoenix 表映射会将 Hbase 的表也删除;非必要情况下一般创建视图映射。
3.1 视图映射
在 Phoenix 下创建视图映射 HBase 表:
-- 创建视图关联映射 Hbase 表
create view "phoenix" (
pk VARCHAR primary key,
"info"."name" VARCHAR
);
查询创建好的 Phoenix 视图:

– 删除视图后,在 hbase shell 终端下查看 phoenix 依然存在
drop view "phoenix";
3.2 表映射
在 Phoenix 下创建表映射 HBase 表:– 创建表关联映射 Hbase 表,4.10 以后 Phoenix 优化了列映射,COLUMN_ENCODED_BYTES=0 禁用列映射。
create table "phoenix" (
pk VARCHAR primary key,
"info"."name" VARCHAR
) COLUMN_ENCODED_BYTES = 0;
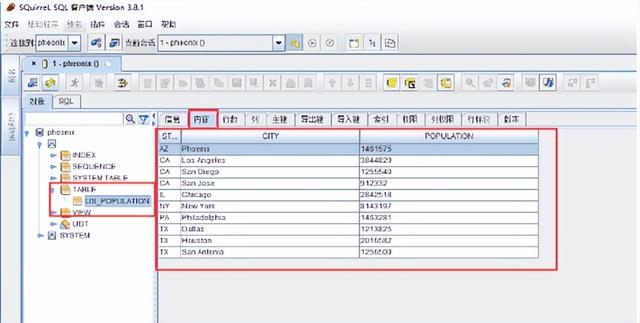
查询数据:

结语:本篇文章介绍到此结束,码字不易,如果本篇文章对您有所帮助,麻烦动动发财的小手,三连点赞,关注,转发支持下。


